- The paper demonstrates that single-layer transformers simulate a single step of preconditioned gradient descent using learned attention mechanisms.
- The paper reveals that multi-layer architectures execute multiple adaptive descent steps by aligning key loss landscape points with iterative optimization.
- The paper validates its framework with empirical tests that mirror theoretical predictions, highlighting transformer dynamics similar to classical optimizers.
Transformers Implementing Preconditioned Gradient Descent in In-Context Learning
Introduction
"In-context learning" (ICL) is a capability of LLMs, notably transformers, enabling them to understand and respond to tasks by leveraging examples within given prompts without explicit parameter updates. This property underpins many modern advancements in models like GPT-3 and beyond. Researchers have postulated that transformers, through their complex architecture involving self-attention mechanisms, might inherently function as algorithmic simulators capable of implementing iterative optimization methods like gradient descent (2306.00297).
Core Contributions
The paper explores whether transformers can inherently learn to execute algorithms like preconditioned gradient descent by training over random instances of linear regression. Specifically, the work bridges the expressive capacity of transformers with their potential algorithmic learning capabilities via non-convex optimization.
- Single-Layer Transformers: The analysis demonstrates that in a single-layer setting, transformers are capable of learning to perform a single iteration of a preconditioned gradient descent. The preconditioning matrix adapts not only to the distribution of input data but also to variance challenges caused by limited data (Figure 1).
- Multi-Layer Settings: In multi-layer architectures, critical points within the loss landscape of the transformer can be interpreted as the execution of multiple steps of preconditioned gradient descent. These transformations are adaptive and allow efficient problem-solving by alternately adjusting to data-specific conditions.
- Validation and Experiments: Theoretical insights are matched with empirical validations where trained transformers resemble behaviorally the described transformations in practice, supporting the notion that transformers are learning complex optimization methods intrinsically.
