- The paper introduces MULTISIM, a unified benchmark featuring 27 datasets and over 1.7 million sentence pairs for non-English text simplification.
- It demonstrates that multilingual training and few-shot prompting with models like mT5 and BLOOM significantly boost performance in low-resource languages.
- Experiments show that semantic similarity-based example selection outperforms random sampling, achieving near-human simplification quality across diverse languages.
Revisiting non-English Text Simplification: A Unified Multilingual Benchmark
Introduction
The paper "Revisiting non-English Text Simplification: A Unified Multilingual Benchmark" addresses a significant gap in the field of automatic text simplification (ATS) by introducing the MULTISIM benchmark. This benchmark comprises 27 datasets across 12 languages, offering a valuable resource for improving multilingual ATS models and evaluation metrics. The paper’s central focus is on enhancing text simplification for non-English languages, which has been historically under-represented compared to English.
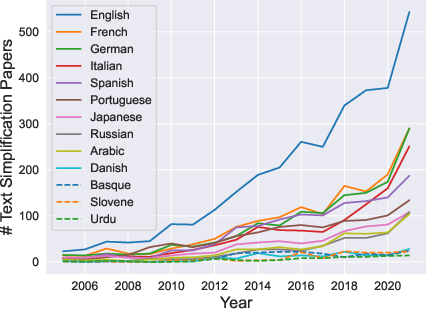
Figure 1: Papers published each year with content related to text simplification and a specific language according to Google Scholar. The quantity of English text simplification work vastly exceeds all other languages.
The MULTISIM Benchmark
MULTISIM is significant in its scope, covering languages that vary widely in terms of resource availability. This benchmark includes over 1.7 million sentence pairs and is designed to evaluate and foster the development of robust multilingual simplification models. The paper notes the utility of multilingual pre-trained models like mT5 and BLOOM in achieving effective cross-lingual transfer and few-shot performance, even for low-resource languages.
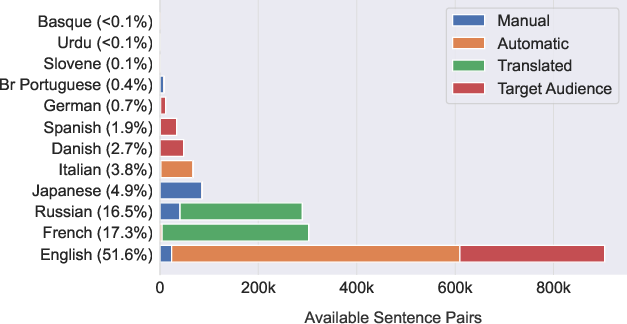
Figure 2: Data availability for text simplification in all languages partitioned on collection strategy. Despite only including three of the most common English datasets, English resources outnumber all other language resources combined.
Experimental Insights
Experiments on the MULTISIM benchmark reveal that multilingual training significantly enhances performance in non-English text simplification tasks. The zero-shot cross-lingual transfer is particularly effective from Russian datasets to other languages, demonstrating the importance of domain and script compatibility. Few-shot prompting using large models like BLOOM also shows promise by outperforming fine-tuned models in low-resource scenarios.
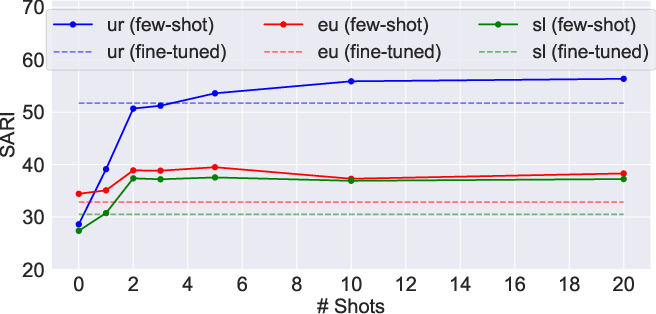
Figure 3: Semantic similarity fewshot performance in low-resource languages. Fewshot prompting achieves higher SARI than mt5 finetuned.
The comparative analysis between semantic similarity-based example selection and random sampling for few-shot settings underscores a consistent advantage for semantic approaches. This superior performance manifests across different datasets, highlighting the method’s robustness and potential for practical applications.
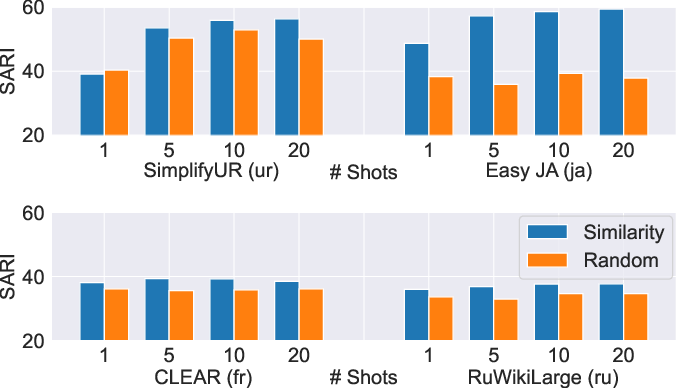
Figure 4: Semantic similarity vs random sampling few-shot performance on four diverse datasets. Semantic similarity consistently scores above random sampling.
