- The paper introduces MBIB, a unified benchmark for media bias detection that aggregates nine tasks and curated datasets.
- It leverages Transformer models like T5 and BART to evaluate performance using micro and macro F1-scores across multiple bias types.
- The study highlights research gaps and paves the way for future benchmarks featuring multi-lingual datasets and expanded bias dimensions.
The paper "Introducing MBIB – the first Media Bias Identification Benchmark Task and Dataset Collection" introduces MBIB, a comprehensive benchmark for assessing media bias across various types. MBIB aggregates linguistic, cognitive, political, and additional bias types, presenting a unified framework for evaluating media bias detection techniques using state-of-the-art Transformer models.
Benchmark Overview and Dataset Curation
MBIB is engineered to address shortcomings in existing research where media bias detection is often isolated to specific bias types without allowing for standardized model comparisons. This benchmark introduces nine tasks with associated datasets allowing the simultaneous evaluation of multiple media bias types. During the dataset curation phase, the authors reviewed 115 datasets and ultimately selected 22, ensuring they met criteria such as accessibility, language, size, and label quality.

Figure 1: The dataset collection and selection process.
The selected datasets cover various forms of bias, offering rich representations of tasks such as linguistic bias, cognitive bias, and political bias. The imbalance in dataset availability across tasks highlights research gaps, such as a lack of extensive resources for reporting-level context bias, underscoring future opportunities for comprehensive corpus development.
Methodology and Implementation
The MBIB benchmark clusters tasks pertinent to media bias, analyzing individual datasets within each task to derive a wider perspective on media bias categorization. Each dataset underwent preprocessing to ensure uniformity in label representation, enabling binary classification where necessary, and comprehensive format alignment for consistency across tasks.
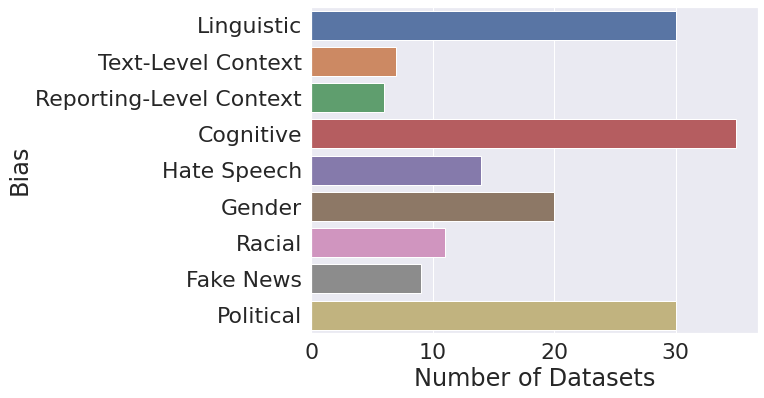
Figure 2: Dataset distribution over MBIB tasks.
Standard Transformer models, including T5 and BART, were applied to assess the benchmark, revealing their varying capabilities in task handling, particularly identifying easier vs. more complex bias types such as gender or political biases versus cognitive biases. Metrics such as micro and macro average F1-scores were utilized to present task-based performance evaluations comprehensively.
Upon deploying five baseline models—ConvBERT, Bart, RoBERTa-Twitter, ELECTRA, and GPT-2—performance variances across tasks were analyzed, unveiling distinctive strengths among models for specific biases. The investigation identified no singular model being superior for all tasks, hence illustrating the merit of task diversity and dataset amalgamation in MBIB.
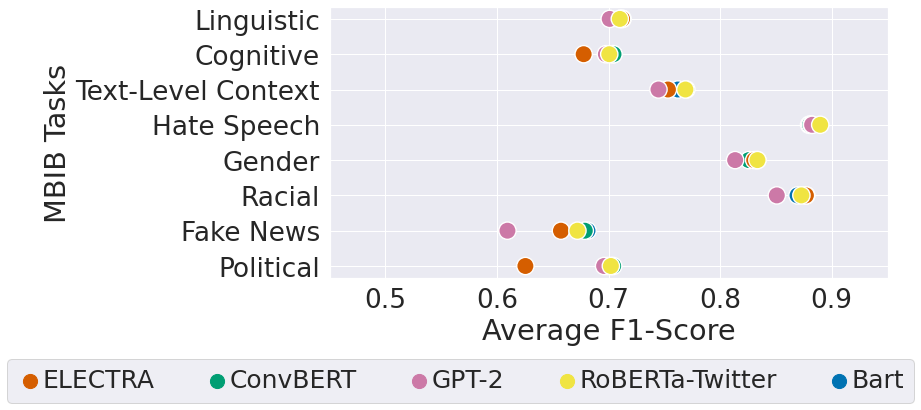
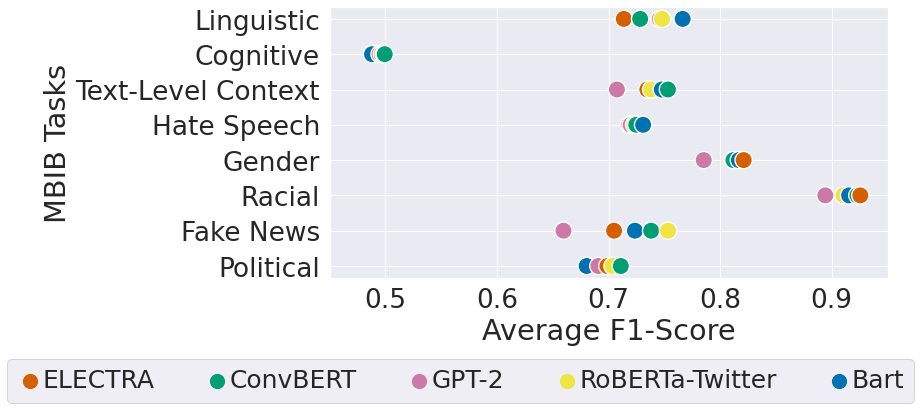
Figure 3: F1-scores comparison across baseline models by task showing micro-average performance.
Micro and macro-average evaluations offered insights into a model's capacity to generalize across different datasets within a task, tangibly reflecting on dataset size and detail level's effects on performance. Beyond reinforcing the significance of dataset breadth, the analysis advocates for the potential enhancements in results with refined approaches.
Implications and Future Directions
The introduction of MBIB ties into the broader vision for enhanced media bias scholarly work. Apart from steering the development of sophisticated, generalizable models, MBIB paves the way for future benchmarks inclusive of multi-lingual datasets and extended bias dimensions such as framing or sentiment analysis. As media consumption channels evolve, so does the necessity for robust, nuanced methodologies capable of tackling multifaceted biases within news propagations.
Conclusion
MBIB stands as a pivotal contribution to media bias research, setting a robust framework for the development of innovative bias detection models and fostering greater understanding of media content manipulation's ramifications. Through continuous dataset expansion and task refinement, MBIB is foundational for progress in unveiling the intricacies of media bias in an increasingly digital-first world.