- The paper introduces InterCode, a reinforcement learning framework integrating execution feedback to improve interactive code generation.
- It standardizes coding evaluation by enabling safe, reproducible Docker environments across Bash, SQL, and Python using datasets like NL2Bash and Spider.
- The framework’s incorporation of interactive feedback and prompt strategies like ReAct demonstrates significant gains in model performance and error correction.
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback
Introduction
"InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback" introduces a framework, InterCode, designed to address the gap in evaluating interactive code generation processes. Traditional coding benchmarks often overlook the interactive nature of coding by adhering to static, instruction-to-code paradigms. InterCode positions itself as a flexible framework that engages with the interactive nature of coding using a reinforcement learning approach, thereby encompassing actions as code and feedback as observations within a self-contained Docker environment. This facilitates the integration of execution feedback into the coding loop, crucial for addressing error propagation and enhancing code-execution alignment.
Framework Overview
InterCode is constructed as a reinforcement learning environment characterized by a process where programming steps are treated as actions and execution outputs serve as observations. The environment is managed using Docker for safe, reproducible execution across diverse platforms and languages. InterCode is language and platform-agnostic and can integrate seamlessly with current seq2seq frameworks or new interactive coding methods.
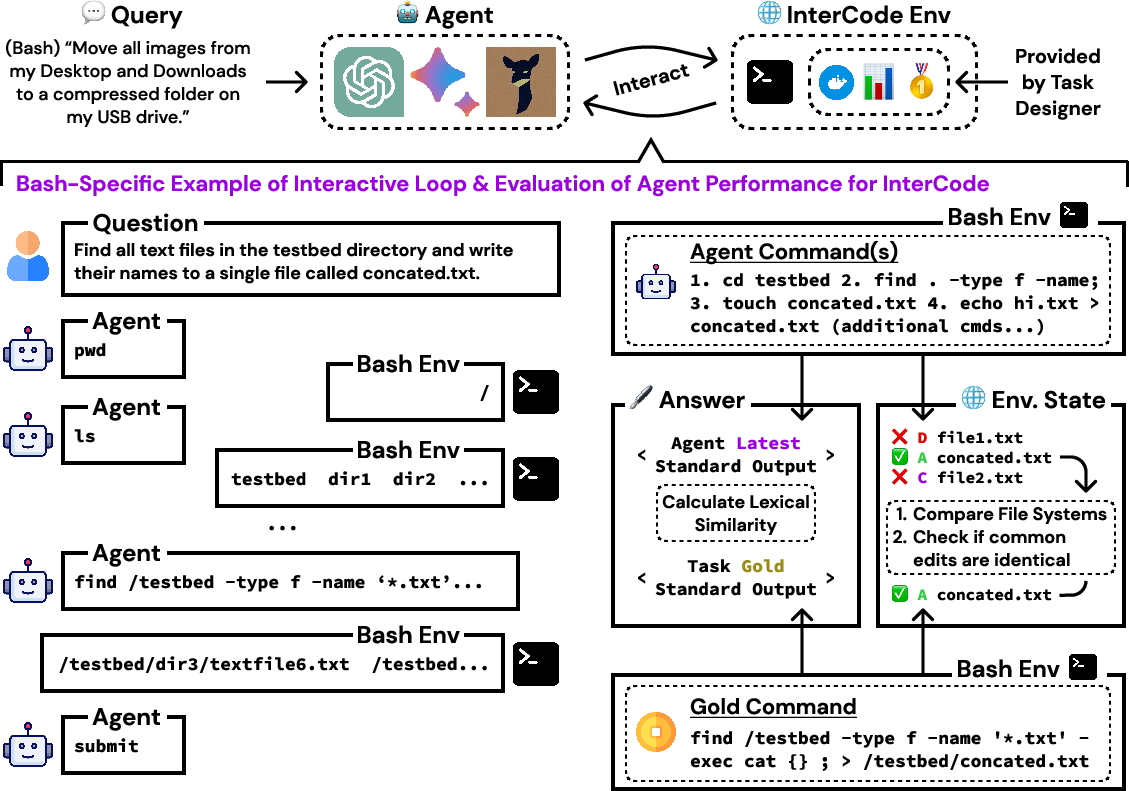
Figure 1: Overview of InterCode. Setting up InterCode requires a Dockerfile, dataset, and reward function, supporting complex evaluation beyond binary scoring.
Implementation in Practice
InterCode's application is demonstrated through the development of environments for Bash, SQL, and Python, utilizing datasets like NL2Bash and Spider. The framework empowers interactive coding evaluation by factoring in how execution feedback progressively informs code generation. Agents use InterCode in conjunction with prompting strategies like ReAct and Plan-and-Solve, revealing significant improvements in the state-of-the-art models’ capabilities for interaction-mediated coding tasks.
