- The paper presents an extensive catalog of DL accelerator architectures, analyzing both traditional (GPU/TPU) and emerging (in-memory, neuromorphic) designs.
- It details methodologies for optimizing parallel processing and memory bandwidth, highlighting key performance improvements across multiple accelerator types.
- The survey discusses future paths such as quantum and photonic accelerators, emphasizing their potential to transform HPC and AI integration.
Introduction
The paper provides an extensive overview of deep learning (DL) hardware accelerators aimed at supporting high-performance computing (HPC) applications. It categorizes the most recent advances in DL accelerator technologies, focusing on various architectures including GPU-based accelerators, Tensor Processing Units (TPUs), Field-Programmable Gate Arrays (FPGAs), Application-Specific Integrated Circuits (ASICs), and emerging paradigms like in-memory computing and neuromorphic processing units. The survey highlights the influence of architectures proposed over the last two decades and examines future potential technologies like quantum accelerators and photonics.
Deep Learning Background
Deep learning methods utilize artificial neural networks (ANNs) to learn from large datasets. The dominant topologies discussed are Deep Neural Networks (DNNs), comprising multiple layers, and Transformers, originally designed to handle NLP tasks. While DNNs depend significantly on convolutional layers for computing efficiency, Transformers leverage attention layers. Both share underlying principles, such as reliance on linear algebra and gradient descent for training, which are critical for accelerator optimization.
GPU and TPU Accelerators
GPUs offer substantial parallel processing capabilities, crucially benefiting from memory bandwidth optimization for DL tasks. NVIDIA's advances across various architectures from Fermi to Hopper have consistently increased throughput and efficiency. TPU accelerators, pioneered by Google, focus on optimizing linear algebra operations central to DL workloads. Their evolution from inference-exclusive designs to multifunctional training units exemplified by the TPUv3 showcases robust performance improvements, paralleled by NVIDIA's TensorCores embedded within its GPUs.
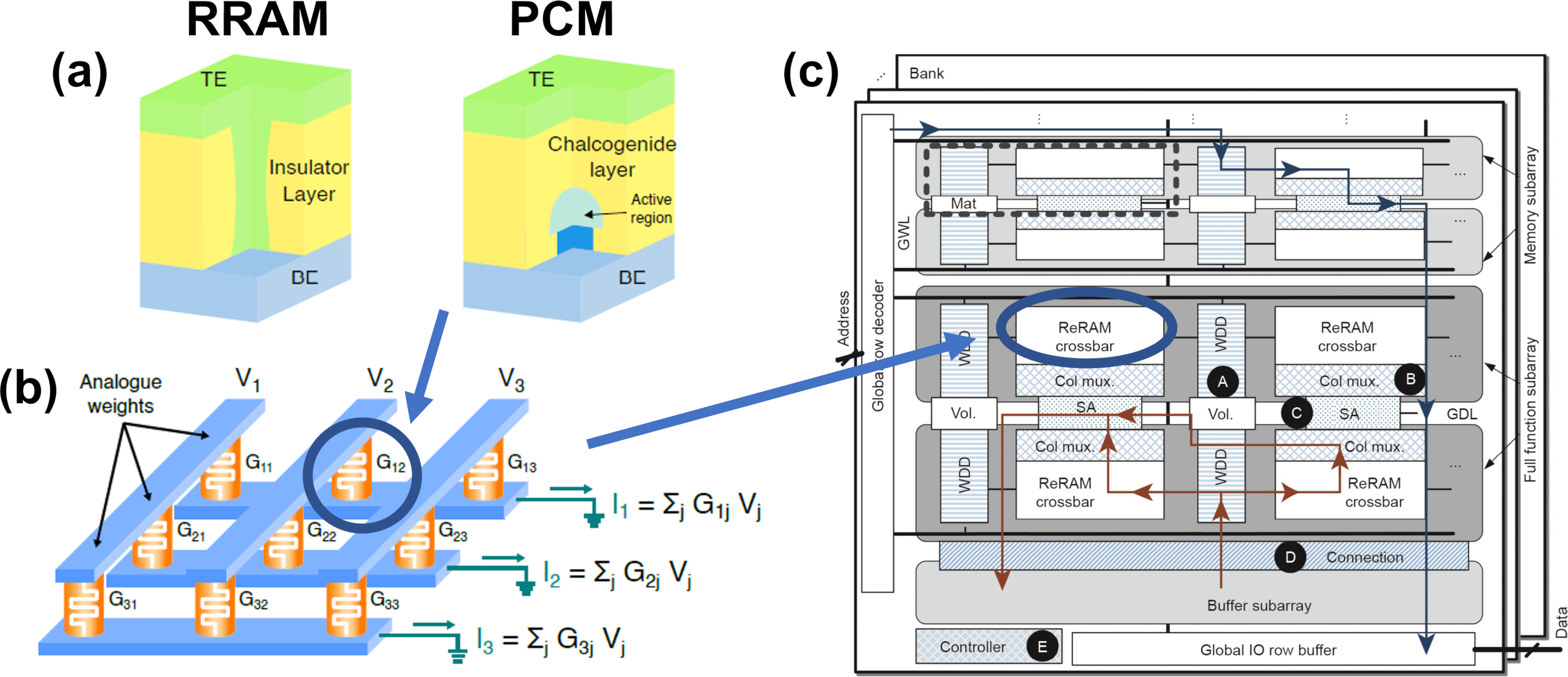
Figure 1: (a) RRAM and PCM devices structure and (b) their arrangement in a crossbar structure for matrix-vector multiplication. (c) Example of a stand-alone DNN accelerator (i.e., PRIME).
