Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs
Abstract: Learning on Graphs has attracted immense attention due to its wide real-world applications. The most popular pipeline for learning on graphs with textual node attributes primarily relies on Graph Neural Networks (GNNs), and utilizes shallow text embedding as initial node representations, which has limitations in general knowledge and profound semantic understanding. In recent years, LLMs have been proven to possess extensive common knowledge and powerful semantic comprehension abilities that have revolutionized existing workflows to handle text data. In this paper, we aim to explore the potential of LLMs in graph machine learning, especially the node classification task, and investigate two possible pipelines: LLMs-as-Enhancers and LLMs-as-Predictors. The former leverages LLMs to enhance nodes' text attributes with their massive knowledge and then generate predictions through GNNs. The latter attempts to directly employ LLMs as standalone predictors. We conduct comprehensive and systematical studies on these two pipelines under various settings. From comprehensive empirical results, we make original observations and find new insights that open new possibilities and suggest promising directions to leverage LLMs for learning on graphs. Our codes and datasets are available at https://github.com/CurryTang/Graph-LLM.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: how can we use very powerful language tools (LLMs, or LLMs, like ChatGPT) to do better on graph problems where each point (called a “node”) has text attached to it—like a paper title and abstract in a citation network? The authors focus on a common task called node classification, where the goal is to predict the category of each node (for example, the research area of a paper).
What the researchers wanted to find out
The paper explores two big ideas:
- Can LLMs make the text information for each node better, so that regular graph models (called Graph Neural Networks, or GNNs) can do a better job? Think of LLMs as “enhancers.”
