- The paper introduces a residual-based attention scheme that adaptively weights collocation points to enhance PINN convergence and accuracy.
- It employs deterministic Lagrange multiplier updates with Fourier embeddings, achieving relative L2 errors as low as 1e-5 on benchmark PDEs.
- The connection to Information Bottleneck theory reveals distinct learning phases, offering insights for developing robust neural operator strategies.
Introduction
The paper "Residual-based attention and connection to information bottleneck theory in PINNs" (2307.00379) investigates the challenges associated with the convergence and accuracy of physics-informed neural networks (PINNs). This work proposes a gradient-less weighting scheme that leverages residual-based attention (RBA) to improve the effectiveness of PINNs without incurring additional computational costs. The authors also draw connections between the training dynamics of PINNs and the Information Bottleneck (IB) theory, offering insights into the learning phases and mechanisms underlying these models.
PINNs are an increasingly popular approach for solving partial differential equations (PDEs) by embedding physical laws into the loss function of neural networks. These networks are trained to minimize a composite loss that balances terms associated with the PDE residual, initial conditions, and boundary conditions. The challenge in training PINNs lies in balancing these different terms to achieve reliable and accurate convergence, especially in complex, multiscale, or chaotic systems. Various strategies have been previously proposed, including adaptive weighting and network architecture modifications, to mitigate these challenges.
Residual-Based Attention Scheme
The authors introduce an RBA scheme designed to adaptively weight the contribution of individual collocation points based on their residual values. This scheme employs a deterministic update rule for the Lagrange multipliers, ensuring bounded weight values and increased attention on problematic regions during training. The RBA scheme operates without the need for gradient evaluations, thus avoiding additional computational burdens typically associated with other adaptive weighting strategies.
The RBA approach involves computing local multipliers that evolve with the training process, allowing the model to dynamically adjust focus on regions where the PDE solution is less accurate. This flexibility helps improve convergence and accuracy, particularly for challenging PDE problems like the Allen-Cahn and Helmholtz equations.
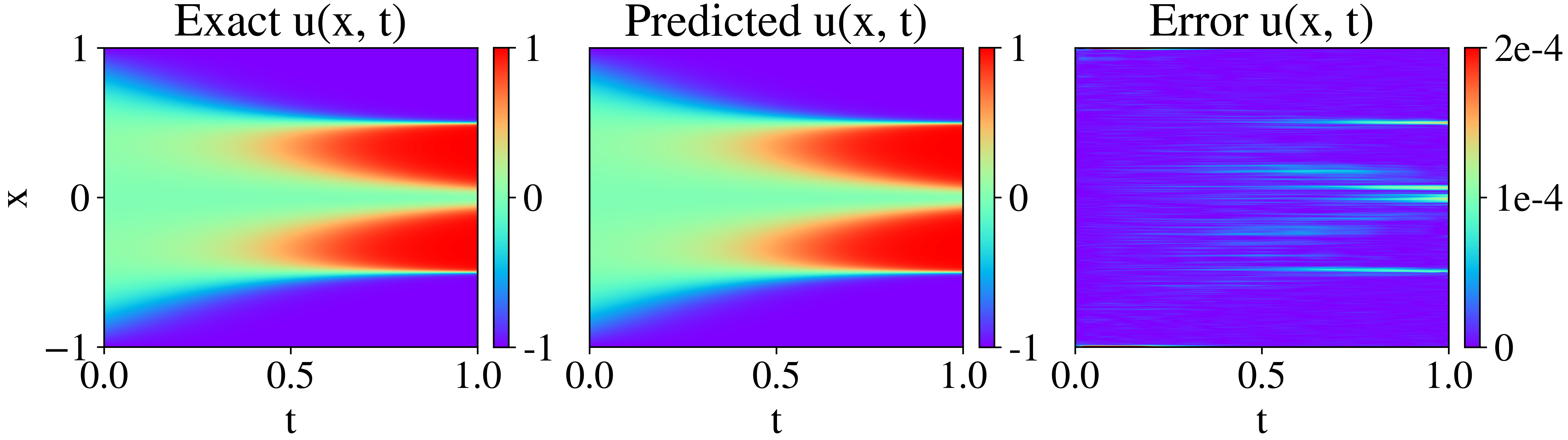
Figure 1: Exact solution of the 1D Allen-Cahn with the corresponding network prediction and the absolute error difference.
