Synergi: A Mixed-Initiative System for Scholarly Synthesis and Sensemaking
Abstract: Efficiently reviewing scholarly literature and synthesizing prior art are crucial for scientific progress. Yet, the growing scale of publications and the burden of knowledge make synthesis of research threads more challenging than ever. While significant research has been devoted to helping scholars interact with individual papers, building research threads scattered across multiple papers remains a challenge. Most top-down synthesis (and LLMs) make it difficult to personalize and iterate on the output, while bottom-up synthesis is costly in time and effort. Here, we explore a new design space of mixed-initiative workflows. In doing so we develop a novel computational pipeline, Synergi, that ties together user input of relevant seed threads with citation graphs and LLMs, to expand and structure them, respectively. Synergi allows scholars to start with an entire threads-and-subthreads structure generated from papers relevant to their interests, and to iterate and customize on it as they wish. In our evaluation, we find that Synergi helps scholars efficiently make sense of relevant threads, broaden their perspectives, and increases their curiosity. We discuss future design implications for thread-based, mixed-initiative scholarly synthesis support tools.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Synergi, a smart research helper that works with you to make sense of lots of scientific papers. It helps you build a clear outline of “research threads” (big ideas and sub-ideas in a topic) by combining what you find interesting with what the AI can discover and organize. Think of it as a mixed-initiative system: you guide it, and it organizes and summarizes—like teaming up with a very organized friend.
What questions were the researchers trying to answer?
The authors asked:
- Can a system that mixes human input and AI help people review scientific literature faster and better?
- Can it find and organize the most relevant papers based on the exact paragraph you’re curious about?
- Will this approach make people more confident and curious when learning a new research area?
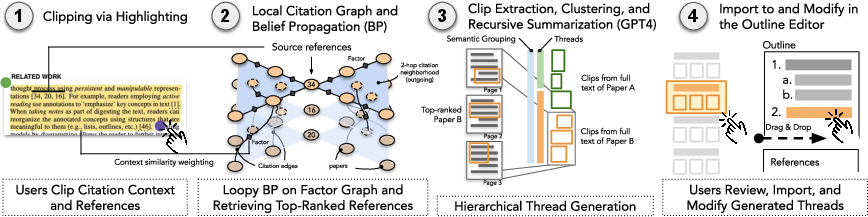
How does Synergi work?
Here’s the process in everyday terms:
- You highlight a part of a paper (like a paragraph in the Introduction or Related Work) that mentions other papers. This “clip” becomes your starting point.
- Synergi looks at a “citation graph”—a web showing which papers cite which others. Imagine a social network of papers: a paper’s “friends” are the papers it cites; “friends-of-friends” are two steps away.
- It runs a technique called “Loopy Belief Propagation” (LBP). Picture passing notes through that network to figure out which papers are most likely to be important for your exact paragraph. It favors papers that:
- Are talked about in similar ways by other scientists (similar citation context), and
- Build on similar sets of references (they’re part of the same “thread”).
- Synergi finds PDFs of the top-ranked papers and pulls out the most relevant bits—usually the sentences where other authors summarize or compare past work (great for learning).
- It turns those sentences into numbers (embeddings) to measure similarity. This is like checking how close two song playlists are by their vibe.
- It groups similar pieces together using “agglomerative clustering.” Picture sorting puzzle pieces into piles that fit together, then building a small “family tree” of topics: big themes at the top, sub-themes below, and specific examples at the bottom.
- It asks an AI (GPT-4) to write short labels for each group—clear, 6-words-or-less titles that capture the core idea.
- In the interface, you see a color-coded, 3-level outline of research threads. You can drag and drop the ones you like into your own outline, and you can hover over references to see quick info cards. Everything keeps track of sources, so you can verify the evidence.
What did they find, and why is it important?
