- The paper introduces SimpleMapping, a real-time mapping system that fuses sparse VIO with a deep multi-view stereo network to achieve state-of-the-art dense 3D reconstruction.
- The system integrates ORB-SLAM3 for 6-DoF pose estimation with a dual-branch CNN for single-view depth completion, leveraging sparse depth priors from VIO.
- Experimental results on datasets like EuRoC and ETH3D demonstrate improved depth prediction accuracy and efficiency, underscoring its potential for AR and VR applications.
SimpleMapping: Real-Time Visual-Inertial Dense Mapping with Deep Multi-View Stereo
This paper introduces SimpleMapping, a real-time visual-inertial dense mapping system that leverages a sparse point aided multi-view stereo neural network (SPA-MVSNet) to achieve high-quality 3D mesh reconstruction from monocular images and IMU data. The system integrates a feature-based VIO for pose estimation with a deep learning approach to enhance the accuracy and robustness of dense depth prediction. The paper demonstrates that incorporating sparse 3D points obtained from traditional feature-based VIO systems can significantly improve the performance of MVS networks.
System Architecture and Implementation
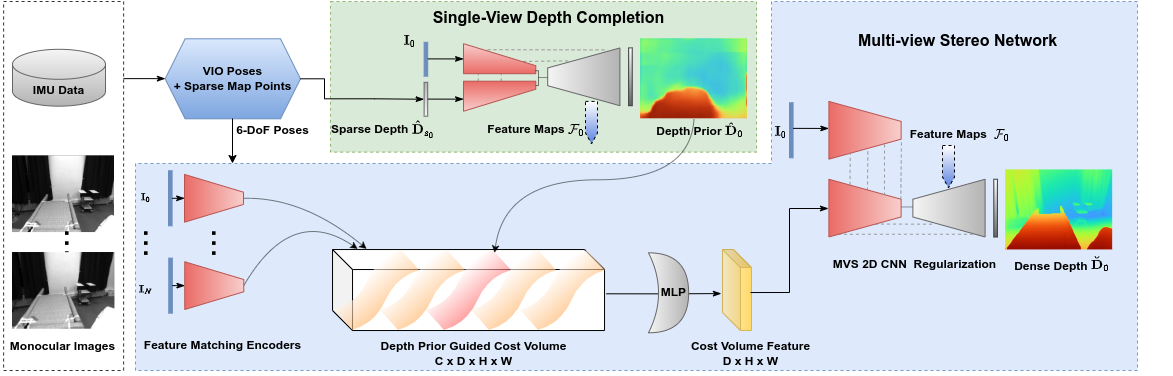
Figure 1: System overview of SimpleMapping.
The SimpleMapping system comprises two primary components: VIO pose tracking using ORB-SLAM3 [ORBSLAM3_TRO] and a dense mapping module. (Figure 1) The VIO component estimates 6-DoF camera poses and generates a sparse 3D point cloud. The dense mapping component utilizes the SPA-MVSNet to infer high-quality dense depth maps from selected keyframes. These depth maps are then fused into a global TSDF grid map for coherent 3D reconstruction. The system employs parallel processing to enable real-time performance.
Sparse Visual-Inertial Odometry
The VIO system is based on ORB-SLAM3 [ORBSLAM3_TRO], which provides robust 6-DoF pose estimations. The system selects keyframes based on covisibility and pose distance criteria to balance triangulation quality and view frustum overlap. The sparse depth maps are generated by projecting 3D sparse VIO points onto the image plane, with filtering based on depth and reprojection error thresholds to remove outliers.
Sparse Points-Aided Single-View Depth Completion
The SPA-MVSNet leverages sparse depth points from the VIO to improve the accuracy of dense depth prediction. A lightweight CNN is used to perform single-view depth completion on the reference image and its corresponding sparse depth map. The depth completion network consists of two encoder branches for the RGB image and the sparse depth map, respectively, followed by a decoder that predicts a dense depth map. The network is trained using a combination of depth reconstruction loss and smoothness loss. The loss function is defined as:
L=ωrecLrec+ωsmLsm,
where Lrec is the depth reconstruction loss and Lsm is the smoothness loss.
Multi-View Stereo with Dense Depth Prior
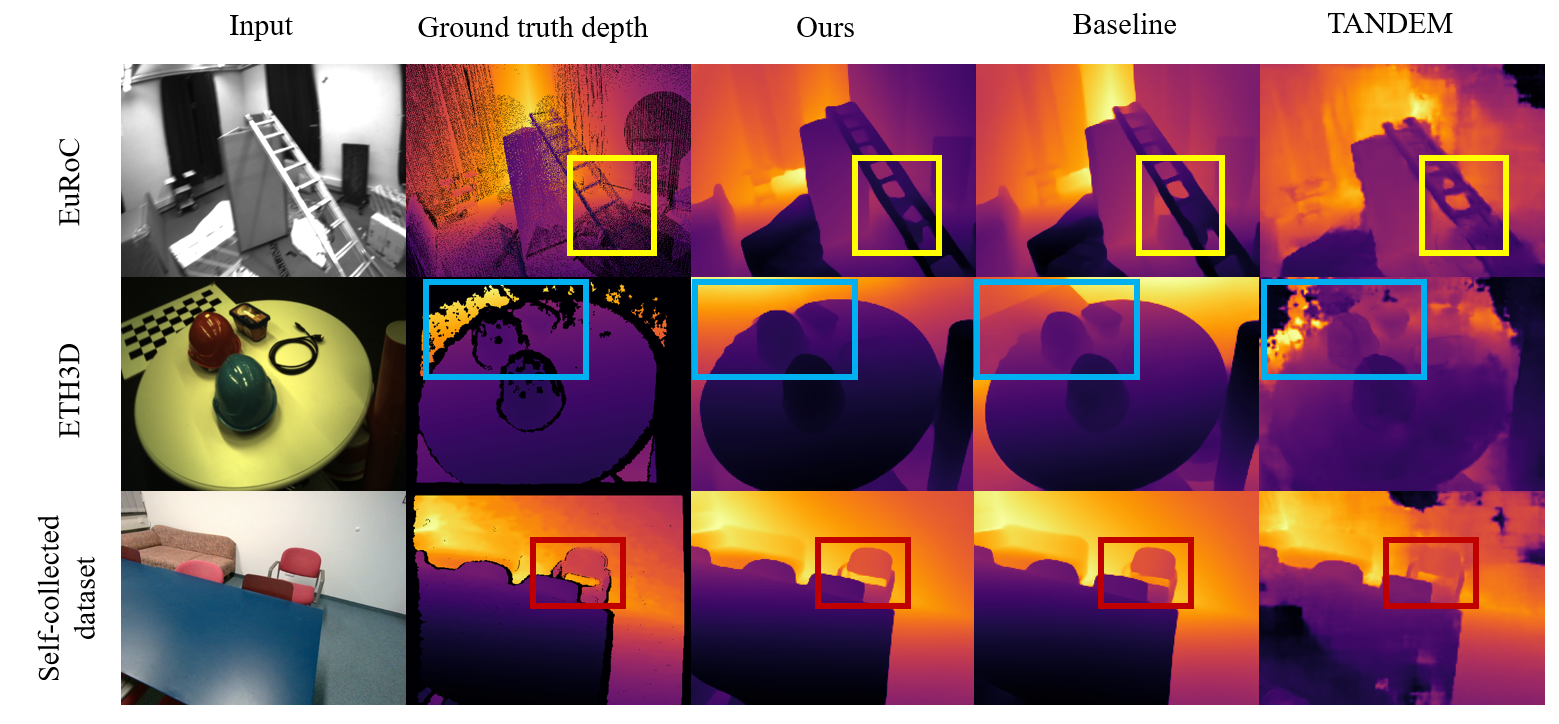
Figure 2: Depth prediction from the MVS networks constituting dense mapping systems on EuRoC.
The MVS network is based on SimpleRecon [sayed2022simplerecon], which utilizes 2D CNNs for efficient computation. The cost volume generation is guided by the dense depth prior from the single-view depth completion network. Instead of constructing a cost volume covering the entire 3D space, the system focuses on regions more likely to contain surfaces. (Figure 2) The hypothesis 3D surfaces are spaced at distances defined by:
$\mathcal{C}(\mathbf{u}) = \{ \hat{\mathbf{D}(\mathbf{u}) - n_1 \lambda , \hat{\mathbf{D}(\mathbf{u}) - (n_1 - 1)\lambda, \cdots, \hat{\mathbf{D}, \cdots, \hat{\mathbf{D}(\mathbf{u}) + (n_2 -1)\lambda , \hat{\mathbf{D}(\mathbf{u}) + n_2 \lambda \}$
where λ is the constant interval, and n1 and n2 are the number of hypothesis surfaces on both sides of the central prior surface. Hierarchical deep feature maps from the depth completion decoder are concatenated into the decoder of the MVS regularization module through skip connections.
Experimental Results and Analysis
The system was evaluated on several public datasets, including EuRoC [Burri25012016], ETH3D [schops2019bad], and ScanNet [dai2017scannet], as well as a self-collected dataset. The results demonstrate that SimpleMapping achieves state-of-the-art dense reconstruction quality at a fast runtime. The SPA-MVSNet, trained on ScanNet [dai2017scannet], showed strong generalization capabilities on unseen datasets.
Dense Depth Prediction of SPA-MVSNet