Experimental Results
Allen-Cahn Equation
In the experiments conducted on the 1D Allen-Cahn equation, the RBA scheme demonstrated the ability to achieve a relative L2 error of the order 10−5, outperforming traditional PINN approaches and competing with other state-of-the-art adaptive methods. The ablation study highlighted the importance of Fourier feature embeddings in conjunction with RBA for effective loss minimization and convergence acceleration (Figure 2).
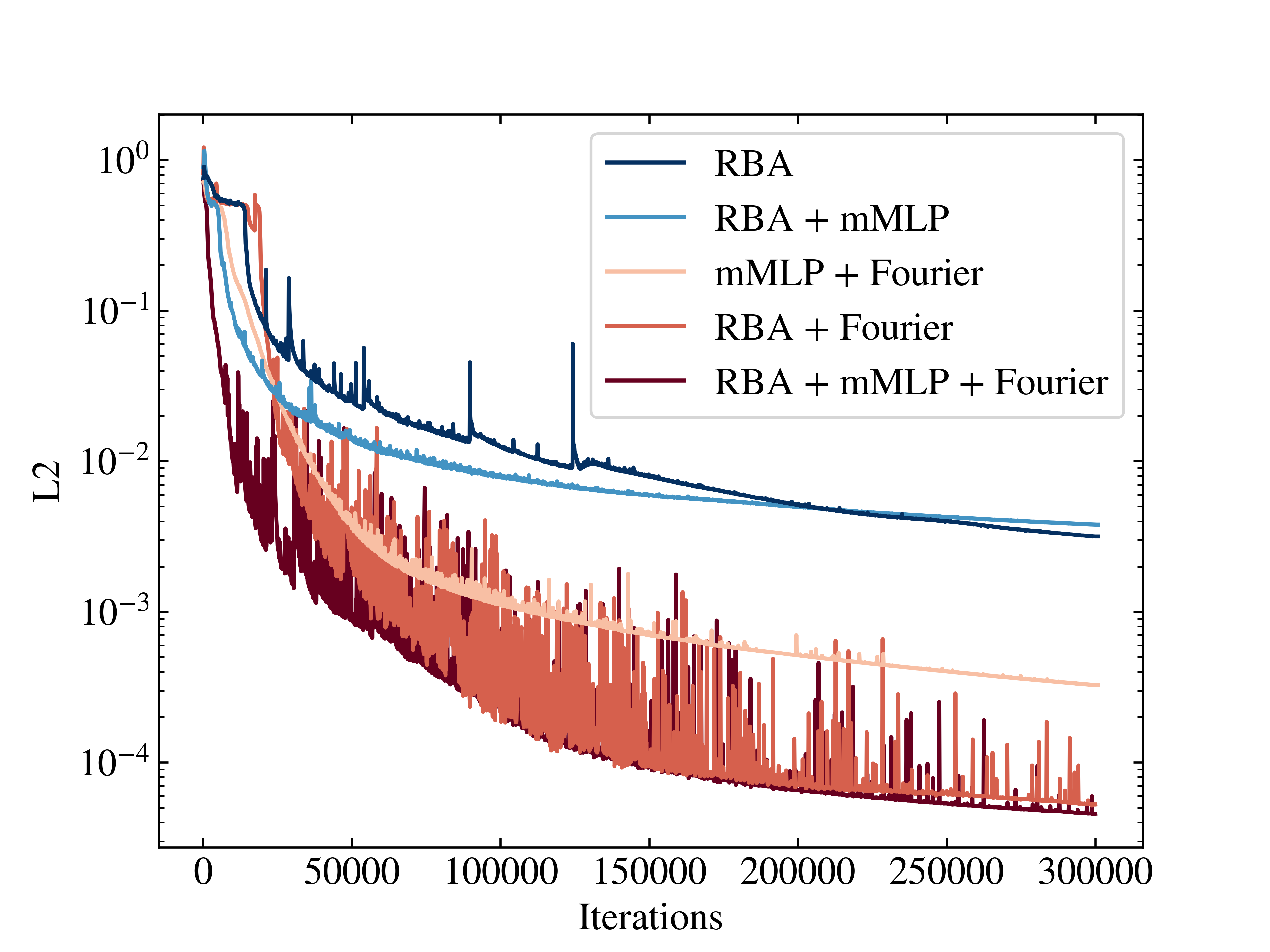
Figure 2: Ablation study convergence for the 1D Allen-Cahn: Progression of convergence for each experiment. The integration of the RBA approach and Fourier features is crucial for achieving minimal relative L2.
