- The paper proposes a novel approach that decomposes motion priors for individual joints using independent GRUs, reducing model complexity.
- It leverages adversarial training, the SMPL model, and isometric constraints to significantly lower PA-MPJPE and acceleration errors.
- Results demonstrate enhanced pose estimation accuracy and robustness under occlusion, paving the way for further advances in motion synthesis.
Decomposed Human Motion Prior for Video Pose Estimation via Adversarial Training
Introduction
The paper "Decomposed Human Motion Prior for Video Pose Estimation via Adversarial Training" presents an innovative approach to human pose estimation from video sequences by leveraging decomposed motion priors. Unlike conventional methods that treat motion priors holistically, this research advocates for decomposing the motion of individual joints to reduce complexity and enhance model learning capabilities. The proposed method significantly lowers the PA-MPJPE and acceleration error compared to existing techniques and demonstrates robust performance even on in-the-wild datasets.
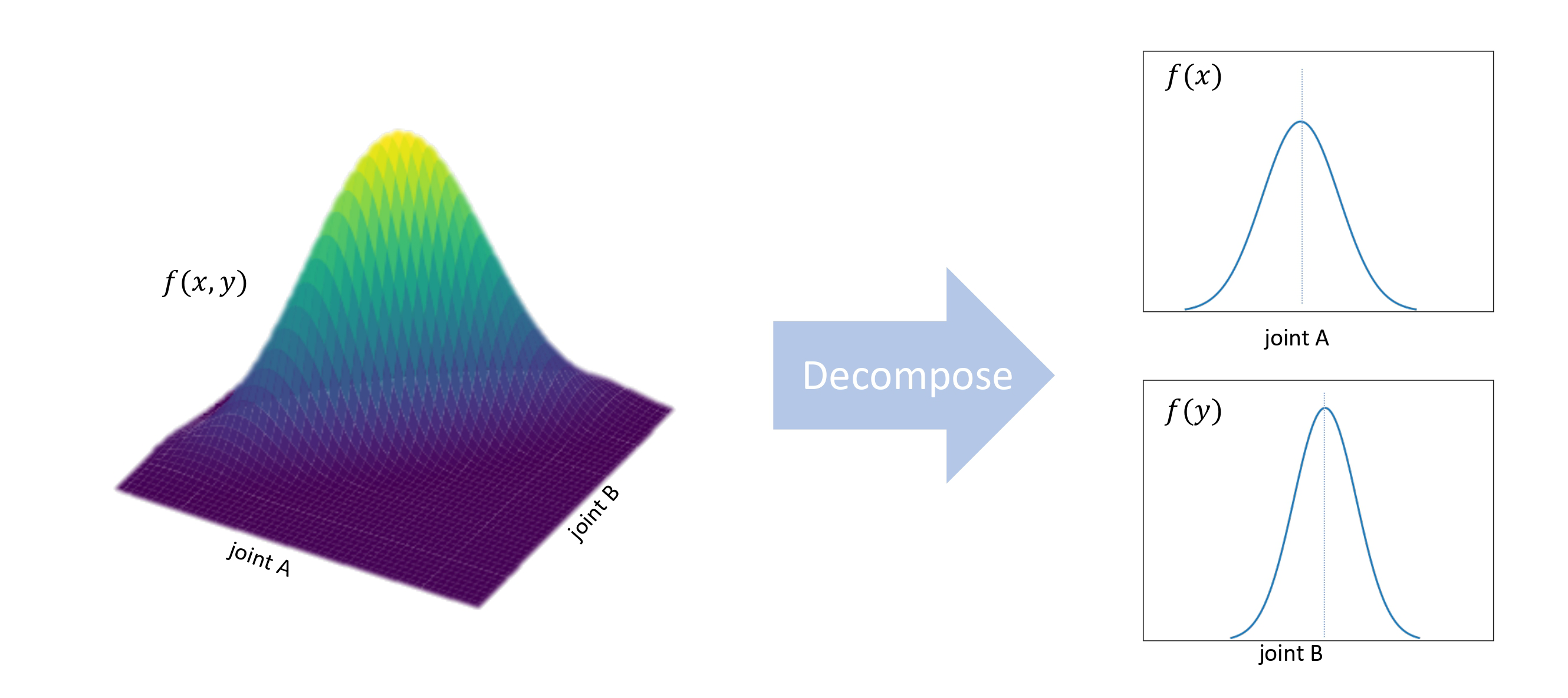
Figure 1: The motion distribution of the holistic body can be viewed as a joint distribution of the motion distributions of each joint. Decomposing the relationship of joints will decrease the complexity of motion prior distribution.
Methodology
Preliminaries
The method centers on the SMPL model, a widely accepted parametric model in pose estimation. SMPL utilizes pose parameters θ, comprising rotation vectors for 24 joints, and shape parameters β, to describe human body vertices under specific poses. The objective is to regress sequences of these SMPL parameters from RGB videos.
Modeling and Combining Decomposed Motion Prior
This approach models joint motion priors individually for each joint, thereby reducing the complexity inherent in holistic motion modeling. The architecture involves independent GRUs for learning motion priors of each joint, facilitating the formation of a comprehensive temporal motion sequence. Adversarial training conditions the system to distinguish between real and generated motion samples, enforcing prediction quality. A backbone network extracts features for joint-specific GRUs, while a discriminator ensures reliable motion synthesis.