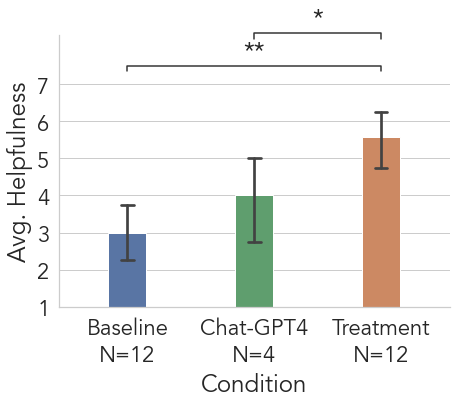
The authors ran a study with researchers and also asked domain experts (experienced PhD students) to judge the quality of the outlines people made. They compared Synergi to:
- A baseline tool (Threddy) where people manually collect and organize highlighted clips, and
- A pure chatbot (Chat-GPT4) that writes an outline for you.
Main results:
- Outlines made with Synergi were rated the most helpful by experts.
- Synergi’s threads were supported by stronger, more visible evidence (clear citations and exact text excerpts), making them more trustworthy than the chatbot’s outputs.
- Participants said Synergi helped them explore more broadly, understand big research themes faster, and feel more curious and confident.
- Synergi was more efficient than doing everything manually and more structured and verifiable than relying only on a chatbot.
Why this matters:
- Scientists and students are overwhelmed by the number of papers. Synergi helps turn scattered information into a clear map, backed by sources you can check.
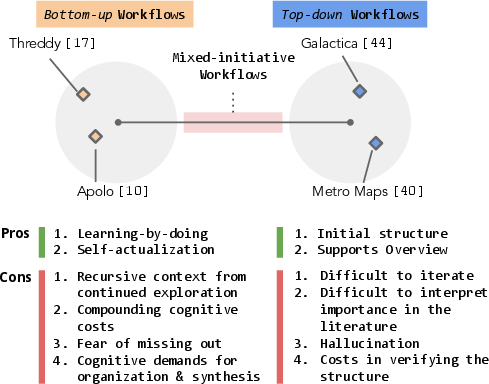
- It blends the best of both worlds: your judgment and goals (bottom-up) with AI-generated structure and suggestions (top-down), so you can iterate and personalize.
What’s the impact?
Synergi shows a practical way to use AI in research without making it a black box:
- It can help researchers and students learn new topics faster and more confidently.
- It reduces the chance of blindly trusting AI summaries because every thread includes where the info came from.
- It suggests a design pattern for future tools: let humans point the way, and let AI do the heavy lifting of finding, grouping, and labeling—with built-in ways to inspect and verify.
In simple terms: Synergi is like a smart, organized study buddy for science. You choose the interesting starting point; it builds a reliable, easy-to-explore roadmap of the research landscape, so you can think bigger, learn faster, and trust what you find.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Lack of ablation studies on the retrieval pipeline: no systematic comparison of the proposed LBP with message weighting against simpler/stronger baselines (e.g., BM25/ SPLADE/ dense retrieval, co-citation/bibliographic coupling, Personalized PageRank, HITS, or hybrid approaches).
- No sensitivity analysis of key retrieval hyperparameters (2-hop neighborhood depth, per-hop cap of 50, top-30 candidate selection, message weights, damping) on coverage, precision, and stability of retrieved sets.
- Absence of error/coverage metrics for the retrieval stage (e.g., precision/recall against a curated ground-truth topic taxonomy or expert gold sets; missed-relevant vs. over-included papers).
- Potential popularity and recency bias in citation-graph-based retrieval (favoring well-cited/older works); no debiasing or novelty-seeking mechanisms evaluated.
- Context-sensitivity objective is unvalidated: the multiplicative message weighting combining citation-context similarity and reference overlap lacks quantitative justification and comparative alternatives (e.g., learned weights, non-multiplicative combinations).
- Unclear convergence behavior and runtime costs of LBP at scale; no report of latency, computational footprint, or scalability beyond local 2-hop neighborhoods on larger, denser domains.