- Can LLMs skip the GNNs and make the predictions directly, just by reading the text and a description of the graph? Think of LLMs as “predictors.”
How they studied it (in plain language)
To understand the approach, let’s define a few terms in everyday language:
- Graph: Imagine a network of dots (nodes) connected by lines (edges). Each dot can have text attached, like a short description. Examples include:
- Citation graphs: nodes are papers; lines show which papers cite which.
- Product graphs: nodes are products; lines connect related products.
- Node classification: Given some labeled examples (e.g., “this paper is Computer Vision”), predict the labels for the rest.
- Embedding: Turning text into numbers a computer can work with—like translating a sentence into a list of values that capture its meaning.
- GNN (Graph Neural Network): A model that learns by letting each node “listen” to information from its neighbors, a bit like gossip spreading through a friend group.
- LLM: A very strong text reader and writer trained on huge amounts of text. Some LLMs let you extract their embeddings directly (embedding-visible). Others only let you chat with them (embedding-invisible).
The researchers tested two pipelines:
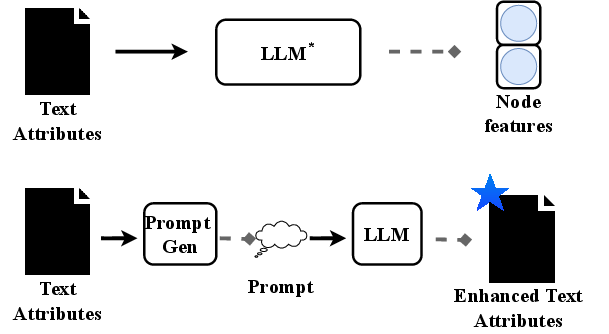
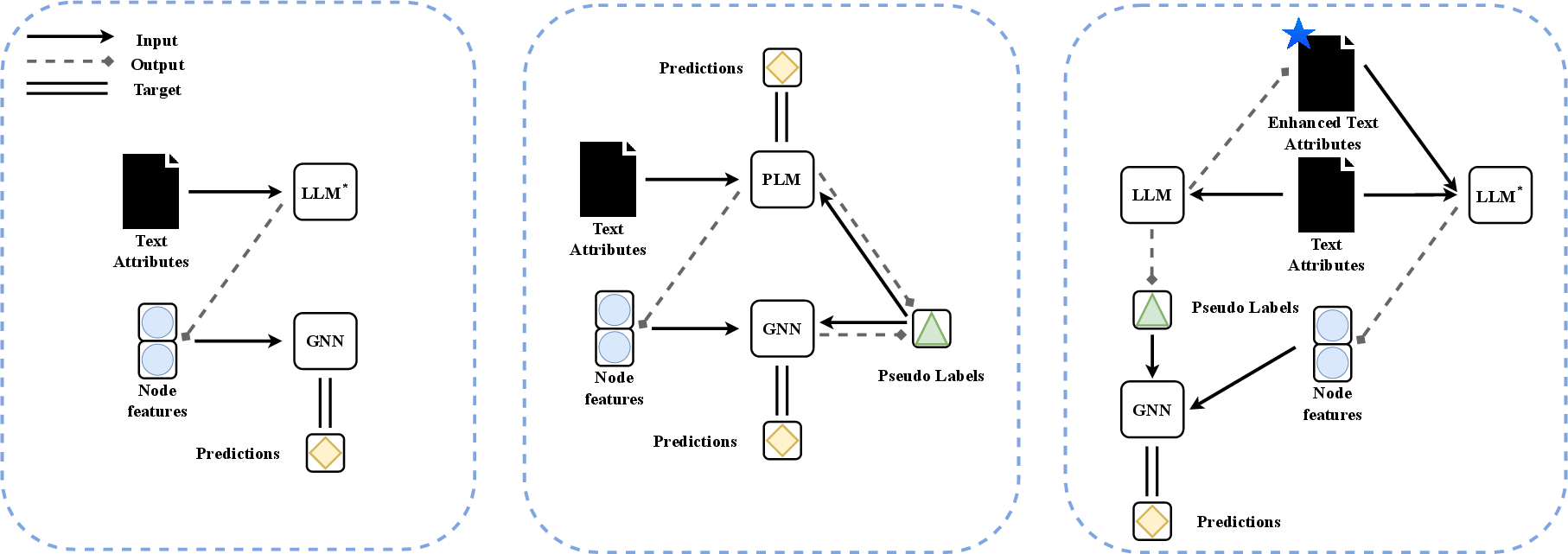
1) LLMs as Enhancers (LLMs help GNNs)
- Feature-level enhancement: Use LLMs to turn each node’s text into a high-quality embedding (a good numeric summary), then feed those embeddings to a GNN. Two ways to combine them:
- Cascading: First get text embeddings from a LLM, then train a GNN on top. Simple and fast.
- Iterative (like GLEM): Train a LLM and a GNN in turns, letting them help label data for each other. Strong, but slower and heavier.
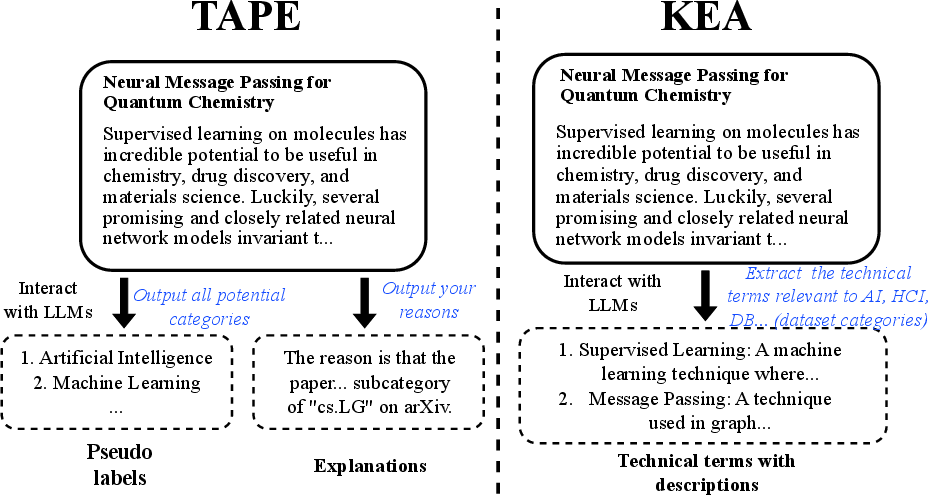
- Text-level enhancement: Ask powerful chat-based LLMs (like ChatGPT) to rewrite or add helpful information to the node text before turning it into embeddings. Two styles:
- TAPE: The LLM creates a guessed label and an explanation that connects the text to that label, making the meaning clearer.
