- The paper demonstrates that random subsets of neurons can retain nearly full-layer performance, with 20% of neurons achieving within 5% accuracy on tasks like CIFAR10.
- It analyzes the role of architecture, dataset size, and adversarial training in enhancing redundancy, highlighting that wider layers and larger datasets increase this effect.
- The study underscores the potential for efficient transfer learning and computational savings, while also addressing fairness concerns in task performance.
Diffused Redundancy in Pre-trained Representations
Introduction
The paper "Diffused Redundancy in Pre-trained Representations" (2306.00183) investigates the phenomenon of how features are encoded in pre-trained neural network representations. These networks, particularly CNNs and Transformers trained on datasets like ImageNet, exhibit a peculiar property termed as diffuse redundancy. The essential idea is that random subsets of neurons from a layer can perform nearly as well as the entire layer on various downstream tasks, suggesting a redundancy inherent in the trained representations.
Methodology and Results
Diffused Redundancy Hypothesis
The authors propose the hypothesis that within a layer of a pre-trained neural network, there exists a substantial overlap of information among neurons such that many random subsets can suffice for downstream task performance:
- Example Demonstration: With 20% of neurons randomly selected from the penultimate layer of a ResNet50 pre-trained on ImageNet1K, classification accuracy on CIFAR10 remains within 5% of using the full layer.