Theoretical Framework and Methodology
Through rigorous mathematical proofs, the paper constructs a theoretical framework wherein the transformer architecture is analyzed under the lens of linear regression tasks. The attention mechanism, stripped of its conventional softmax part for simplification, is primarily analyzed on its linear transformations and iterative processes. Major propositions include:
- Expressivity as Preconditioned Descent: For a single-layer transformer's global minimizer, the paper derives a condition where the transformer acts akin to a single step of preconditioned gradient descent by employing matrices like Q0 and P0 strategically set to optimize learning heuristics (Figure 2).
- Attention Dynamics and Algorithm Learning: Multi-layer transformers can be fine-tuned via specific sparsity constraints, revealing configurations that allow the transformer to mimic preconditioned adaptive algorithms seen in practical neural optimization techniques.
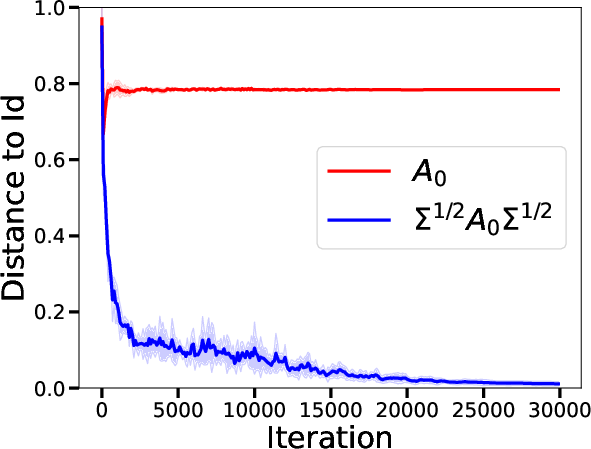
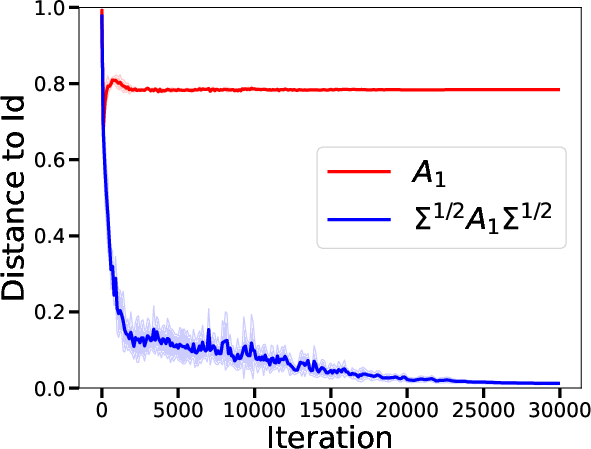
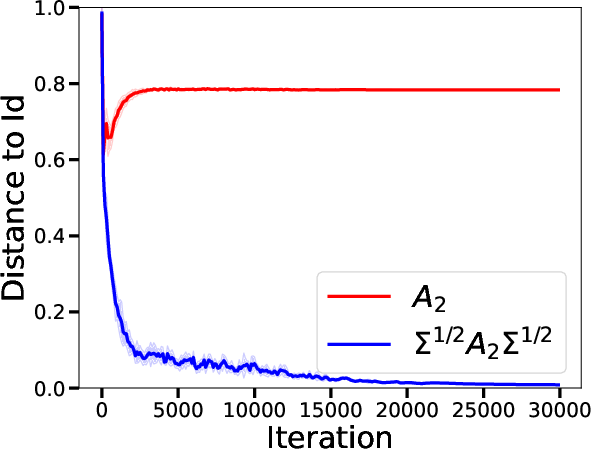
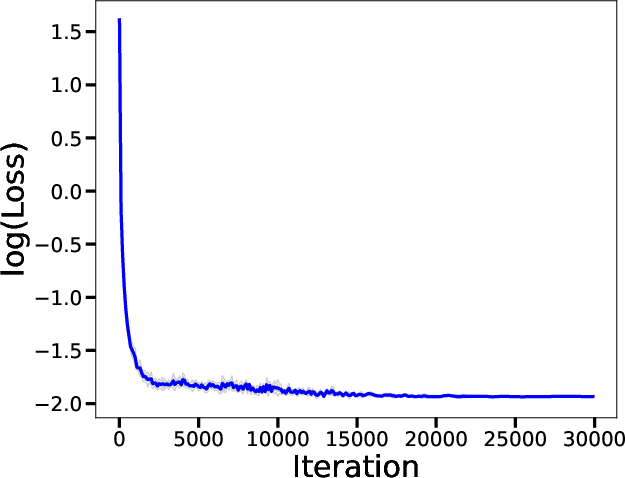
Figure 2: Visualization of the adjustment dynamics in the covariance influenced by the learned matrices in a single iteration.
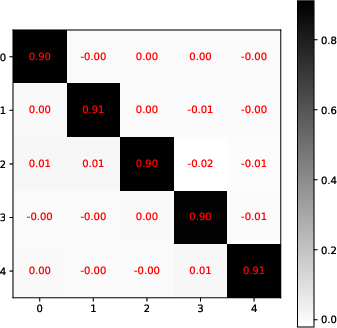
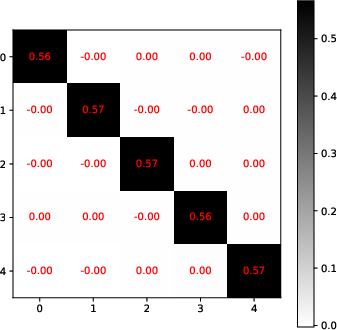
Figure 1: Visualization of optimized weight matrices in the learned attention schema, indicating an adherence to theoretical predictions of adaptive preconditioning.
Empirical tests validate the theoretical structure by deploying transformers in simulated environments and comparing their adaptiveness and convergence behavior with standard algorithms such as classical and preconditioned gradient descent methods.
Conclusion
This study establishes a foundational understanding of how transformers, under certain parametric configurations, can not only simulate but effectively learn optimization algorithms in-context through training on random linear regression datasets. Insights derived from this study consolidate the understanding of transformer dynamics as inherently capable of adaptive learning akin to sophisticated numerical optimization methods. Future research is encouraged to expand on this groundwork by exploring nonlinear contexts and different transformer scales, possibly extending these findings to broader machine learning paradigms.