Leveraging Multi-modal Sensing for Robotic Insertion Tasks in R&D Laboratories
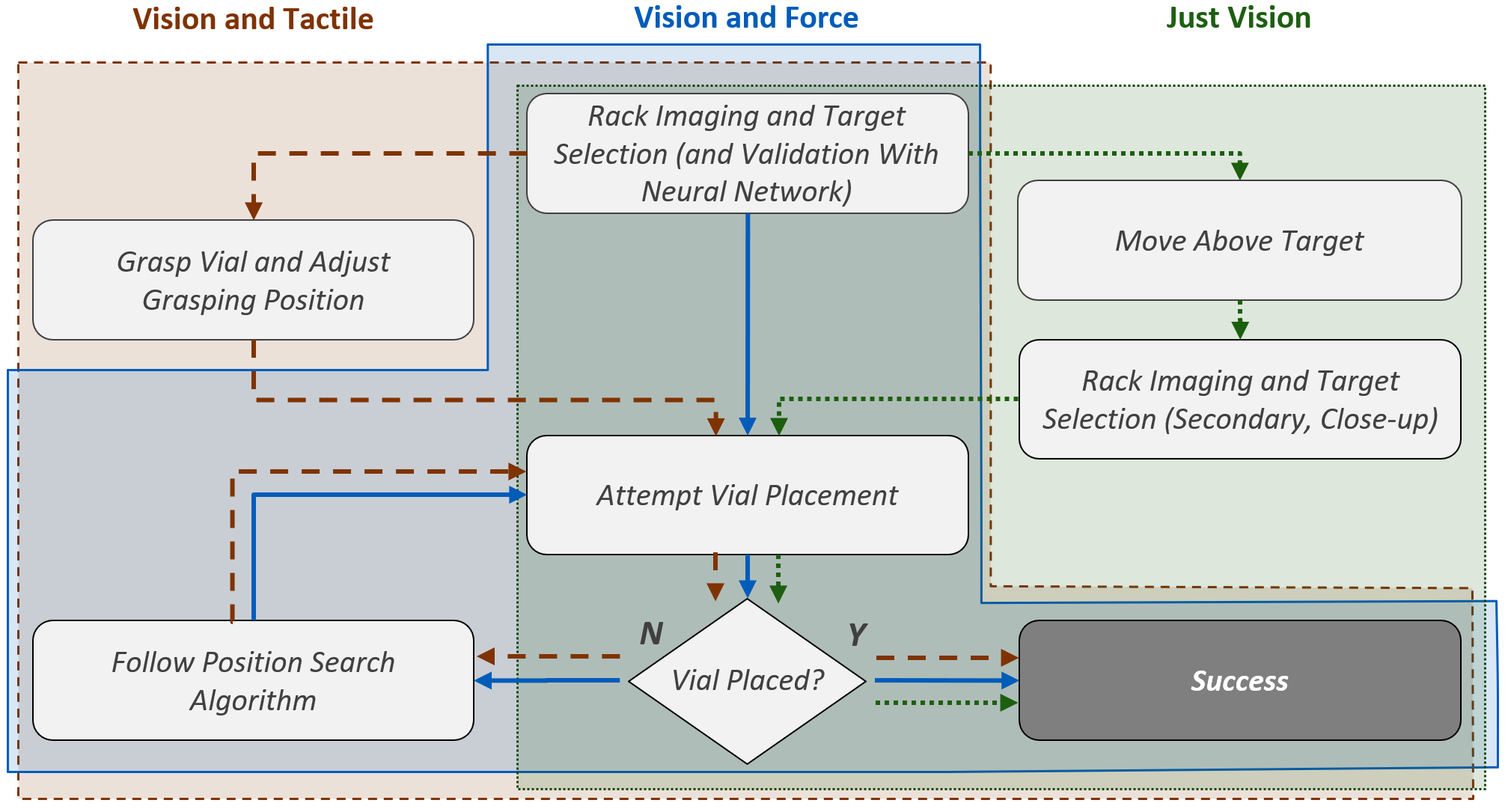
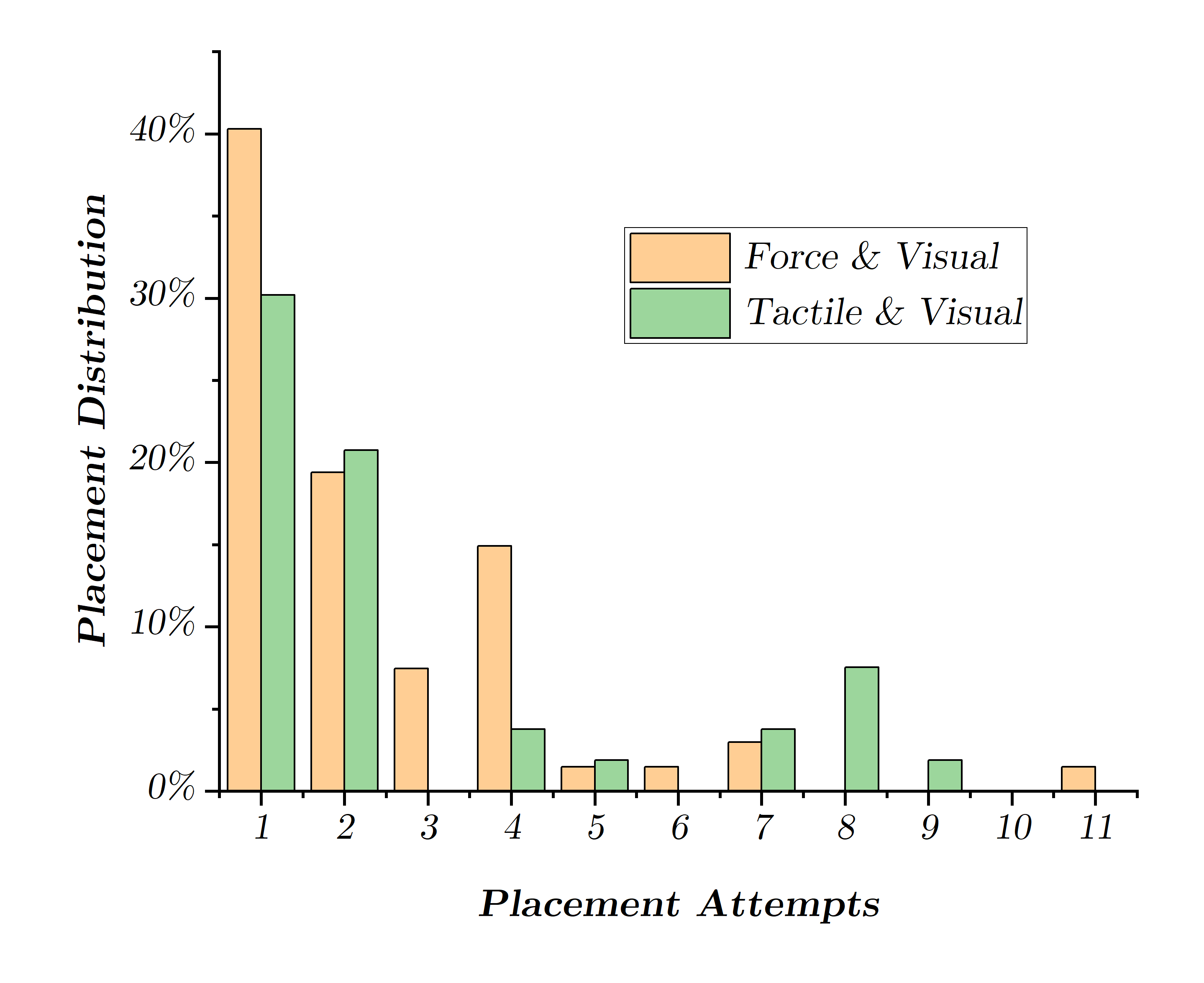
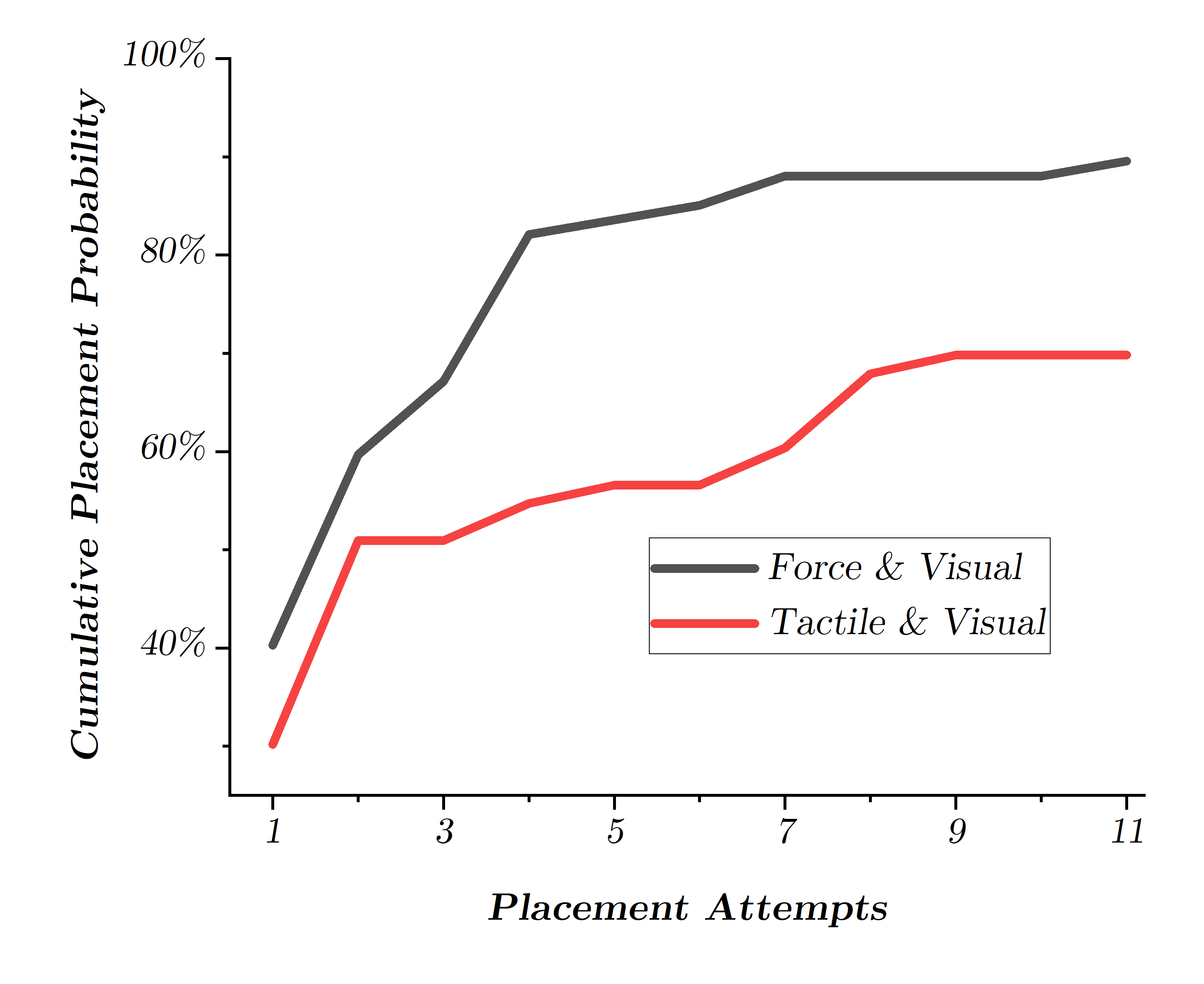
Abstract: Performing a large volume of experiments in Chemistry labs creates repetitive actions costing researchers time, automating these routines is highly desirable. Previous experiments in robotic chemistry have performed high numbers of experiments autonomously, however, these processes rely on automated machines in all stages from solid or liquid addition to analysis of the final product. In these systems every transition between machine requires the robotic chemist to pick and place glass vials, however, this is currently performed using open loop methods which require all equipment being used by the robot to be in well defined known locations. We seek to begin closing the loop in this vial handling process in a way which also fosters human-robot collaboration in the chemistry lab environment. To do this the robot must be able to detect valid placement positions for the vials it is collecting, and reliably insert them into the detected locations. We create a single modality visual method for estimating placement locations to provide a baseline before introducing two additional methods of feedback (force and tactile feedback). Our visual method uses a combination of classic computer vision methods and a CNN discriminator to detect possible insertion points, then a vial is grasped and positioned above an insertion point and the multi-modal methods guide the final insertion movements using an efficient search pattern. Through our experiments we show the baseline insertion rate of 48.78% improves to 89.55% with the addition of our "force and vision" multi-modal feedback method.
