- The paper introduces a self-supervised method using CLIP to map semantic descriptors to 3D morphable model parameters.
- It employs a novel slider-based interface and zero-shot image-to-shape reconstruction to enhance interactivity in 3D design.
- Experimental results on human and animal models reveal competitive performance and improved usability over traditional methods.
Semantify: Simplifying the Control of 3D Morphable Models using CLIP
Introduction
The paper "Semantify: Simplifying the Control of 3D Morphable Models using CLIP" proposes a novel self-supervised methodology leveraging the CLIP model to enhance the control over 3D Morphable Models (3DMMs). The challenge with current 3DMMs lies in their reliance on abstract parameter spaces lacking semantic interpretability. To address this issue, the authors utilize CLIP's semantic comprehension to map between intuitive descriptors and 3DMM parameters, providing an interactive interface for 3D design.
Methodology
The proposed method begins by generating a diverse dataset through the random sampling of 3DMM parameter spaces to create a range of shapes, which are subsequently rendered as images. These images are coupled with semantic descriptors encoded by CLIP into a latent space to generate similarity scores. A critical step involves choosing semantically meaningful and disentangled descriptors using a combination of clustering and variance analysis to ensure coverage and minimal correlation.
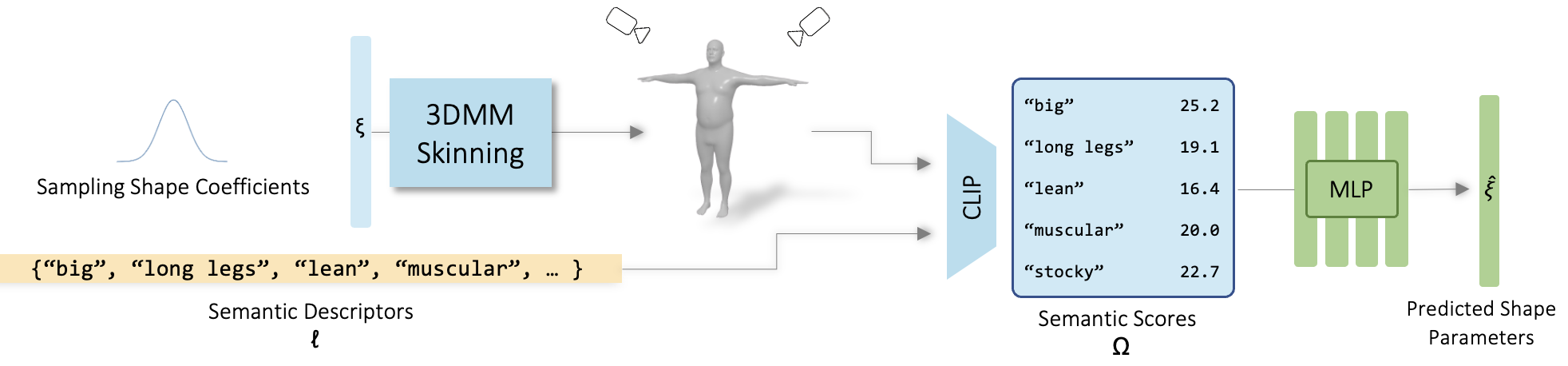
Figure 1: Learning a mapping from Semantic to Parametric space.
Once descriptors are selected, a neural network is trained to map the similarity scores to the 3DMM coefficients. This mapping is performed without manual intervention, relying entirely on the self-supervised capabilities provided by the CLIP model.
Interactive Application
Semantify creates an intuitive slider-based interface for manipulating 3D models. Each slider corresponds to a semantic descriptor, allowing users to adjust parameters interactively, with real-time feedback on the 3D output. This approach not only simplifies the modeling process but also enhances creativity and precision, particularly useful for users lacking expertise in 3D design.

Figure 2: Models created using an interactive slider application for SMAL [Zuffi:CVPR:2017].
Zero-Shot Image to Shape Reconstruction
A significant application of this research is in zero-shot image-to-shape reconstruction. By encoding images with CLIP and utilizing the trained neural network, the method predicts the 3D shape corresponding to a given image. It provides an initial prediction that can be fine-tuned using the interactive interface, offering a practical tool for rapid prototyping and design iteration.
