- The paper introduces ProlificDreamer, which improves text-to-3D generation by modeling 3D parameters as random variables via Variational Score Distillation.
- The methodology leverages a particle-based variational framework and Wasserstein gradient flow to simulate differential equations for realistic and diverse scene generation.
- Key experiments show that ProlificDreamer overcomes SDS issues, delivering higher fidelity, richer textures, and greater diversity for applications in gaming, animation, and VR.
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
Introduction
The paper introduces ProlificDreamer, a novel framework for high-fidelity and diverse text-to-3D generation using Variational Score Distillation (VSD). Traditional Score Distillation Sampling (SDS) methods often suffer from issues such as over-saturation, over-smoothing, and low diversity. ProlificDreamer addresses these limitations by modeling 3D parameters as random variables and utilizing a particle-based variational framework, which allows for improved diversity and quality in text-to-3D generation.



Figure 1: Text-to-3D samples generated by ProlificDreamer.
Variational Score Distillation (VSD)
VSD is central to ProlificDreamer's approach, optimizing a distribution of 3D scenes rather than a single point. It employs particle-based variational inference, maintaining a set of 3D parameters (particles) to represent the distribution. The method involves simulating an ODE with a principled gradient-based update rule derived via the Wasserstein gradient flow. This ensures convergence to the desired distribution, allowing for realistic and diverse 3D scene generation.
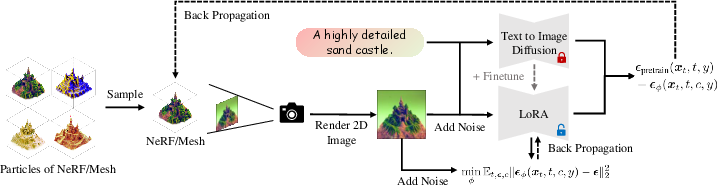
Figure 2: Overview of VSD, demonstrating the rendering and score computation process.
Technical Advancements
Compared to SDS, VSD utilizes a variational distribution approach that naturally accommodates multiple plausible 3D scene representations for a given prompt. The ability to use different CFG weights effectively addresses the limitations of SDS, enabling realistic renderings at normal CFG settings. The introduction of various design improvements, such as high rendering resolution, annealed time schedules, and scene initialization, also plays a significant role in the higher fidelity and complexity of the generated 3D content.




Figure 3: Samples demonstrating the superior realism and details generated by VSD compared to SDS.
Evaluation and Results
Experiments highlight that ProlificDreamer generates superior 3D outputs in terms of fidelity and diversity when compared to existing SDS-based methods. The study not only verifies the robustness of VSD in different settings but also illustrates the potential for generating complex scenes with rich structures and textures.



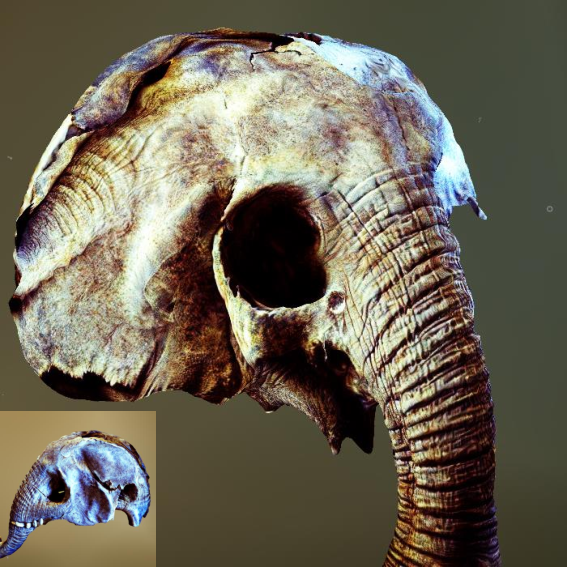
Figure 4: Ablation study showing improvements in NeRF generation with proposed enhancements.
Conclusion
ProlificDreamer significantly enhances text-to-3D generation through the application of VSD, addressing previous limitations in SDS approaches. Its ability to produce high-fidelity, diverse, and complex 3D scenes opens new avenues for applications across various domains such as gaming, animation, and virtual reality. Future work could focus on accelerating the generation process and further refining the integration of scene understanding and camera positioning for even more detailed scene renderings.