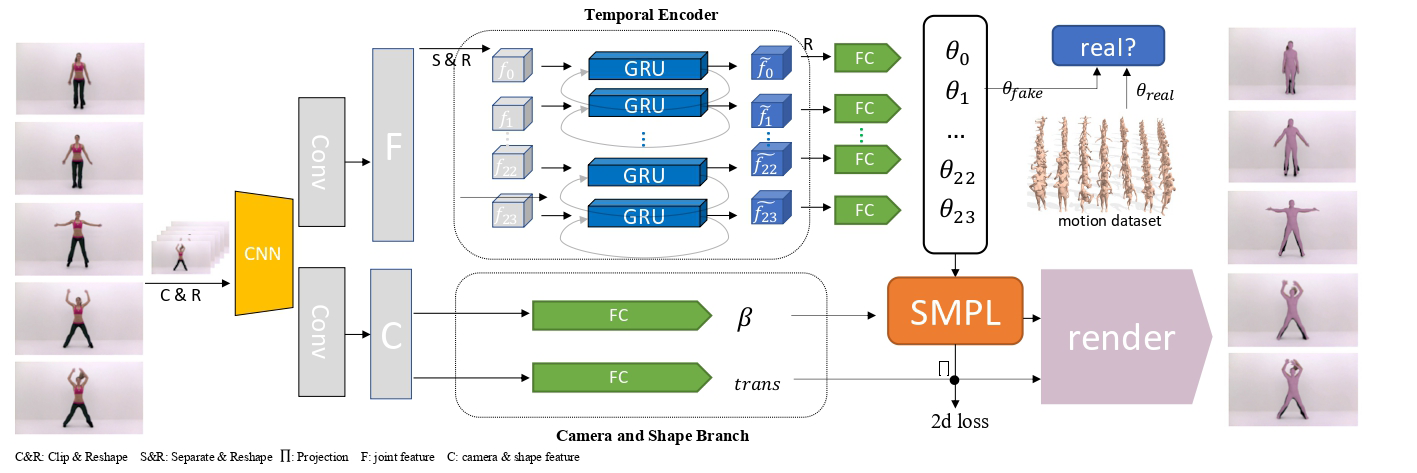
Figure 2: The figure illustrates that the partial backbone initially extracts features for each joint, followed by the use of independent GRUs designed to learn the motion prior of each joint, thereby forming the holistic motion prior.
Isometric Constraints
Projecting 3D keypoints onto a 2D image plane involves sophisticated parameter estimation to reconcile temporal information with spatial accuracy. The loss function incorporates MSE losses across dimensions, alongside adversarial and regularization components. The novel regularization loss combats overfitting toward overly smooth predictions, balancing accuracy and smoothness.
Experiments and Results
The approach is rigorously tested on datasets such as MPII3D and 3DPW, with metrics including PA-MPJPE emphasizing precision and smoothness. This method significantly enhances accuracy, achieving reductions in PA-MPJPE and acceleration error compared to baseline methods such as VIBE. Visualization on standard datasets illustrates smooth and consistent pose predictions even in occluded scenes.
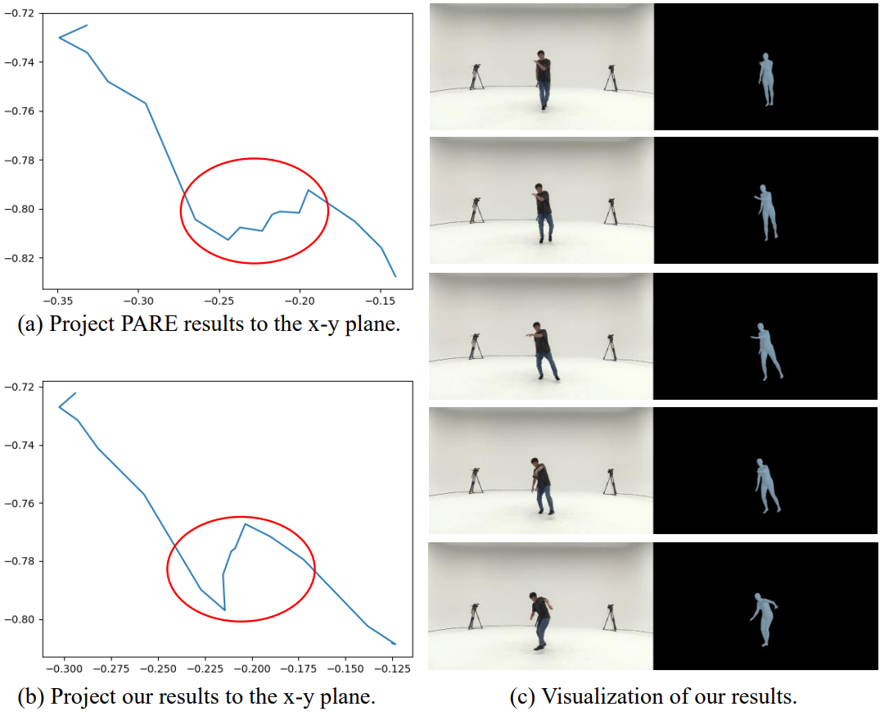
Figure 3: Visualize our results on the hm3.6 dataset.

Figure 4: Even in the presence of occlusion, our method can still infer the correct human pose using temporal information and motion prior.
Implications and Future Work
The decomposition strategy proposed in this paper not only achieves robust pose estimation but also sets a precedent for future work in motion synthesis and action recognition. By simplifying the learning trajectory of neural networks to concentrate on joint-level dynamics, this research paves the way for advancements in applications demanding high precision in motion modeling. Additionally, the regularization methodology introduced could be adapted to enhance other temporal prediction tasks, offering practical utility across a spectrum of AI applications.
Conclusion
The decomposed motion prior strategy delineated in this study represents a notable advancement in video-based human pose estimation, yielding superior results through simplified learning processes and novel regularization techniques. This method not only improves accuracy and smoothness but also inspires future enhancements in related fields. The synergy of adversarial training and motion decomposition presents a formidable framework promising impactful developments in AI-driven motion analysis and synthesis.