- B. Burger, P. M. Maffettone, V. V. Gusev, C. M. Aitchison, Y. Bai, X. Wang, X. Li, B. M. Alston, B. Li, R. Clowes, N. Rankin, B. Harris, R. S. Sprick, and A. I. Cooper, “A mobile robotic chemist,” Nature, vol. 583, no. 7815, pp. 237–241, Jul. 2020, number: 7815 Publisher: Nature Publishing Group. [Online]. Available: https://www.nature.com/articles/s41586-020-2442-2
- H. Fakhruldeen, G. Pizzuto, J. Glowacki, and A. I. Cooper, “Archemist: Autonomous robotic chemistry system architecture,” IEEE International Conference on Robotics and Automation, 2022.
- P. Shiri, V. Lai, T. Zepel, D. Griffin, J. Reifman, S. Clark, S. Grunert, L. P. Yunker, S. Steiner, H. Situ, F. Yang, P. L. Prieto, and J. E. Hein, “Automated solubility screening platform using computer vision,” iScience, vol. 24, no. 3, p. 102176, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2589004221001449
- M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V. R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra, “DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 3838–3845, Jul. 2020, arXiv:2005.14679 [cs, eess, stat]. [Online]. Available: http://arxiv.org/abs/2005.14679
- L. Pecyna, S. Dong, and S. Luo, “Visual-Tactile Multimodality for Following Deformable Linear Objects Using Reinforcement Learning,” Mar. 2022, arXiv:2204.00117 [cs]. [Online]. Available: http://arxiv.org/abs/2204.00117
- M. A. Lee, Y. Zhu, P. Zachares, M. Tan, K. Srinivasan, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg, “Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks,” IEEE Transactions on Robotics, vol. 36, no. 3, pp. 582–596, Jun. 2020, conference Name: IEEE Transactions on Robotics.
- G. Pizzuto, J. de Berardinis, L. Longley, H. Fakhruldeen, and A. I. Cooper, “Solis: Autonomous solubility screening using deep neural networks,” IEEE International Joint Conference on Neural Networks, 2022.
- J. X.-Y. Lim, D. Leow, Q.-C. Pham, and C.-H. Tan, “Development of a robotic system for automatic organic chemistry synthesis,” IEEE Transactions on Automation Science and Engineering, vol. 18, no. 4, pp. 2185–2190, 2021.
- H. Fleischer, L. A. Kroos, S. Joshi, T. Roddelkopf, R. Stoll, and K. Thurow, “Dual-arm robotic compound-oriented measurement system: Integration of a positive pressure solid phase extraction unit,” in 2021 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), 2021, pp. 1–6.
- H. Fleischer, R. R. Drews, J. Janson, B. R. C. Patlolla, X. Chu, M. Klos, and K. Thurow, “Application of a dual-arm robot in complex sample preparation and measurement processes,” Journal of Laboratory Automation, vol. 21, no. 5, pp. 671–681, 2016, pMID: 27000132. [Online]. Available: https://doi.org/10.1177/2211068216637352
- S. Joshi, X. Chu, H. Fleischer, T. Roddelkopf, M. Klos, and K. Thurow, “Analysis of measurement process design for a dual-arm robot using graphical user interface,” in 2019 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), 2019, pp. 1–6.