Human Evaluation
Human evaluation aligns with automatic metrics, with models trained on large-scale data outperforming others. Few-shot prompting shows near-human simplification levels in several languages, reinforcing its applicability across varying linguistic contexts.
Conclusion
The paper makes a substantive contribution by releasing MULTISIM, advancing the field of non-English ATS. This benchmark facilitates comprehensive multilingual model evaluation and encourages future research in enhancing simplification across diverse languages. The insights into few-shot and zero-shot learning expand possibilities for deploying text simplification technologies in languages with limited resources.
Implications and Future Directions
MULTISIM’s introduction has implications for advancing ATS models capable of handling linguistic diversity. Future work could explore realigning automated corpora for improved accuracy and extending human evaluations to ensure simplifications meet users’ comprehension needs across different demographics.
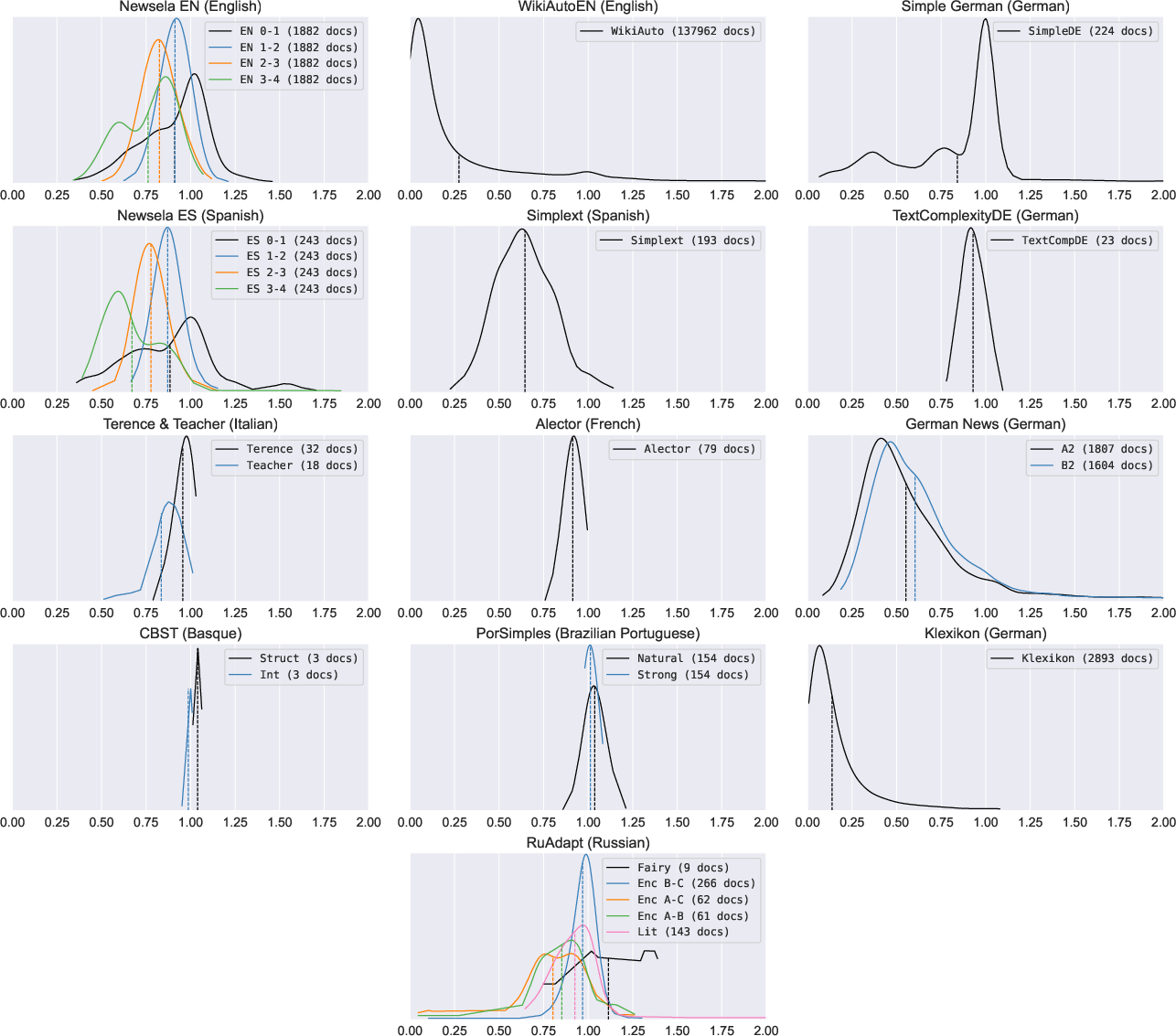
Figure 5: Distribution of document-level compression ratio for document-aligned corpora, smoothed by Gaussian kernel density estimation. Means are marked by dashed lines.
In summary, this paper lays a foundational stone for future endeavors in making complex information accessible worldwide, breaking down language barriers through innovative ATS solutions.