- The paper presents a modular reference architecture that standardizes comparison of various parameter-efficient finetuning techniques for large language models.
- The framework categorizes techniques based on intra- and inter-connectivity, parameter adaptation, and integration, enabling systematic efficiency and performance assessments.
- Performance results indicate methods like LoRA offer lower parameter complexity and robust task performance, guiding optimal fine-tuning strategies.
PEFT-Ref: A Modular Approach to Parameter-Efficient Finetuning Techniques
The paper "PEFT-Ref: A Modular Reference Architecture and Typology for Parameter-Efficient Finetuning Techniques" (2304.12410) introduces PEFT-Ref, a cohesive framework that offers a standardized methodology for comparing parameter-efficient finetuning (PEFT) techniques used with large pretrained LLMs (PLMs). By introducing a modular reference architecture and a typology, the paper aims to elucidate the structural and functional differences among various PEFT methods, thereby illuminating their relative advantages in terms of efficiency and performance across diverse tasks.
The Emergence of Parameter-Efficient Finetuning Techniques
Recent advances in PLMs like GPT-3 [https://doi.org/10.48550/arxiv.([2005.14165](/papers/2005.14165))], OPT [https://doi.org/10.48550/arxiv.([2205.01068](/papers/2205.01068))], BLOOM [https://doi.org/10.48550/arxiv.([2211.05100](/papers/2211.05100))], and PaLM [https://doi.org/10.48550/arxiv.([2204.02311](/papers/2204.02311))] have led to substantial increases in model sizes, reaching billions of parameters. Although these models exhibit improved performance across several NLP tasks, they come with increased training and deployment costs, which have significant financial and environmental implications [Strubell et al., 2019]. Parameter-efficient finetuning (PEFT) seeks to mitigate these issues by limiting the number of parameters retrained and reducing storage requirements by adapting only small model components for specific downstream tasks.
As the diversity of PEFT techniques grows [Gao et al., 2021; Tan et al., 2022], comparing them according to efficiency and performance becomes increasingly complex. PEFT-Ref addresses this challenge by establishing a standardized framework that enables systematic comparison and evaluation of different PEFT techniques.
The PEFT-Ref Framework
Modular PEFT Reference Architecture
The PEFT-Ref framework introduces a diagrammatic modular reference architecture that identifies slots and interactions within the standard Transformer architecture where PEFT modules can be inserted and trained.
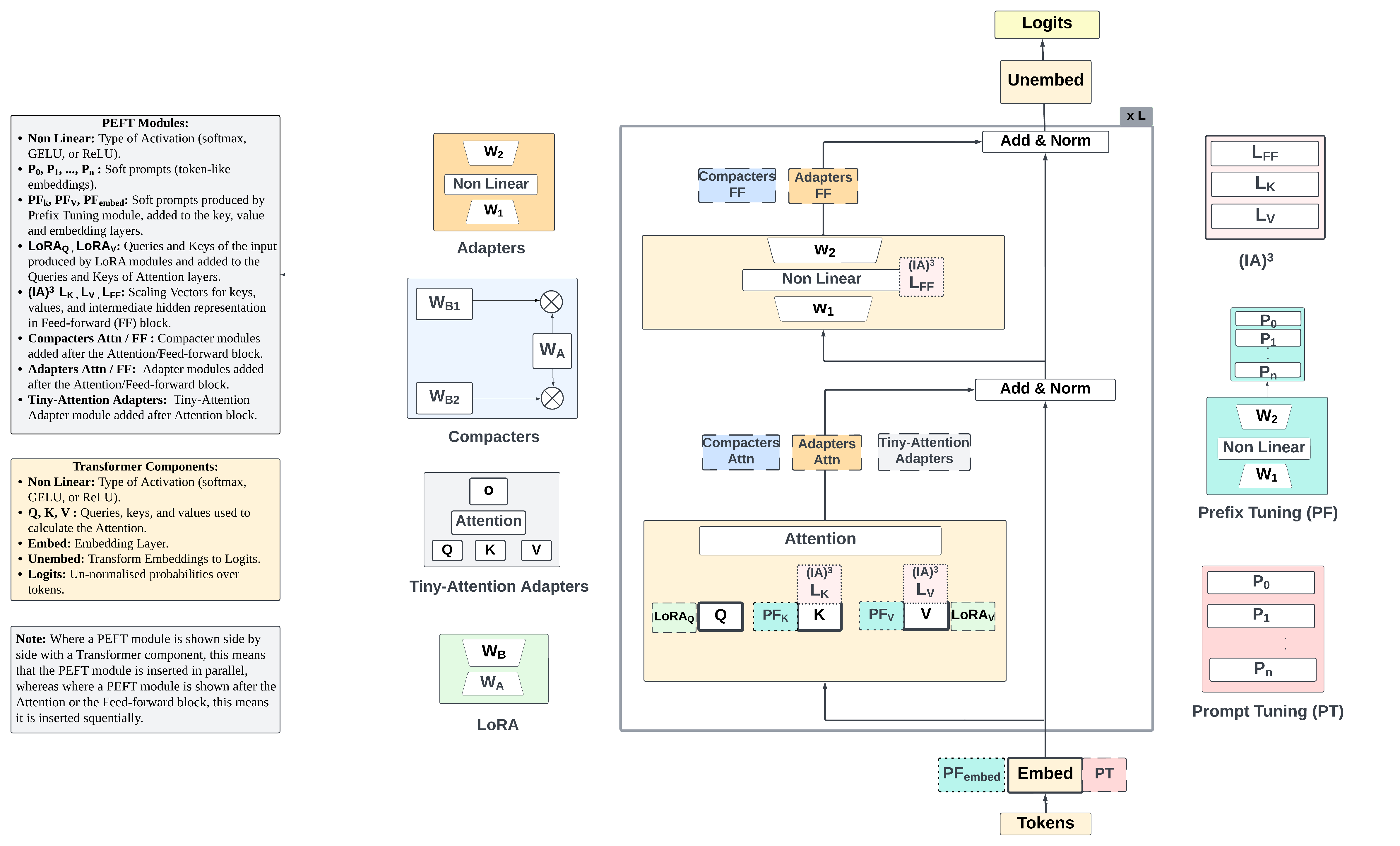
Figure 1: Modular PEFT reference architecture showing PLM components (central box), different types of PEFT modules (left and right of center), and insertion slots of PEFT modules (dashed boxes in PLM box) and interactions between PEFT modules and PLM components (see also legend on the left).
The architecture facilitates clear visualization of module composition interfaces and describes intra-connectivity (within the module), inter-connectivity (with the PLM), adapted parameters, parameter sharing/tying, input type, insertion form, number of insertions, integration form, and workspace.
Typology of Modular Properties
PEFT-Ref characterizes each technique based on several modular properties:
- Intra-connectivity: Describes the internal connectivity of a PEFT module, either dense or sparse, impacting its modularity.
