- The paper presents a novel benchmark leveraging MIMIC-IV data to create an extensive ICD coding dataset for automated multilabel classification.
- It utilizes both ICD-9 and ICD-10 codes with standardized train, validation, and test splits to ensure reproducibility.
- Empirical results show that advanced models like PLM-ICD and MSMN outperform others, highlighting the benchmark's potential to advance automated medical coding.
Mimic-IV-ICD: A New Benchmark for eXtreme MultiLabel Classification
Introduction
The paper "Mimic-IV-ICD: A new benchmark for eXtreme MultiLabel Classification" (2304.13998) explores the creation of benchmark datasets for ICD coding using the latest MIMIC-IV electronic health records (EHR) dataset. This study addresses the necessity for standardized benchmarks to enable reproducibility and facilitate the comparison of various automated ICD coding models. The benchmarks utilize MIMIC-IV data to include both ICD-9 and ICD-10 codes, expanding upon previous MIMIC-III datasets with a higher volume of data points and codes. The study provides open-source solutions, allowing researchers to replicate data processing and model experiments, fostering advancement in automated ICD coding.
Data Processing and Dataset Creation
The data processing pipeline begins with compiling discharge notes combined with corresponding ICD codes from MIMIC-IV, using patient identifiers to track medical records throughout hospital stays. The resulting dataset is considerably larger than previous MIMIC-III datasets, encompassing 209,359 admissions with ICD-9 codes and 122,317 admissions with ICD-10 codes. The dataset splits into training, validation, and test sets following established procedures to ensure non-overlapping patient sets, providing a solid foundation for model training and evaluation.
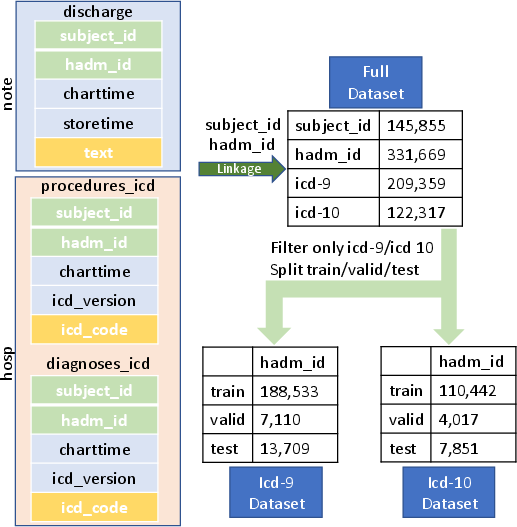
Figure 1: The workflow of data processing from raw data.
A notable aspect of MIMIC-IV is its inclusion of both ICD-9 and ICD-10 codes, which enriches the dataset with a broader spectrum of codes and supports more complex, multilabel classification tasks. Moreover, the paper presents settings where specific codes are filtered to create reduced datasets focusing on the most frequent labels, akin to prior MIMIC-III benchmarks.
Benchmarking and Empirical Study
The study evaluates several baseline methods for ICD coding, leveraging models like CAML, LAAT, JointLAAT, MSMN, and PLM-ICD. Each model represents a different approach to encoding and understanding clinical text. MSMN and PLM-ICD, which include external knowledge or data, generally outperform other models. The comprehensive empirical study compares model performance across full-label and top-50 label settings, utilizing metrics such as macro and micro AUC and F1 scores, precision@k, which vary by dataset and model configuration.
Results and Ablation Studies
The results underscore the complexity of the task, with performance metrics reflecting the diverse methodologies employed. Models like PLM-ICD and MSMN reveal superior capabilities in capturing semantic relationships and predicting codes with multiple synonyms. Ablation studies highlight the impact of frequency of code appearances on model performance, demonstrating marked differences in macro and micro F1 scores across frequency groups and providing insights into the models' abilities to learn labels with differing distributions.
(Figure 2)
Figure 2: Comparison of Micro-F1 scores between PLM-ICD and MSMN on labels with different Mimic-IV-ICD-9-Full test set frequencies.
(Figure 3)
Figure 3: Comparison of Macro-F1 scores between PLM-ICD and MSMN on labels with different Mimic-IV-ICD-9-Full test set frequencies.
Implications and Future Work
This paper contributes to the field by setting a new benchmark for ICD code prediction, offering tools and datasets for further exploration in automated coding systems. The potential for future work includes the expansion of benchmarks with additional baseline models and features like drug codes or vitals. Moreover, the integration of ICD codes with predictive models for readmission, triage, or mortality prediction tasks can further enhance healthcare outcomes and resource allocation efficiency.
Conclusion
The establishment of MIMIC-IV benchmarks for ICD coding plays a pivotal role in accelerating research in the domain of automated medical coding and predictive modeling. By openly sharing the data processing pipeline, the study invites collaboration and innovation, ultimately aiming to improve healthcare delivery and diagnostic precision through refined machine learning models. The findings point to the continuing evolution of ICD coding strategies, advocating for ongoing expansion and refinement to harness the wealth of data available in EHR systems.