- A. M. Amen, K. W. Barry, J. M. Boyle, C. E. Brook, S. Choo, L. T. Cornmesser, D. J. Dilworth, J. A. Doudna, A. J. Ehrenberg, I. Fedrigo, S. E. Friedline, T. G. W. Graham, R. Green, J. R. Hamilton, A. Hirsh, M. L. Hochstrasser, D. Hockemeyer, N. Krishnappa, A. Lari, H. Li, E. Lin-Shiao, T. Lu, E. F. Lyons, K. G. Mark, L. A. Martell, A. R. O. Martins, S. L. McDevitt, P. S. Mitchell, E. A. Moehle, C. Naca, D. Nandakumar, E. O’Brien, D. J. Pappas, K. Pestal, D. L. Quach, B. E. Rubin, R. Sachdeva, E. C. Stahl, A. M. Syed, I.-L. Tan, A. L. Tollner, C. A. Tsuchida, C. K. Tsui, T. K. Turkalo, F. D. Urnov, M. B. Warf, O. N. Whitney, L. B. Witkowsky, and IGI Testing Consortium, “Blueprint for a pop-up SARS-CoV-2 testing lab,” Nature Biotechnology, vol. 38, no. 7, pp. 791–797, Jul. 2020, number: 7 Publisher: Nature Publishing Group. [Online]. Available: https://www.nature.com/articles/s41587-020-0583-3
- T. Pickles, C. Mustoe, C. Brown, and A. Florence, “Autonomous datafactory : high-throughput screening for large-scale data collection to inform medicine manufacture,” British Journal of Pharmacy, 2022. [Online]. Available: https://doi.org/10.5920/bjpharm.1128
- J. Jiang, G. Cao, A. Butterworth, T.-T. Do, and S. Luo, “Where Shall I Touch? Vision-Guided Tactile Poking for Transparent Object Grasping,” IEEE/ASME Transactions on Mechatronics, pp. 1–12, 2022, conference Name: IEEE/ASME Transactions on Mechatronics.
- J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek, “Visuotactile-RL: Learning Multimodal Manipulation Policies with Deep Reinforcement Learning,” in 2022 International Conference on Robotics and Automation (ICRA), May 2022, pp. 8298–8304.
- M. S. Nixon and A. S. Aguado, “5 - High-level feature extraction: fixed shape matching,” in Feature Extraction and Image Processing for Computer Vision (Fourth Edition), M. S. Nixon and A. S. Aguado, Eds. Academic Press, Jan. 2020, pp. 223–290. [Online]. Available: https://www.sciencedirect.com/science/article/pii/B9780128149768000051
- S. Suzuki and K. Abe, “Topological structural analysis of digitized binary images by border following,” Computer Vision, Graphics, and Image Processing, vol. 30, no. 1, pp. 32–46, Apr. 1985. [Online]. Available: https://www.sciencedirect.com/science/article/pii/0734189X85900167
- Duane Q. Nykamp, “Using Green’s theorem to find area.” [Online]. Available: https://mathinsight.org/greens_theorem_find_area
- H. Fang, H.-S. Fang, S. Xu, and C. Lu, “Transcg: A large-scale real-world dataset for transparent object depth completion and a grasping baseline,” IEEE Robotics and Automation Letters, pp. 1–8, 2022.
- H. Xu, Y. R. Wang, S. Eppel, A. Aspuru-Guzik, F. Shkurti, and A. Garg, “Seeing glass: Joint point cloud and depth completion for transparent objects,” CoRR, vol. abs/2110.00087, 2021. [Online]. Available: https://arxiv.org/abs/2110.00087
- X. Liu, R. Jonschkowski, A. Angelova, and K. Konolige, “KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects,” May 2020, arXiv:1912.02805 [cs]. [Online]. Available: http://arxiv.org/abs/1912.02805
- J. Jiang, G. Cao, T.-T. Do, and S. Luo, “A4T: Hierarchical Affordance Detection for Transparent Objects Depth Reconstruction and Manipulation,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9826–9833, Oct. 2022, conference Name: IEEE Robotics and Automation Letters.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.