- The paper introduces SuperICL, a framework that integrates fine-tuned small models with LLMs using confidence scores to enhance decision-making.
- The method, evaluated on benchmarks like GLUE and XNLI, consistently outperforms standard In-Context Learning and standalone fine-tuning models.
- The study demonstrates that combining small plug-in models with large LLMs resolves context length issues and improves robustness in supervised NLP tasks.
Super In-Context Learning: An Evaluation of Small Models as Plug-Ins for LLMs
Introduction
The paper "Small Models are Valuable Plug-ins for LLMs" proposes a novel approach named Super In-Context Learning (SuperICL), which aims to leverage locally fine-tuned smaller models as plug-ins for black-box LLMs, like GPT-3.5. This method intends to address the challenges of limited context length in In-Context Learning (ICL) and the computational constraints related to tuning large models.
Super In-Context Learning Framework
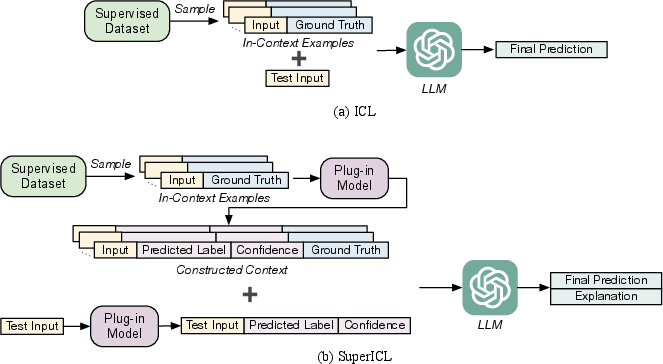
Figure 1: The workflow of ICL and SuperICL. There are three steps in SuperICL: (1) A context is constructed by randomly sampling from the training data and incorporating the plug-in model's predictions, including predicted labels and their corresponding confidence scores. (2) The test input is concatenated after the context, with the plug-in model's prediction attached. (3) Finally, a LLM generates the final prediction along with an optional explanation.
SuperICL operates by first fine-tuning a smaller pre-trained model like RoBERTa on task-specific data, which acts as a plug-in to the larger LLM. This plug-in provides predictions with confidence scores that are used to build a context for the LLM. The context includes randomly sampled in-context examples enriched by the plug-in's confidence-informed predictions. This setup facilitates the LLM in making more accurate decisions by balancing between its predictions and the guidance from the smaller model.
Experimental Evaluation
The method was tested on standard NLP benchmarks, including GLUE for text classification and XNLI for cross-lingual tasks. The results showed that SuperICL consistently outperforms standard ICL and standalone fine-tuned models across most datasets. Notably, SuperICL improved accuracy in tasks like MNLI, SST-2, and MRPC by focusing on the confidence scores from the plug-in model, which informed the LLM's decision to override or accept predictions.
Analysis and Ablation Studies
The paper includes a thorough ablation study evaluating the roles of context construction, confidence integration, and plug-in model prediction. SuperICL's design allowed it to achieve superior performance with fewer in-context examples, highlighting the robustness and efficiency of its approach. Additionally, the analysis of adversarial robustness using the ANLI dataset indicated that while SuperICL shows enhanced resistance to adversarial inputs compared to smaller models alone, its effectiveness hinges on the integrity of the plug-in model.
Implications and Future Work
The proposed method presents a promising direction for leveraging the strengths of both large and small models. Practically, this approach can democratize the use of LLMs by making them accessible even when direct tuning or weight access is restricted. Future research could explore automated, adaptive fine-tuning strategies and extensions to generative tasks, enhancing the applicability and robustness of SuperICL across diverse domains.
Conclusion
This study reveals that incorporating small LLMs as plug-ins enhances the efficiency and applicability of LLMs on supervised tasks. SuperICL illustrates significant advancements in handling model accessibility issues and achieving superior performance metrics, paving the way for future explorations of hybrid model architectures in NLP.