- Empirical Testing: Various architectures and pre-training setups (including adversarial training) were evaluated against standard datasets such as CIFAR10, CIFAR100, Oxford-IIIT-Pets, and Flowers.
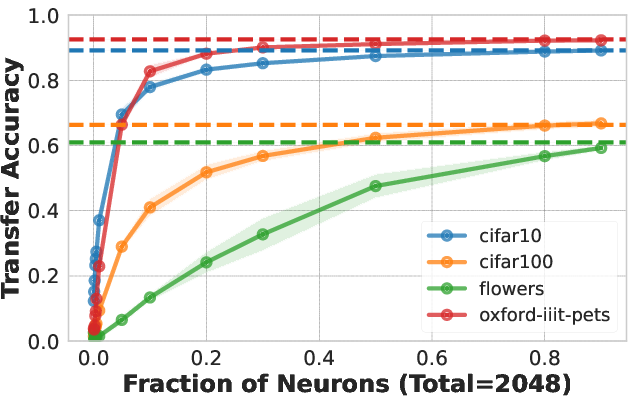
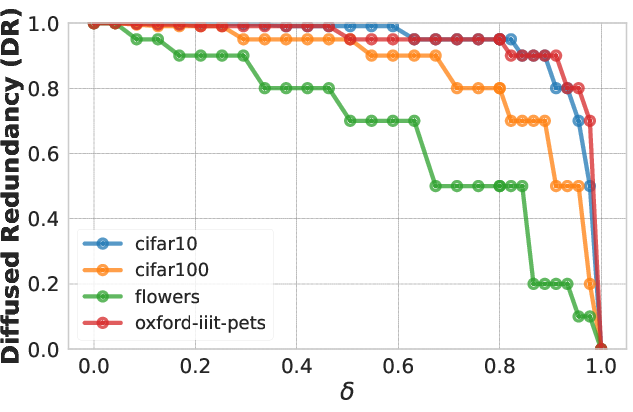
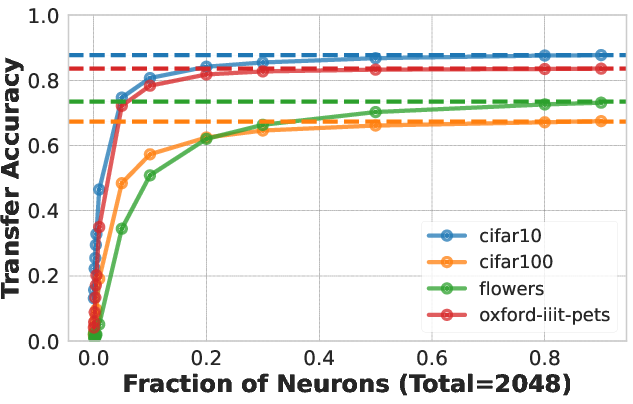
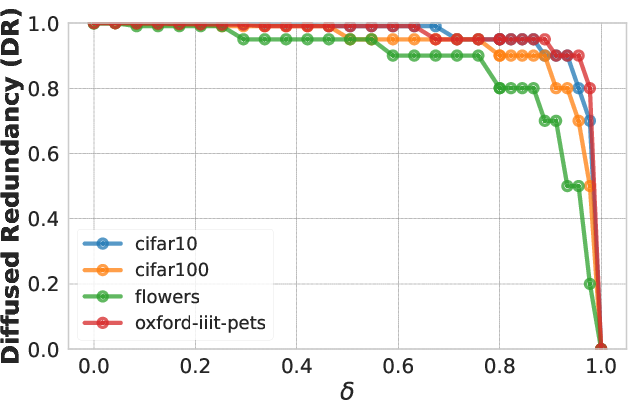
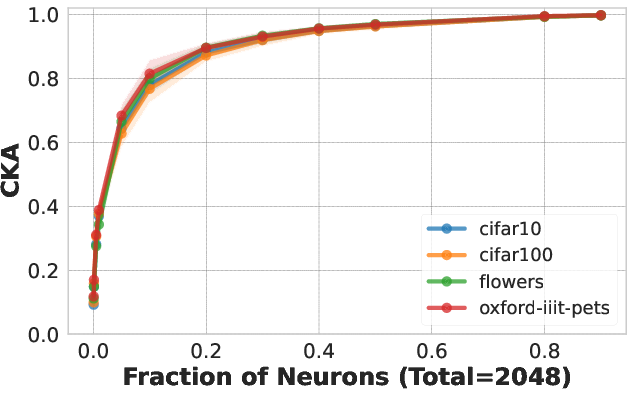
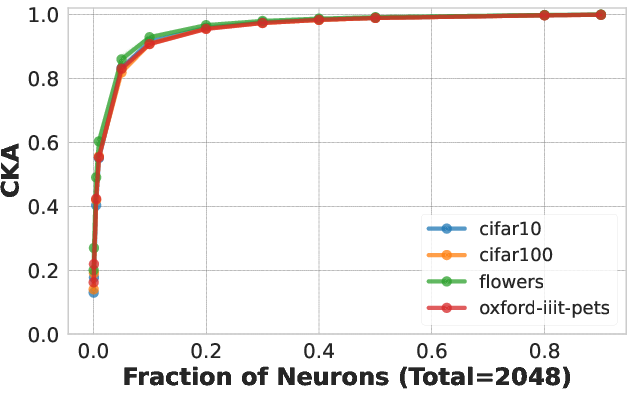
Figure 1: Downstream accuracy of random neuron subsets compared to full layer usages.
Factors Influencing Redundancy
Several factors were analyzed for their influence on the degree of diffused redundancy:
Architecture
Among different architectures tested (ResNet variants, VGG, ViT), each displayed varying degrees of diffuse redundancy. Notably, architectures with wider layers exhibited more redundancy.
Pre-training Dataset and Loss Functions
The redundancy was more apparent when networks were trained on larger datasets like ImageNet-21k compared to ImageNet-1k. Moreover, adversarially trained models demonstrated a significant increase in redundant features compared to standard trained models.
Downstream Tasks
The task-specific nature of redundancy indicates a Pareto frontier—the minimal subset of neurons necessary matches task performance closely. Notably, the redundancy's impact varied depending on the complexity of the downstream task.