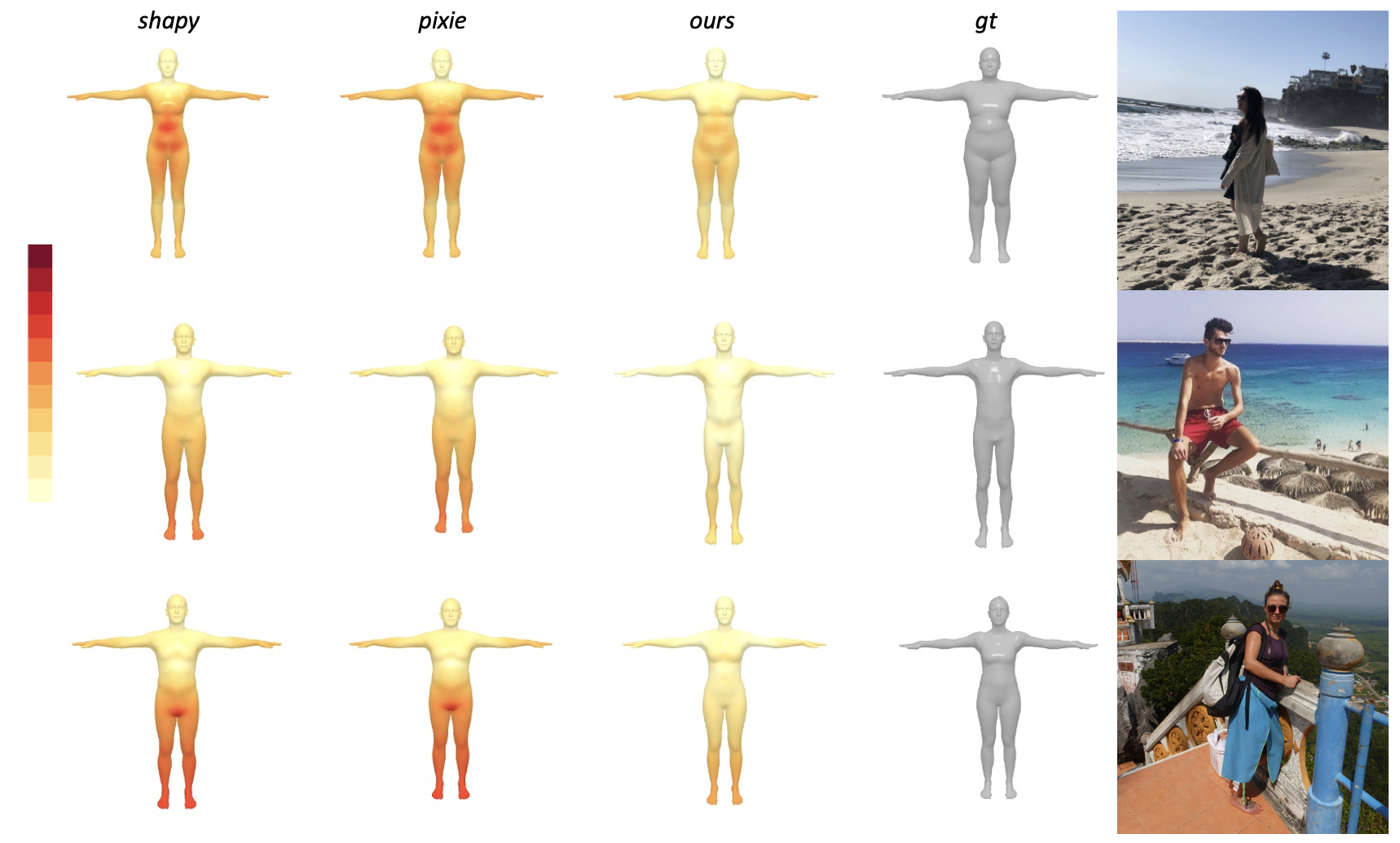
Figure 3: Results of zero-shot image to shape reconstruction, comparing Semantify against SHAPY and PIXIE on SMPLX 3DMM.
Experimental Results
The experiments demonstrate the effectiveness of the method across multiple 3DMMs, including human and animal models. Semantify shows competitive performance in zero-shot tasks when compared to state-of-the-art methods like SHAPY and PIXIE, with the added benefit of semantic tunability. User studies indicate higher usability and precision with the slider interface compared to traditional methods.
Implications and Future Work
This research has significant implications for designing 3D interfaces and tools. By integrating semantic understanding into 3D modeling, it lowers the barrier for artists and designers, potentially revolutionizing workflows in industries such as gaming, animation, and virtual reality. Future work could explore enhancing the zero-shot prediction capabilities by incorporating contextual priors or improving dataset sampling techniques to cover more extreme shapes without compromising realism.
Conclusion
Semantify provides a novel methodology for controlling 3DMMs using semantically intuitive controls. The integration of language-vision models like CLIP represents a profound shift towards more accessible and efficient 3D design processes. With ongoing advancements, this approach continues to bridge the gap between technical 3D frameworks and user-friendly design interfaces.