- The paper introduces AmbigPrompt, an iterative prompting framework for generating diverse and accurate multi-answers in open-domain question answering.
- It leverages a retrospective prompting mechanism to progressively condition on previous answers, ensuring improved relevance and reduced computational cost.
- Experimental evaluations show AmbigPrompt outperforms baseline models on AmbigQA with significantly fewer parameters and lower latency, even in low-resource settings.
Iterative Prompting for Ambiguous Multi-Answer Question Answering
The paper addresses the challenge of open-domain question answering (QA) where ambiguity in the question often leads to multiple plausible answers, reflecting real-world usage scenarios where human questions are commonly underspecified. Traditional approaches, either generating all answers in a single pass or aggregating candidates from multiple passages, fail to balance relevance and diversity efficiently and often neglect inter-answer dependencies or incur substantial computational overhead.
Ambiguous QA is formally cast as finding multiple plausible answers A for a question q given a large corpus Ω. Passage retrieval yields evidence C used to infer A, emphasizing both precision (relevance) and recall (diversity).

Figure 1: An illustration of an open-domain question, its supporting Wikipedia passages, and the range of valid answers.
Methodology: AmbigPrompt Architecture
The main contribution is AmbigPrompt, an iterative prompting framework comprising an encoder-decoder answering model (FiD architecture) and a prompting model, which share parameters for seamless integration. Rather than generating all answers simultaneously, AmbigPrompt alternates between generating prompts conditioned on previously produced answers and composing new answers, progressively expanding the answer set.
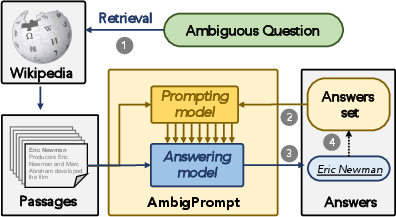
Figure 2: AmbigPrompt's workflow interleaves prompt generation based on prior answers and answer generation, appending each new answer to the output set.
This iterative loop is implemented via a retrospective prompting mechanism, where the prompting model generates continuous prompts E by cross-attending to prior answers and the context. The FiD encoder then prepends E to its attention layers, with the decoder producing subsequent answers conditioned on both context and introspective prompts.
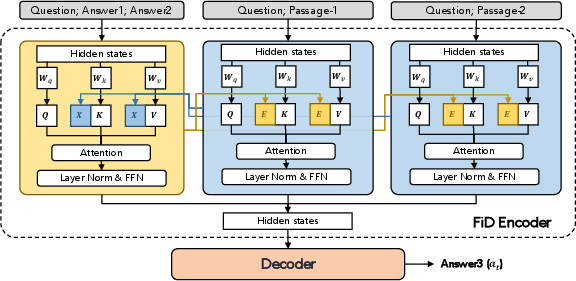
Figure 3: Retrospective prompting mechanism details, showing the cross-attention construction of prompting vectors E with answer context.
AmbigPrompt terminates generation once the "End of Iteration" token is produced, avoiding repeated answers and improving diversity.
Optimization and Task-Adaptive Pretraining
AmbigPrompt parameters are optimized in two stages:
- Task-adaptive post-pretraining: On synthesized multi-answer QA from single-answer datasets, pseudo-answers are generated via an auxiliary reader. The model is trained to predict answers conditioned on variable prior answer sets to induce robustness to answer dependencies and ordering.
- Prompt-based fine-tuning: On annotated multi-answer datasets, answers are shuffled, and the model is explicitly trained to output the termination token to stop iteration.
This optimization ensures the model generalizes effectively to multi-answer settings, including low-resource scenarios.
Experimental Evaluation and Results
AmbigPrompt is evaluated on AmbigQA and WebQSP benchmarks. On AmbigQA, it achieves an F1 of 48.7 (full set) and 38.8 (multi-answer subset), outperforming comparable baselines, including FiD and Refuel, in both accuracy and efficiency. AmbigPrompt uses only 220M parameters, significantly fewer than high-capacity models (e.g., RECTIFY at 6B), yet matches or surpasses them in performance and exhibits dramatically reduced latency and memory footprint.