Helmholtz Equation
The RBA approach was also tested on the 2D Helmholtz equation, with results showing substantial improvements in error reduction comparable to leading methods. The study explored two boundary condition impositions: Fourier embeddings and approximate distance functions (ADF). The Fourier-based method attained optimal performance, suggesting that embedding problem-specific characteristics can significantly enhance model performance (Figure 3).
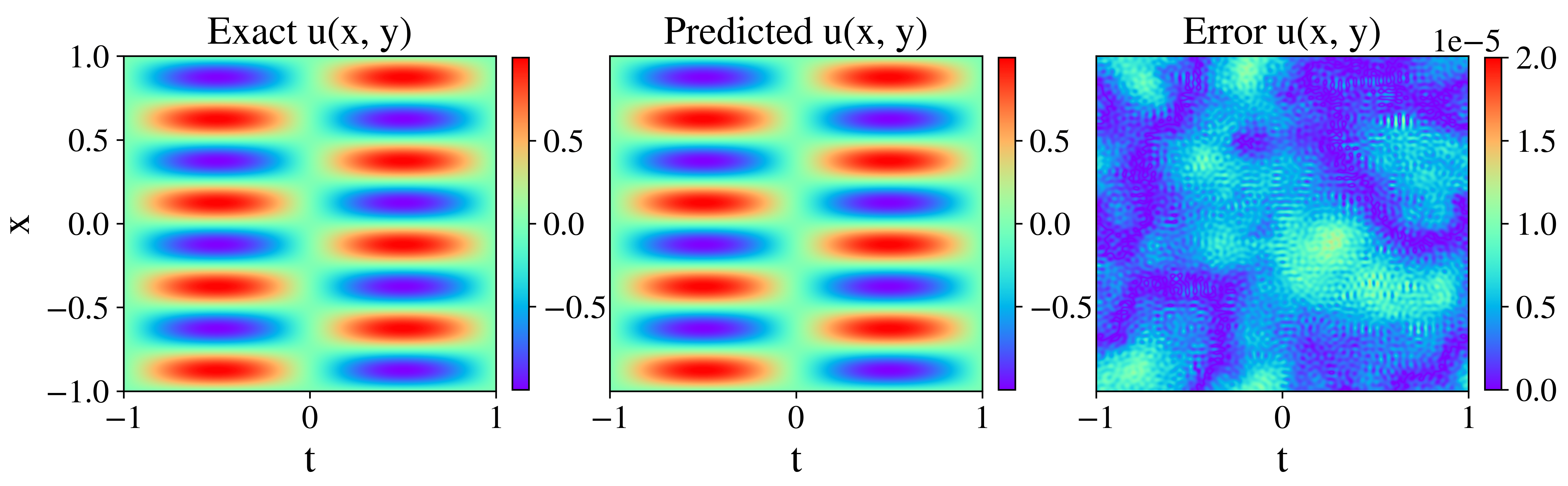
Figure 3: Analytical solution for the 2D Helmholtz equation and the corresponding network prediction with the absolute error difference.
The evolution of RBA weights during training revealed distinct learning phases that align with the fitting and diffusion phases proposed by the IB theory. In the fitting phase, the model captures essential signal features, maintaining high signal-to-noise ratio (SNR), while the diffusion phase focuses on simplifying representations and improving generalization, marked by reduced SNR.
The authors' gradient analysis shows that transitions between these phases correspond with a shift from order to disorder in the weight distributions. This behavior is observed across different PDE benchmarks and suggests that the IB theory can provide a framework for understanding the learning dynamics in PINNs, potentially guiding the development of more effective weighting schemes.
