- The paper introduces a framework defining safety, fairness, and metric equity to mitigate harmful generative AI outputs.
- It employs empirical methods, including input/output filters and machine learning classifiers, to quantify and reduce explicit or biased content.
- Experiments on diffusion-generated images demonstrate that tailored content moderation effectively blocks harmful content and addresses group disparities.
Safety and Fairness for Content Moderation in Generative Models
The paper "Safety and Fairness for Content Moderation in Generative Models" (2306.06135) presents a comprehensive framework for ensuring responsible content moderation in the deployment of generative AI technologies, specifically focusing on text-to-image generation. This paper tackles the challenges of mitigating harmful content that can emerge from generative models, defining the constructs of safety, fairness, and metric equity, and providing empirical methodologies for their quantification.
Conceptual Framework
Definitions and Constructs
The paper introduces a theoretical framework defining key principles necessary for content moderation: safety, fairness, and metric equity. Safety is concerned with reducing harmful outputs, both accidental and intentional, that might arise from generative models. Fairness encompasses considerations of representational harms and biases that models might perpetuate, particularly through stereotypes and unequal treatment across diverse groups. Metric equity involves ensuring that generative models perform equivalently well across all sociodemographic groups, mitigating quality-of-service disparities.
Safety in Generative AI
Safety for generative AI models is characterized by the proportion of outputs that are potentially harmful. The authors suggest using safety metrics such as the percentage of unsafe outputs relative to the total number of generated outputs. Empirical safety thresholds can be calculated to filter model outputs, with illustrative categories like sexually explicit content, graphic violence, and hateful content. Importantly, defining safety takes into consideration social power dynamics, ensuring that marginalized communities are better protected against algorithmic harms.
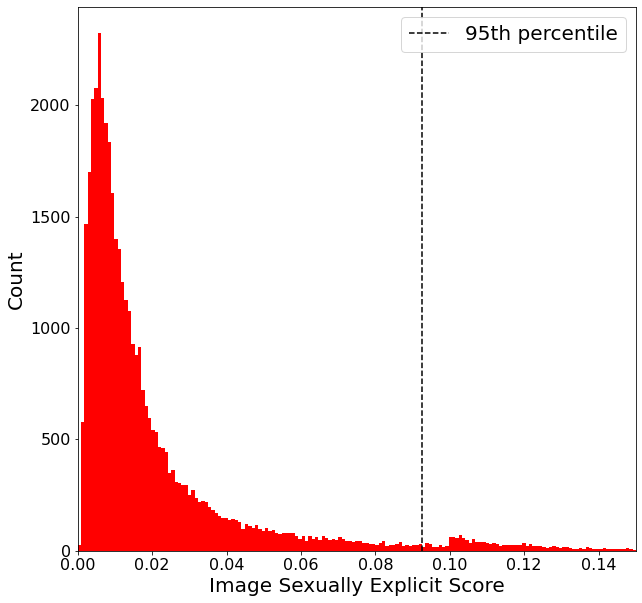
Figure 1: Sexually explicit histogram.
Methodology for Empirical Measurement
Content Moderation Decisions
The research articulates content moderation decisions through filters and measurement strategies based on pre-defined harms. Three primary methods are explored: training data mitigations, in-model controls, and input/output filters. Among these, the focus is on the agility and effectiveness of input and output filters, given their implementation feasibility in production environments.
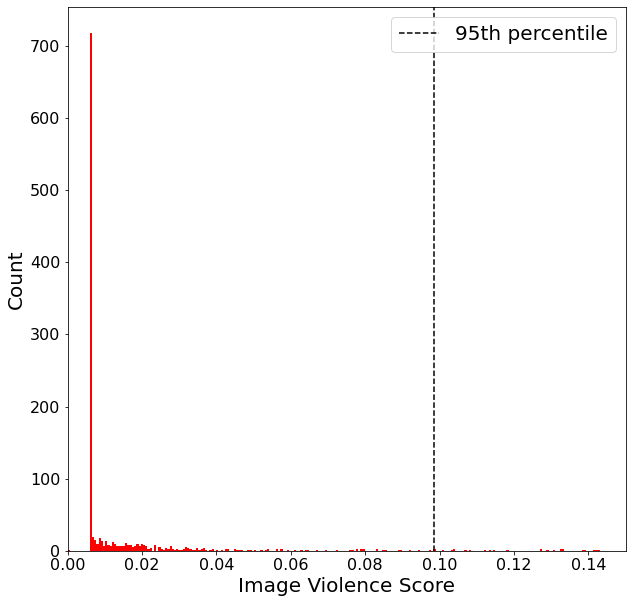
Figure 2: Violence histogram.
Experiments and Analysis
Experiments are conducted using a dataset of 40,904 images generated by a diffusion model in response to 10,226 prompts, half of which comprise adversarial prompts crafted to induce harmful content. The study applies machine learning classifiers to detect content categories such as sexual explicity, violence, and hate, defining thresholds to moderate these outputs effectively.
Analysis of safety focuses on histograms of explicit and violent content, demonstrating the impact of dataset filtering in reducing the model’s ability to generate harmful imagery. The authors derive thresholds, such as blocking the top 5% most explicit content, while fairness is assessed based on diversity, equal treatment, stereotype amplification, and counterfactual fairness. Discrepancies in gender representation and stereotype adherence are quantified using metrics like entropy and normalized pointwise mutual information (nPMI).
Practical Implications and Future Directions
The paper emphasizes that content moderation strategies must be uniquely tailored to the context and use case of the generative AI being deployed. Safety and fairness metrics provide a quantitative basis for evidence-driven moderation policies. The analysis serves as a caution against applying one-size-fits-all solutions, instead advocating for tailored moderation criteria that account for diverse societal impacts.
In conclusion, this framework and accompanying methodologies offer a structured approach to responsible deployment of generative models, with an emphasis on mitigating harms across safety and fairness dimensions. Continuing work could extend these frameworks to other generative modalities and explore mixed-methods approaches integrating human insights with quantitative assessments, thereby enhancing the robustness and societal alignment of AI systems.