- Inter-connectivity: Defines how PEFT modules connect to the PLM, with fixed or dynamic connections, influencing modularity.
- Parameters Adapted: Whether parameters are added or existing weights are reparameterised.
- Parameter Sharing/Tying: Potential regularization and inductive biases from sharing or tying parameters.
- Input Type: The form of input a PEFT module receives, which can be hidden representations, data, or weights.
- Insertion Form: Describes whether the module is inserted in a sequential or parallel manner.
- Number of Insertions: Indicates the extent to which PEFT modules are inserted into the PLM architecture.
- Integration Form: How PEFT module outputs integrate into the PLM, with various addition types.
- Workspace: The area of the PLM where the PEFT modules interact, crucial for overall information processing.
Characterisation of PEFT Techniques with PEFT-Ref
The PEFT-Ref framework characterizes seven prominent PEFT techniques, providing a means to comprehensively log their differences and commonalities.
Prompt Tuning and Prefix Tuning
Prompt Tuning (PT) [Lester et al., 2021] and Prefix Tuning [Li & Liang, 2021] have low complexity, inserting token-like embeddings only into the embedding and attention key/value layers, respectively. PT operates through concatenation while PF utilises gated additions.
LoRA
LoRA [DBLP:journals/corr/abs-2106-09685] leverages low-rank adapters for parameter efficiency by reparameterising attention layers with linear projection layers. Implementation involves parallel insertion, scaled addition for integration, and collaboration with Attention layers.
Adapters and Variants
Adapters [Houlsby et al., 2019] are modular and effective, integrating sequentially via direct addition in the feed-forward (FFN) and attention layers. Variants such as Compacters [NEURIPS2021_081be9fd] exploit parameter sharing through reparameterised layers for enhanced efficiency.
Efficiency and performance metrics underscore critical distinctions observed in PEFT techniques.
Efficiency
Efficiency enhancements differ, with LoRA exhibiting lower parameter complexity per layer at 2x(2dh dm). Table 2 demonstrates how the modular properties influence efficiency through varying module complexity.
LoRA consistently outperforms others, particularly in complex tasks such as question answering, owing to its innovative reparameterization approach using low-rank matrices.
Conclusion
PEFT-Ref offers a standardized modular reference architecture and typology that aids in analyzing PEFT techniques' structural and functional attributes. By doing so, it significantly contributes to a coherent comparative analysis across methodologies and informs task-specific PEFT technique selection. Future work could focus on expanding PEFT methods to improve parameter sharing, increase convergence stability, and explore new workspaces not covered by current PEFT techniques. The framework also lays potential foundations for further research into developing more robust and efficient parameter-efficient finetuning paradigms.
The implications for AI include streamlining the customization of large PLMs for specific downstream applications, conserving computational resources, and promoting reuse, all while maintaining high performance.
Figure 1: Modular PEFT reference architecture showing PLM components (central box), different types of PEFT modules (left and right of center), and insertion slots of PEFT modules (dashed boxes in PLM box) and interactions between PEFT modules and PLM components.