- The paper introduces DiffComplete, which uses a diffusion model to achieve high-fidelity, multi-modal 3D shape completion from partial scans.
- It employs hierarchical feature aggregation and occupancy-aware fusion to accurately reconstruct details despite noise and occlusions.
- Experimentally, it reduces l1 error by 40% on benchmarks and robustly generalizes to unseen object classes.
DiffComplete: Diffusion-based Generative 3D Shape Completion
Introduction
The paper "DiffComplete: Diffusion-based Generative 3D Shape Completion" (2306.16329) presents a novel approach for completing 3D shapes obtained from range scans. DiffComplete operates by leveraging a diffusion model which provides a balance between realism, multi-modality, and fidelity in shape generation. The paper addresses the challenges posed by incomplete 3D reconstructions due to occlusions and noise inherent in scanning processes. The proposed methodology offers practical enhancements over existing deterministic and probabilistic models, especially in generalizing to unseen object classes without the need for re-training.
Methodology
DiffComplete's architecture introduces two key innovations: hierarchical feature aggregation and an occupancy-aware fusion strategy. The former ensures effective control over the completion results by encoding both local details and broader contexts from partial inputs. This is achieved by aggregating features at multiple network levels to capture spatially-consistent information. The latter, occupancy-aware fusion, allows the model to incorporate multiple partial scan inputs, adding flexibility and accuracy to the completion process.
The shape completion is treated as a conditional generation task, where the diffusion model corrupts the true object shape gradually with Gaussian noise, and the reverse process reconstructs the shape conditioned on the incomplete scan. Two branches—main and control—govern the network's architecture, facilitating interaction between corrupted and partial shapes to predict the denoising process.
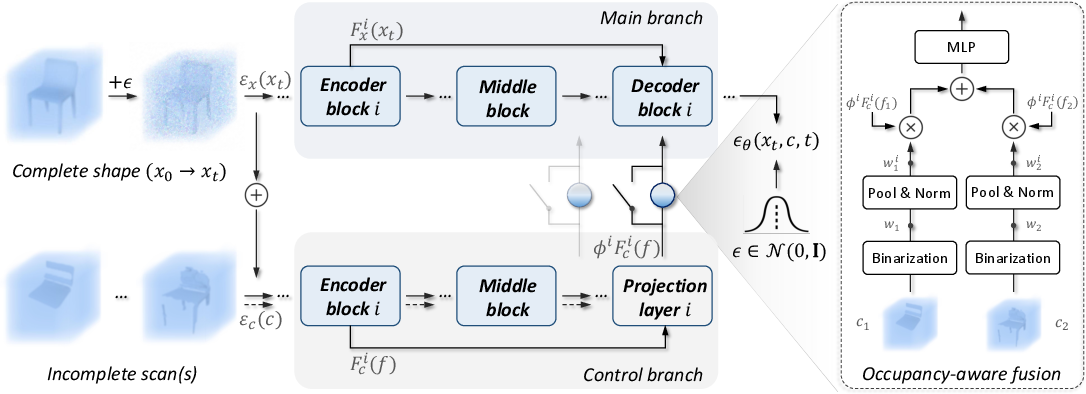
Figure 1: Given a corrupted complete shape xt (diffused from x0) and an incomplete scan c, multi-level feature aggregation aids in hierarchical control over predicting diffusion noise.
Experimental Results
DiffComplete sets a new state-of-the-art performance across multiple benchmarks, with notable improvements in fidelity and generalization. On the 3D-EPN benchmark, it decreases the l1 error by 40% compared to prior methods, demonstrating enhanced fidelity in realized shapes. The model excels on unseen object categories in both synthetic and real-world conditions, showing its ability to robustly generalize devoid of the retraining process. For instance, on synthetic ShapeNet data, DiffComplete renders completed shapes with significantly higher accuracy than PatchComplete, which was the previous best.

Figure 2: Shape Completion on various known object classes. We achieve the best completion quality.

Figure 3: Shape completion on synthetic (blue) and real (yellow) objects of entirely unseen classes. Our method produces completed shapes in superior quality with both synthetic and real data.
Multimodal Capabilities
DiffComplete inherently supports multimodal completion, producing diverse shape outputs from a single input condition by exploiting the probabilistic nature of the diffusion model. This enables exploration of various plausible reconstructions, thus accommodating the ambiguity in cases of significant occlusions. The evaluation metrics, including MMD, TMD, and UHD, underscore its superior accuracy and fidelity with moderate diversity.
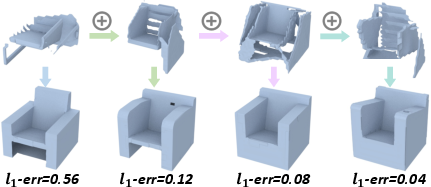
Figure 4: Our method produces multimodal plausible results given the same partial shape.
Implications and Future Work
This work demonstrates that generative diffusion models can significantly enhance 3D shape completion tasks by balancing fidelity and multi-modality. The hierarchical feature aggregation strategy not only improves accuracy but also promotes the generalizability of models to novel classes. While the method's inference time necessitates computational considerations, potential optimizations through advanced sampling techniques can address these limitations. Future avenues may involve refining the model's robustness to extremely sparse data and further integration into real-time 3D perception systems.
Conclusion
DiffComplete stands as a robust framework for 3D shape completion, effectively merging the advantages of diffusion models with innovative feature integration strategies. It offers substantial progress in generating highly accurate and versatile shape completions, paving the way for more adaptable 3D modeling solutions across various applications. Overall, this approach signifies a noteworthy contribution to the field of 3D shape completion and generative modeling.