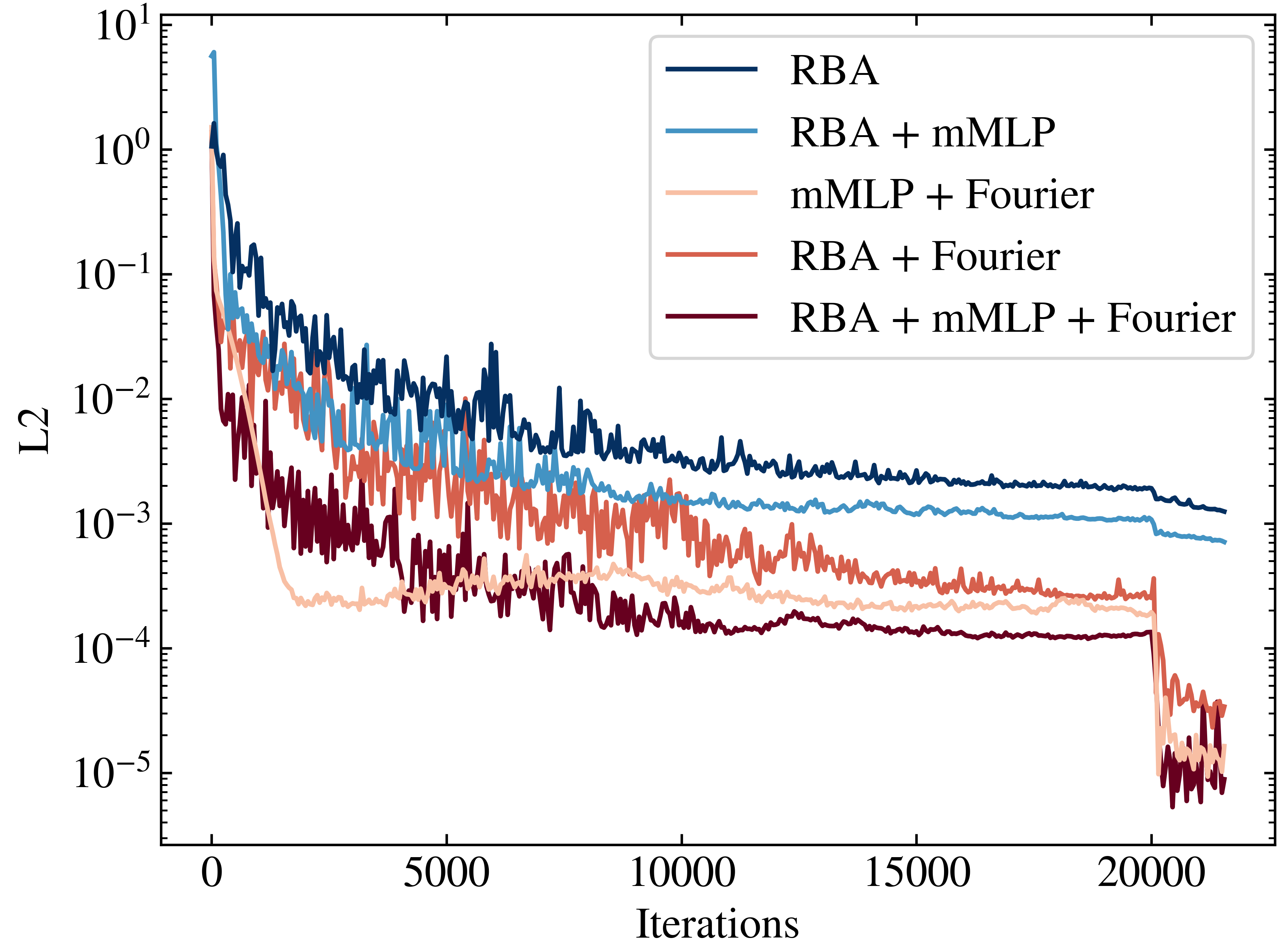
Figure 4: Evolution of RBA weights. The peak value is constrained by the decay parameter and learning rate, indicating dynamic adaptation during training.
Conclusion
This paper presents a compelling case for the use of residual-based attention in enhancing the performance and convergence of physics-informed neural networks. The straightforward implementation and absence of gradient calculations make the RBA scheme an attractive choice for addressing challenging PDEs. Furthermore, the connection between PINN training dynamics and IB theory offers promising avenues for future research. The insights gained from these theories could lead to new strategies for improving the stability and robustness of neural operators in various applications.