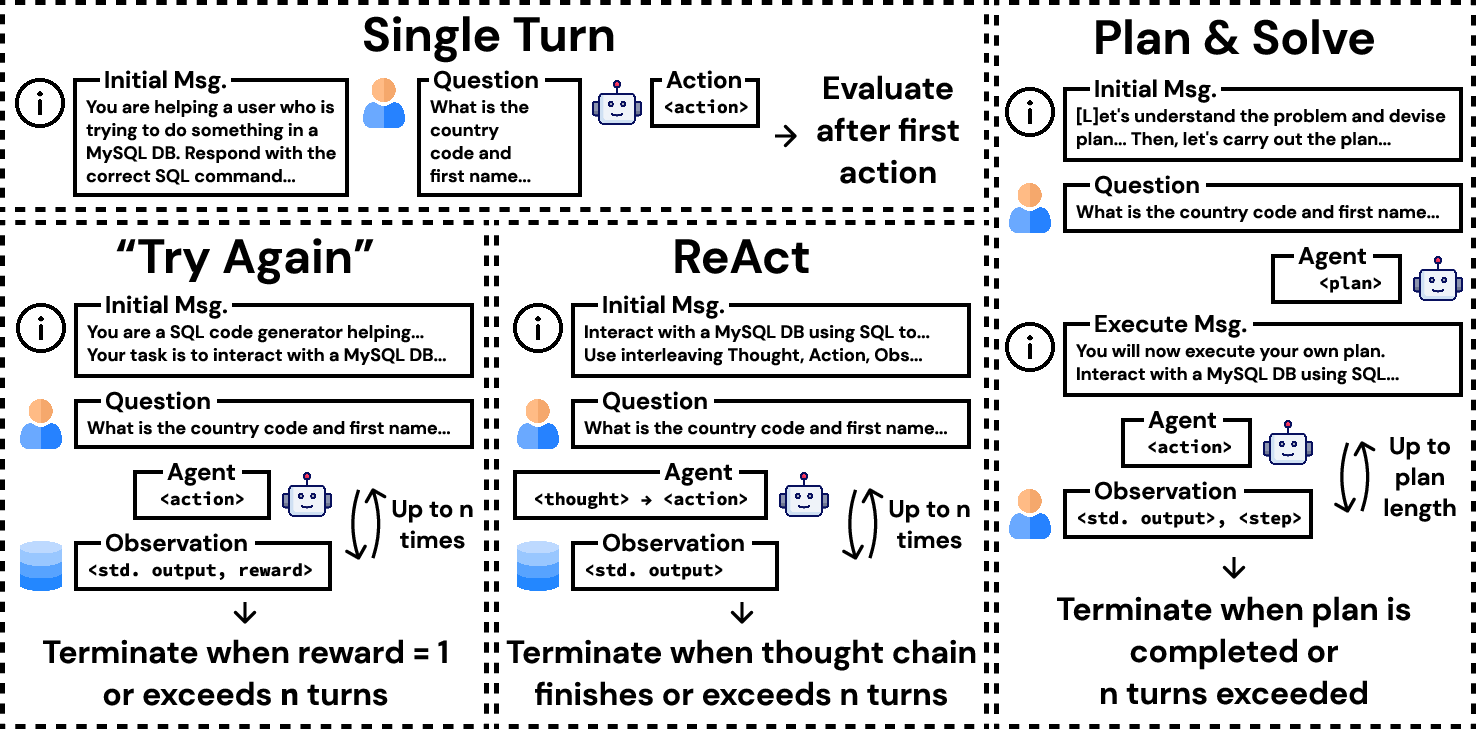
Figure 2: Success rate vs. turns for InterCode-Bash.
Design and Evaluation
The benchmark assesses how well models perform tasks via interactive refinements rather than static solutions. An action's impact, familiarity with state space changes, and the granularity of feedback influence model learning curves, success rates, and error frequencies. The framework accommodates various complexity levels in feedback design, allowing intricate scoring based on execution outcomes and file system interactions.
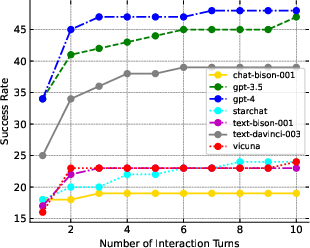
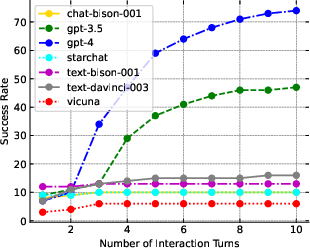
Figure 3: Example of interactions between an agent and the InterCode Python Environment.
Practical Applications
By augmenting traditional coding models with execution feedback, InterCode enhances the robustness of models in real-world coding environments. This has implications for educational tools, IDEs, and other systems where interactive feedback can substantially affect user proficiency and productivity. The flexibility allows for adaptation to various tasks such as Capture the Flag challenges, enriching the interactive capabilities of AI systems in these contexts.
Future Prospects
InterCode sets a precedent for evaluating natural language-based programming interfaces and delineates a roadmap for advancing more nuanced, interactive AI-driven coding. Prospects for InterCode include expanding its reach to additional programming languages and complex multi-language challenges. These expansions promise richer interaction paradigms and the potential to significantly advance AI's role in software development.
Conclusion
InterCode provides a robust, scalable solution for benchmarking interactive coding models with execution feedback. Through its standardized, reproducible framework, it bridges gaps in existing benchmarks by fostering an ecosystem where dynamic interaction and feedback are integral to code comprehension and generation. Future iterations will continue to explore its adaptability and potential across broader programming landscapes.