- The paper demonstrates a novel self-training method that iteratively refines pseudo-labels using a length-normalized confidence score.
- The methodology fine-tunes XLSR-53 on limited Punjabi data and integrates a 5-gram KenLM for improved decoding accuracy.
- Results show significant WER improvements across multiple datasets, validating self-training for enhancing low-resource ASR.
Self-Training Approach for Low-Resource ASR
The paper "A Novel Self-training Approach for Low-resource Speech Recognition" (2308.05269) introduces a self-training methodology to enhance ASR systems in low-resource languages, with a specific focus on Punjabi. The approach leverages a pre-trained crosslingual wav2vec 2.0 model (XLSR-53) as a seed model and iteratively refines pseudo-labels generated from unlabeled data using a length-normalized confidence score. This method aims to address the challenges posed by the scarcity of annotated speech data, which is a significant bottleneck in developing accurate ASR systems for languages like Punjabi.
Methodology
The proposed approach consists of several key steps, as illustrated in (Figure 1).
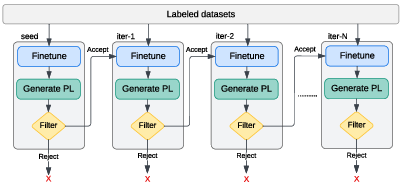
Figure 1: Overview of proposed self-training approach.
First, the XLSR-53 model is fine-tuned on a limited amount of labeled Punjabi data in a supervised fashion, incorporating LLM decoding. Subsequently, this fine-tuned model generates pseudo-labels for a large corpus of unlabeled audio data. To mitigate the impact of erroneous pseudo-labels, the authors introduce a length-normalized confidence score to filter out low-quality transcriptions. High-confidence pseudo-labels are then combined with the labeled data to retrain the ASR model from scratch. This iterative process is repeated with gradually relaxed confidence score thresholds to refine the pseudo-labels and improve the model's performance.
Seed Model and Pseudo-Labeling
The choice of the XLSR-53 model as the seed model is motivated by its ability to learn cross-lingual feature representations, which facilitates effective fine-tuning on new languages with limited labeled data. The use of a 5-gram KenLM LLM for decoding the seed model's outputs further enhances the accuracy of the generated pseudo-labels. The confidence-based scoring strategy plays a crucial role in filtering out inaccurate pseudo-labels, ensuring that only high-quality data is used for retraining the model. The iterative refinement of pseudo-labels with gradual relaxation of confidence score thresholds allows the model to progressively learn from a larger pool of unlabeled data while maintaining high accuracy.
Datasets
The authors use a combination of real and synthetic Punjabi speech datasets to train and evaluate the proposed self-training approach. The real speech datasets include Shrutilipi, Common Voice, Punjabi Speech, and 50Languages, while the synthetic datasets comprise Google-synth and CMU-synth. Additionally, a large unlabeled dataset of Punjabi audiobooks is used for self-training. The use of synthetic datasets is justified by previous findings demonstrating their effectiveness in improving the performance of Punjabi ASR systems (2308.05269).
Results
The experimental results demonstrate the effectiveness of the proposed self-training approach in improving the WER on various Punjabi speech datasets. The approach achieves relative improvements of 13.04\%, 18.66\%, 12.91\%, and 14.94\% on the real speech Shrutilipi, Common Voice, Punjabi Speech, and 50Languages datasets, respectively, compared to the baseline model. Notably, the approach achieves a 50.5\% relative improvement on the Common Voice Punjabi dataset compared to previously reported results. The performance of the model with different confidence score thresholds and the amount of PL data selected with filtration over multiple PL iterations are shown in (Figure 2).
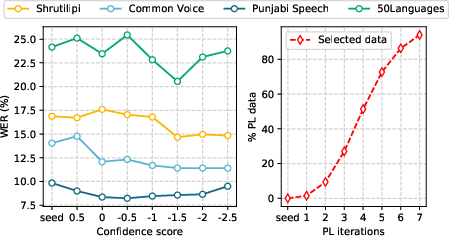
Figure 2: Performance on real speech datasets against various confidence score thresholds (left) and % of selected data over the PL iterations (right).
The results also indicate that using filtered pseudo-labels (Best PL) outperforms using all available pseudo-labels (Raw PL), highlighting the importance of selecting high-quality pseudo-labels for improving ASR performance. Furthermore, the experiments demonstrate that gradually relaxing the confidence score threshold over multiple iterations of self-training leads to better results than using a fixed threshold.
Conclusions
The work makes a compelling case for self-training as a viable approach to rapidly bootstrap ASR systems in low-resource scenarios. The use of a pre-trained crosslingual model, combined with a confidence-based filtering strategy and iterative refinement of pseudo-labels, offers a practical and effective solution for leveraging unlabeled data to improve ASR performance. The results on the Punjabi language demonstrate the potential of the approach to address the challenges posed by the scarcity of annotated speech data in low-resource languages. The use of confidence score thresholds is a simple but effective way to improve performance. Future research could focus on exploring more sophisticated methods for filtering and weighting pseudo-labels, as well as investigating the use of different pre-training strategies and LLM architectures.