Figure 3: 3D reconstruction on EuRoC [Burri25012016].
The SPA-MVSNet outperforms existing MVS methods in terms of depth prediction accuracy on both ScanNet [dai2017scannet] and 7-Scenes [shotton2013scene]. The sparse depths, despite being noisy, provide useful priors for network optimization. For 3D mesh reconstruction, SimpleMapping achieves superior performance compared to volumetric fusion methods, highlighting its efficiency and effectiveness. (Figure 3)
Real-Time Dense Mapping

Figure 4: 3D reconstruction on ETH3D [schops2019bad].
Evaluations on the EuRoC dataset [Burri25012016] show that SimpleMapping outperforms TANDEM [koestler2021tandem], particularly on challenging sequences. The system also demonstrates superior performance on the ETH3D dataset [schops2019bad] and the self-collected dataset. Qualitative results show that SimpleMapping achieves accurate depth predictions with smooth surfaces and detailed structures. (Figure 4)
Ablation Studies

Figure 5: 3D reconstruction on ScanNet [dai2017scannet].
Ablation studies were conducted to evaluate the impact of different components of the SPA-MVSNet. The results show that the depth prior guided cost volume formulation and the integration of deep depth features significantly improve the accuracy of depth prediction. The network also demonstrates robustness to varying numbers of sparse points and noise levels. (Figure 5)
Conclusion
The SimpleMapping system demonstrates state-of-the-art dense mapping performance with robustness, efficiency, and generalization capabilities. The SPA-MVSNet effectively utilizes sparse depth information from VIO to recover dense depth maps, making the system suitable for AR and VR applications. Future work will focus on expanding the VIO tracking to include loop closure correction for enhanced consistency in large-scale scenarios.