Hardware Accelerators
Hardware accelerators such as FPGAs and ASICs facilitate efficient computational handling for DL workloads thanks to their ability to integrate parallelism at the silicon level. FPGAs, with their versatility in reconfiguration, offer viable solutions for edge applications, while ASICs optimize specific processes within DL models. Reconfigurable architectures like CGRAs present middle-ground solutions combining speed and modularity beneficial for complex linear algebra computations.
Accelerators Based on Emerging Paradigms and Technologies
Accelerators exploiting sparse matrix computations optimize memory access patterns and computational cycles, crucial for handling modern DL models' demands. Processing-in-memory technologies leverage 3D stacking to significantly reduce computational latency and improve efficiency. Emerging memory technologies, such as RRAM and PCM, integrate computational capabilities directly within memory components, promoting speed, and reduced energy consumption crucial for AI workloads.
Neuromorphic and Multi-Chip Module Accelerators
Neuromorphic computing represents a paradigm shift, with designs mimicking neural plasticity and employing SNN architectures. Chips like IBM's TrueNorth and Intel's Loihi scale up architectural features, focusing on flexibility and compute density. Multi-chip modules (MCMs) enhance design choices by integrating processors across dies using interposer technologies, exemplified by the Simba architecture, that showcase scalable performance made viable through efficient inter-chip communication designs.
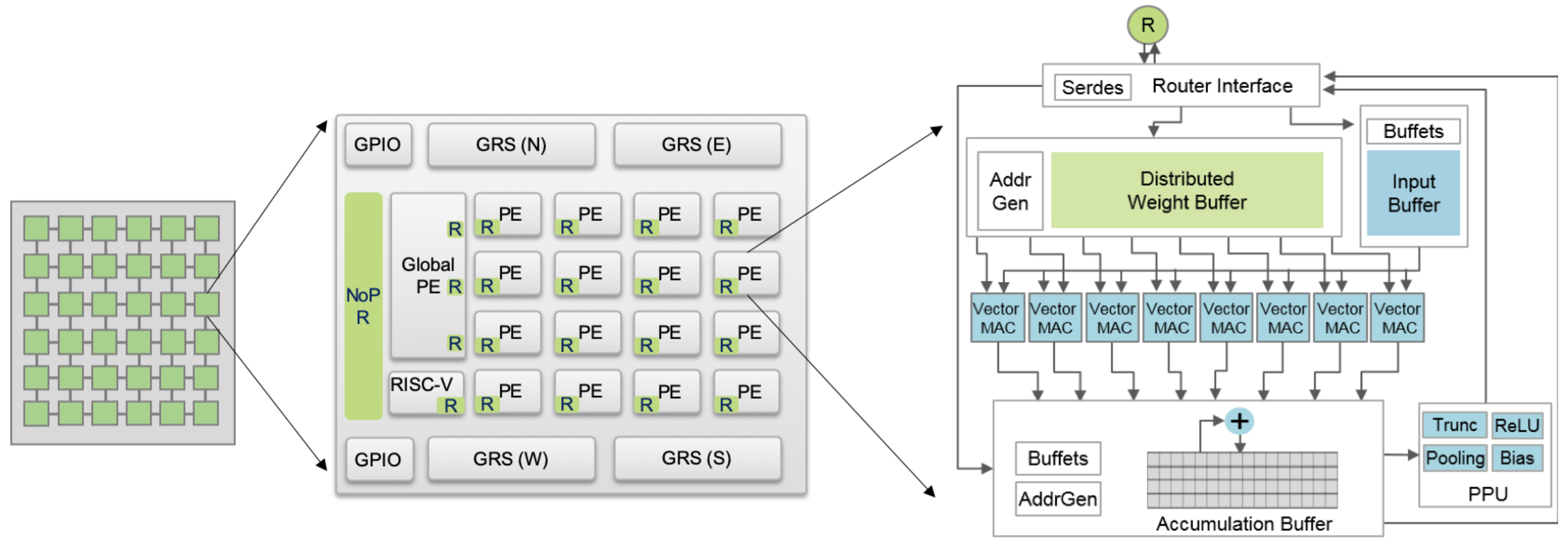
Figure 2: Simba architecture demonstrating scalable multi-chip design.
Conclusion
The survey details how advancements in hardware accelerators address the growing demands of DL applications on HPC platforms. It acknowledges the shift from exclusively traditional computing frameworks towards integrated solutions that consider power efficiency and scalability. Furthermore, quantum and photonic computing appear as potential future avenues, bringing novel methods to accelerate workloads profoundly impacting AI and HPC integration. The review underscores the necessity for continued exploration and evaluation of emerging technologies to keep pace with DL applications' ever-evolving computational needs.