- KEA (Knowledge-Enhanced Augmentation): The LLM adds relevant facts or short definitions (for example, explaining a technical term), enriching the original text.
In both cases, the improved text (or its embedding) is then given to a GNN to make final predictions.
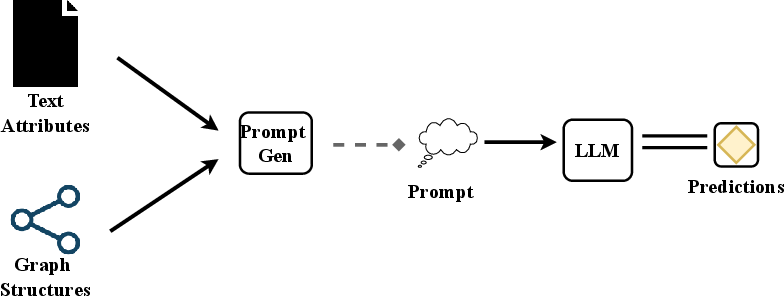
2) LLMs as Predictors (LLMs make predictions directly)
- Here, the graph structure, node text, and possible labels are written into a well-designed prompt (instructions) for an LLM. The LLM reads the prompt and outputs a predicted label. This avoids GNNs entirely but depends on careful prompt design and the LLM’s reliability.
What they tested on
They ran many experiments on well-known datasets like Cora, PubMed, Ogbn-Arxiv, and Ogbn-Products. They tried situations with few labeled examples (hard mode) and many labeled examples (easier mode). They measured accuracy and also looked at time and memory costs to see what’s practical.
What they found and why it matters
Here are the main takeaways and their importance:
- Deep sentence embedding models + GNNs are a strong and efficient combo.
- Models designed to produce high-quality sentence embeddings (like Sentence-BERT or e5) worked very well when plugged into a simple GNN. This setup is both effective and fast, making it a great baseline.
- Bigger isn’t always better.
- Just using a larger LLM (like a huge LLM) to create embeddings didn’t automatically beat specialized sentence embedding models. How a model is trained (its objective) matters, not just its size.
- Fine-tuning can struggle when you have few labels.
- When very little training data is labeled, trying to fine-tune a LLM often didn’t help and could even hurt. In low-label settings, prebuilt sentence embeddings tended to be safer and better.
- Iterative methods can be powerful but expensive.
- Letting a LLM and a GNN train each other (the iterative approach) sometimes gave top results when there were many labels, especially on big datasets. But it was much slower and used more memory.
- Text-level augmentation helps.
- Asking LLMs to add explanations (TAPE) or extra knowledge (KEA) often improved performance when those enriched texts were then embedded and fed into a GNN.
- LLMs as direct predictors: promising but risky.
- LLMs can sometimes predict well straight from a prompt, but they can also be inaccurate, and there’s a risk they’ve already “seen” the test data somewhere on the internet (test data leakage). So results here should be treated carefully.
- LLMs can help label data.
- Even if you don’t use an LLM for final predictions, it can be a useful assistant to create or suggest labels for nodes. A decent fraction of those labels were correct, which can speed up dataset creation.
Why this work matters and what could come next
- Practical advice: If you have text on your graph nodes, a simple, strong approach is to use a good sentence embedding model to encode the text and then apply a GNN. It’s efficient and works well, especially when labeled data is limited.
- When to use fancier methods: If you have lots of labeled data and enough computing power, iterative training (LLM + GNN helping each other) may squeeze out extra accuracy. If you can use chat-based LLMs, enriching the text (explanations or added knowledge) can help too.
- Caution with direct LLM prediction: While exciting, using LLMs alone to read prompts and predict labels is not yet consistently reliable. Be careful about data leakage and accuracy.
- Future directions:
- Better prompts to teach LLMs how to use graph structure.
- Safer ways to avoid test leakage.
- Smarter, cheaper ways to combine LLMs and GNNs.
- Using LLMs as labeling assistants to reduce human effort.
In short, LLMs are powerful helpers for graph learning with text, especially as enhancers that boost the input to GNNs. They’re not yet a full replacement for graph-specific models, but they open up new, promising paths.
Collections
Sign up for free to add this paper to one or more collections.