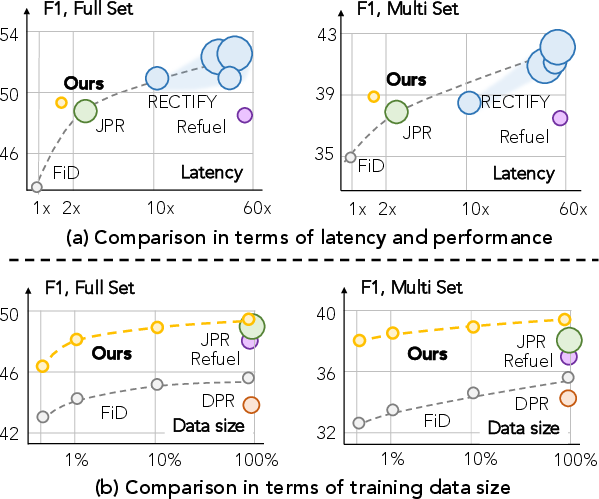
Figure 4: (a) Latency (log scale) vs. F1 on AmbigQA, demonstrating AmbigPrompt's superior performance-resource profile. (b) Dataset size vs. F1, showing robust performance in low-resource settings.
AmbigPrompt also excels when trained on limited data, maintaining strong performance versus baselines even in low-resource configurations. Ablation studies highlight the necessity of task-adaptive pretraining, answer-conditional prompting, and interleaving cross-attention; removal of any component degrades performance substantially.
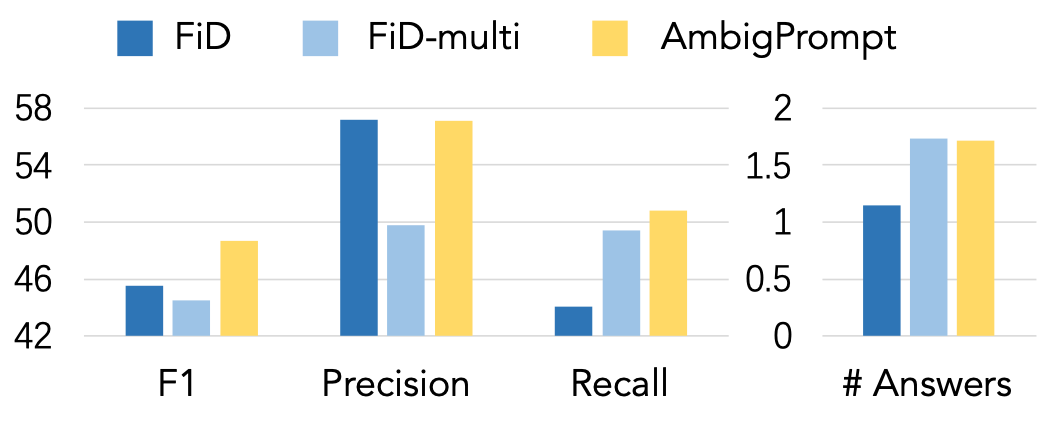
Figure 5: Comparative analysis of F1, Precision, Recall, and average answer count for AmbigPrompt versus FiD variants.
AmbigPrompt manages the relevance-diversity trade-off more effectively than FiD-multi, achieving higher precision without sacrificing recall and generating a balanced number of plausible answers.
Practical Implications and Theoretical Insights
AmbigPrompt demonstrates that iterative prompting with lightweight models enables efficient and accurate multi-answer QA without resorting to resource-intensive architectures. Its architecture conditions answer generation on introspective prompts, directly modeling dependencies and ensuring both diversity and relevance.
The approach can be extended to low-resource languages or domains where multi-answer annotation is sparse, as its prompting mechanism elicits knowledge from pre-trained models. Integrating chain-of-thought prompting or scaling to larger LLMs may further enhance performance, particularly in reasoning-intensive or high-complexity QA settings.
Conclusion
AmbigPrompt introduces a prompt-guided, iterative answer generation framework that addresses ambiguous open-domain questions by leveraging answer-conditioned continuous prompts and task-adaptive pretraining. The design achieves superior performance to both low- and high-capacity baselines with markedly reduced computational requirements. The iterative prompting paradigm offers a scalable, resource-efficient direction for future multi-answer QA systems and may inform broader prompting-based strategies for complex generative tasks in AI.