Self-supervised representations in speech-based depression detection
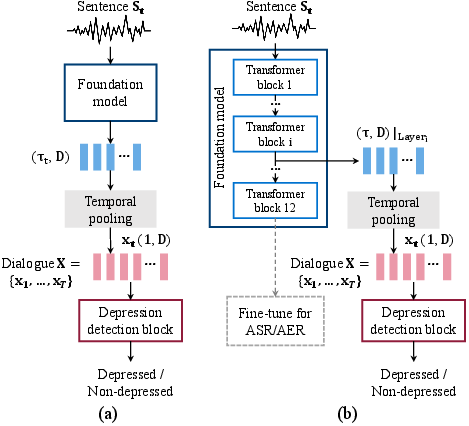
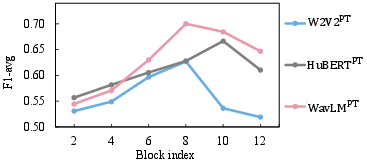
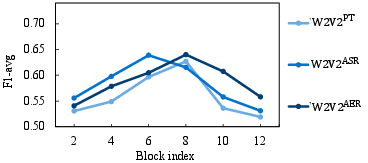
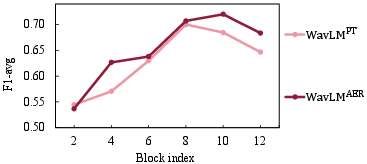
Abstract: This paper proposes handling training data sparsity in speech-based automatic depression detection (SDD) using foundation models pre-trained with self-supervised learning (SSL). An analysis of SSL representations derived from different layers of pre-trained foundation models is first presented for SDD, which provides insight to suitable indicator for depression detection. Knowledge transfer is then performed from automatic speech recognition (ASR) and emotion recognition to SDD by fine-tuning the foundation models. Results show that the uses of oracle and ASR transcriptions yield similar SDD performance when the hidden representations of the ASR model is incorporated along with the ASR textual information. By integrating representations from multiple foundation models, state-of-the-art SDD results based on real ASR were achieved on the DAIC-WOZ dataset.
- World Health Organization, “Depression,” https://www.who.int/news-room/fact-sheets/detail/depression, Accessed: August 15, 2022.
- “A review of depression and suicide risk assessment using speech analysis,” Speech Communication, vol. 71, pp. 10–49, 2015.
- “Critical analysis of the impact of glottal features in the classification of clinical depression in speech,” IEEE Transactions on Biomedical Engineering, vol. 55, no. 1, pp. 96–107, 2007.
- “Detection of clinical depression in adolescents’ speech during family interactions,” IEEE Transactions on Biomedical Engineering, vol. 58, no. 3, pp. 574–586, 2010.
- “Multichannel weighted speech classification system for prediction of major depression in adolescents,” IEEE Transactions on Biomedical Engineering, vol. 60, no. 2, pp. 497–506, 2012.
- “Detecting depression using vocal, facial and semantic communication cues,” in Proc. ACM MM, Amsterdam, 2016.
- “Detecting depression with audio/text sequence modeling of interviews.,” in Proc. Interspeech, Hyderabad, 2018.
- “On the opportunities and risks of foundation models,” arXiv preprint arXiv:2108.07258, 2021.
- “SUPERB: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021.
- “Wav2Vec 2.0: A framework for self-supervised learning of speech representations,” in Proc. NeurIPS, Conference held virtually, 2020.
- “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021.
- “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- “BigSSL: Exploring the frontier of large-scale semi-supervised learning for automatic speech recognition,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1519–1532, 2022.
- “Speech emotion recognition using self-supervised features,” in Proc. ICASSP, Singapore, 2022.
- “RoBERTa: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
- “SimSensei Kiosk: A virtual human interviewer for healthcare decision support,” in Proc. AAMAS, Paris, 2014.
- “Automatic depression detection: An emotional audio-textual corpus and a gru/bilstm-based model,” in Proc. ICASSP, Singapore, 2022.
- “Topic modeling based multi-modal depression detection,” in Proc. ACM MM, Mountain View, 2017.
- “A Step Towards Preserving Speakers’ Identity While Detecting Depression Via Speaker Disentanglement,” in Proc. Interspeech, Incheon, 2022.
- “Climate and weather: Inspecting depression detection via emotion recognition,” in Proc. ICASSP, Singapore, 2022.
- “Layer-wise analysis of a self-supervised speech representation model,” in Proc. ASRU, Cartagena, 2021.
- “Tandem Multitask Training of Speaker Diarisation and Speech Recognition for Meeting Transcription,” in Proc. Interspeech, Incheon, 2022.
- R. Lotfian and C. Busso, “Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings,” IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471–483, 2019.
- “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proc. ICML, Pittsburgh, 2006.
- “Text-based depression detection on sparse data,” arXiv preprint arXiv:1904.05154, 2019.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