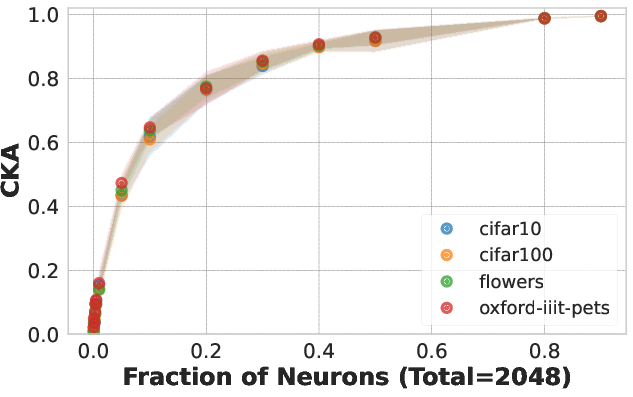
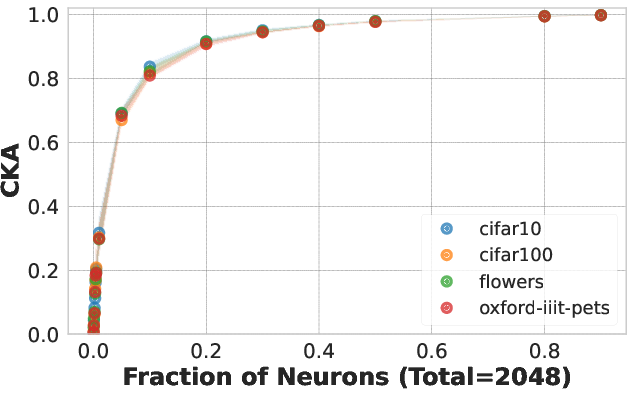
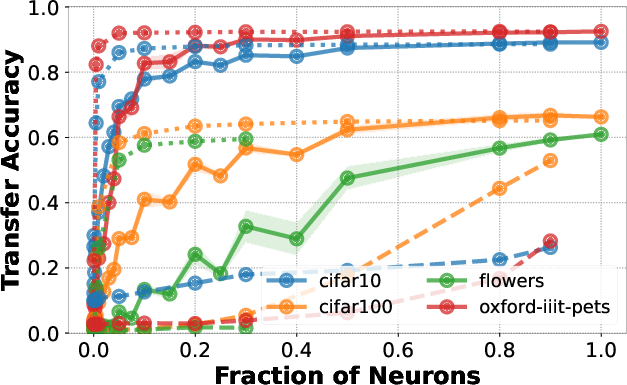
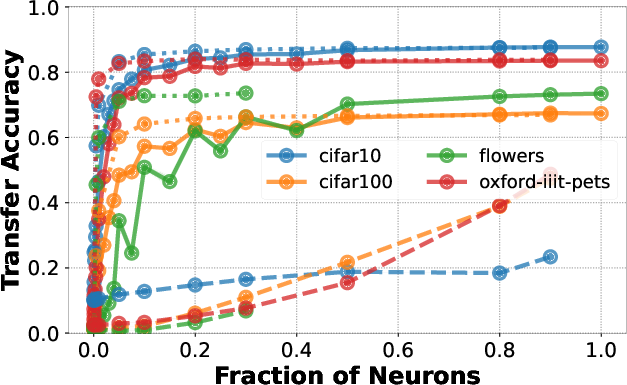
Figure 2: CKA measurements showing similarity between random neuron subsets and their whole.
Theoretical Insights and Comparisons
Comparison with PCA
The paper draws insight by comparing random neuron selections with projections onto a reduced number of principal components (PCA). It was observed that the performance of subsets of neurons quickly aligns with that of top PCA components, reinforcing the hypothesis that redundancy captures essential feature variations.
Structured vs. Natural Redundancy
The structured redundancy intentionally induced by techniques like Matryoshka Representation Learning (MRL) contrasts with naturally occurring diffuse redundancy. While MRL optimizations are explicit, the natural redundancy phenomena as observed occur without purposeful restructuring, still maintaining high task efficacy.

Figure 3: Effects of dropout regularization level on redundancy phenomena.
Implications and Future Directions
Efficient Transfer Learning
The identified redundancy suggests potential for more computationally efficient transfer learning applications, wherein substantial portions of model capacity can be preserved without significant accuracy losses. This could lead to reduced computation and faster adaptation in resource-constrained environments.
Fairness Considerations
Exploiting this redundancy might result in uneven performance drops across different task classes. Potential fairness implications arise, as certain classes might disproportionately suffer when neuron subsets are utilized, hence necessitating careful consideration in practical applications of such optimization techniques.
Conclusion
This study uncovers a critical aspect of pre-trained neural networks, highlighting diffused redundancy as a distinct characteristic of wide-layered models. While promising in terms of improved computational efficiency, careful implementation must consider potential variations in fairness across task categories. Future research might focus on better understanding the optimal bounds and methods to harness redundancy without unintended side effects.