- The paper introduces a novel dataset that significantly enhances multi-step logical reasoning through instruction tuning.
- It employs diverse datasets and GPT-4 generated chain-of-thought rationales to improve LLM performance on logical and general tasks.
- The methodology and experimental results demonstrate a promising pathway for developing AI systems capable of complex reasoning.
LogiCoT: Logical Chain-of-Thought Instruction-Tuning
This essay provides an expert analysis of the paper "LogiCoT: Logical Chain-of-Thought Instruction Tuning" (2305.12147). The paper focuses on enhancing the logical reasoning capabilities of LLMs using a dataset tailored for instruction tuning. The central objective of this research is to address the existing gap in models' abilities to perform multi-step logical reasoning tasks, and the authors introduce a new dataset designed to facilitate this goal through techniques rooted in chain-of-thought (CoT) prompting.
Introduction and Motivation
In recent advancements in NLP, LLMs such as GPT-4 have demonstrated profound capabilities in understanding and generating human-like text. However, while these models are adept at many general tasks with CoT reasoning, their proficiency in logical reasoning, particularly when it involves complex, multi-step inferences, remains limited. The current instruction tuning approaches, exemplified by initiatives like Alpaca and Vicuna, primarily enable models to perform effectively on general tasks but do not adequately address scenarios requiring detailed logical reasoning.
The research highlights the necessity for instruction tuning datasets that enable LLMs to improve their logical reasoning capabilities significantly. By leveraging GPT-4's inherent CoT abilities, the paper presents LogiCoT, a dataset aimed at embedding logical reasoning into the instruction tuning paradigm. This dataset aspires to serve as a comprehensive tool for models to acquire both symbolic reasoning and multi-step logical reasoning skills.
Methodology: Dataset Construction and Instruction Types
The dataset construction methodology is multi-faceted, involving the use of existing logical reasoning datasets such as LogicInference, EntailmentBank, FOLIO, ReClor, and LogiQA. These datasets are instrumental in formulating diverse logical reasoning challenges. LogiCoT's construction leverages GPT-4's generative capabilities to produce high-quality CoT rationales.
Seminal Data Selection
The choice of datasets is strategic, with each contributing unique aspects of logical reasoning. LogicInference provides formal logical structures, while EntailmentBank offers entailment trees crucial for understanding logical sequences. FOLIO is notable for its first-order logic annotations, which are automatically verified, ensuring high-quality logical tasks.
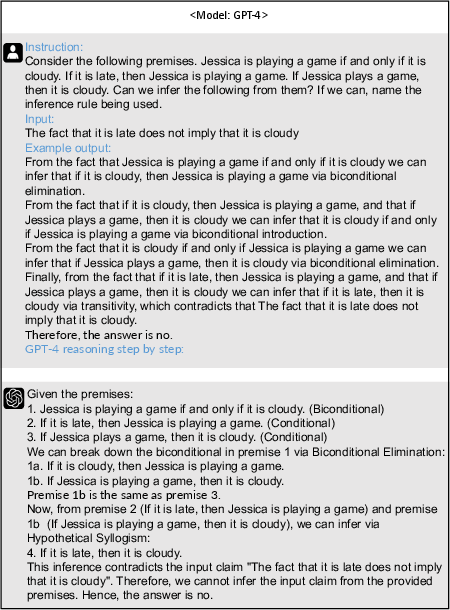
Figure 1: A showcase of using GPT-4 and existing inference data to generate CoT rationales for logical reasoning.
Instruction Types
The dataset accommodates diverse instruction types categorized under general inference and multi-choice reading comprehension tasks. These are crafted to hone different aspects of logical reasoning:
- General Inference Tasks: These include translating natural language to logical formulas and performing single-step and chained inferences.
- Reading Comprehension Tasks: These tasks are designed to assess the model's ability to analyze and interpret complex textual information, determining logical coherence and validity.
Experimental Results
The experimental framework focuses on fine-tuning a LLaMA-7b model using the LogiCoT dataset. The tuned model, dubbed LLaMA-7b-logicot, is evaluated against logical reasoning (LogiEval benchmark) and general language understanding tasks (MMLU benchmark).
LLaMA-7b-logicot achieves superior results on all logical reasoning tasks compared to the baseline and leading open-source models like LLaMA-30b-supercot and Falcon-40b-instruct. The improvements are particularly pronounced in multi-choice reading comprehension tasks, demonstrating the model's enhanced ability to process and reason through complex scenarios.
In the MMLU benchmark, the tuned model displays a marked increase in performance across various domains, with particularly high gains in business and computer science. The results indicate the model's success in generalizing logical reasoning skills to broader topics beyond those it was explicitly trained on.
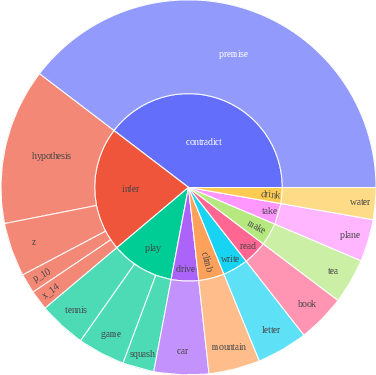
Figure 2: Root verb-noun pairs of GPT-4 generated responses, illustrating diverse logical inference scenarios.
Implications and Future Directions
The research reveals the potential of instruction-tuning datasets like LogiCoT to significantly enhance the logical reasoning capabilities of LLMs. These advancements can drive the development of more robust AI systems capable of handling complex reasoning tasks with a higher degree of accuracy and coherence.
Future research could explore the integration of LogiCoT-like datasets into dialogue-oriented LLMs, such as Alpaca, to further enhance their logical reasoning proficiency within conversational contexts. Additionally, expanding the dataset to cover more languages and reasoning scenarios could facilitate the creation of even more versatile and powerful AI models.
Conclusion
LogiCoT represents a pivotal step forward in the instruction tuning of LLMs for logical reasoning. By harnessing GPT-4's CoT capabilities, the dataset provides a comprehensive resource for training models in complex reasoning tasks. The resultant improvements in both logical and general task performance underscore the efficacy of this approach, positioning LogiCoT as a valuable asset for advancing the field of AI-driven logical reasoning.