- Reliance on citation contexts may skew toward authors’ narratives and positive or conventional framings; no treatment of stance detection (supporting vs. contrasting citations) or mechanisms to surface minority/contradictory threads.
- PDF acquisition and parsing pipeline reliability is unquantified: no success rate, parsing accuracy (GROBID), or impact analysis of failures/fallbacks (title/abstract only) on downstream synthesis.
- Dependency on S2ORC/Google Custom Search introduces coverage and licensing/copyright uncertainties; ethical, legal, and reproducibility implications are not discussed.
- Single embedding model choice (text-ada-002) and fixed similarity threshold (0.80) lack justification; no comparison with newer embedding models, threshold tuning strategies, or domain-adaptive embeddings.
- No multilingual support or evaluation; unclear performance on non-English papers or mixed-language corpora.
- Agglomerative clustering and 3-level tree-cutting heuristics are unvalidated; no comparison with alternative clustering/structuring methods (e.g., HDBSCAN, spectral, topic models) or learned hierarchical structuring.
- Recursive GPT-4 labeling lacks quality assurance: no human evaluation of label faithfulness, specificity, and non-hallucination; no constraints or verification on label–child coherence.
- No mechanism to detect or correct GPT-4 hallucinations in labels or merged threads; provenance display exists but is not leveraged for automated verification.
- Post-processing thread merging is heuristic; no quantitative assessment of over- or under-merging and its impact on outline usability and correctness.
- The interface encourages grouping by frequency (group-by-reference, color-coded similarity), which may amplify popularity bias; no experiments testing whether this biases users’ selections or suppresses novel/edge-case work.
- Limited evaluation scope: 12 participants (mainly HCI/NLP) and two pre-defined topics; results may not generalize to other disciplines, interdisciplinary topics, or expert populations.
- Expert assessment focuses on “helpfulness” and perceived support quality, not factual correctness, coverage/recall, or alignment to field taxonomies; no gold-standard benchmarking.
- Timed tasks with provided seed clips may advantage systems seeded with that context; external validity to unconstrained, longer-term reviews is unknown.
- No longitudinal or in-the-wild studies assessing learning gains, trust calibration, sustained adoption, or integration into real research workflows (weeks/months).
- Chat-GPT4 baseline is non-interactive and not retrieval-augmented; lacks parity with modern RAG or tool-augmented LLM baselines, weakening comparative claims.
- Absence of user-controlled mixed-initiative loops in retrieval (e.g., critique, reweighting, relevance feedback) to iteratively steer results; open question: how best to incorporate interactive relevance feedback into LBP and clustering.
- No analysis of sensitivity to seed selection quality/quantity (few vs. many clips; noisy vs. high-quality clips); robustness to sparse or adversarial seeds is unknown.
- No coverage of contradiction mapping: identifying and summarizing competing theories/methods or unresolved debates; future work could include stance-aware clustering.
- Limited treatment of interdisciplinarity: two-hop graphs centered on seed citations may miss bridging work across fields; open question: how to incorporate cross-domain signals (venues, keywords, author communities).
- No evaluation of cognitive load beyond NASA-TLX; missing fine-grained measures of verification effort (time to verify claims, source-follow-through rates).
- Lack of fairness/bias audits: potential underrepresentation of marginalized communities, less-cited venues, non-English or paywalled literature not assessed.
- Unreported failure modes in UI (drag-and-drop errors, misplacements) and their effect on outline quality; no usability error logs or mitigation strategies.
- No automatic de-duplication or disambiguation analysis (author name variants, preprint vs. published versions) and its potential to fragment threads.
- No mechanism to capture or visualize uncertainty/confidence per thread (e.g., confidence scores from retrieval/labeling) to guide verification.
- Absence of domain adaptation/personalization beyond initial seeds; open question: how to learn user-specific thread taxonomies or focus preferences over time.
- No comparative study of different provenance presentations (e.g., inline evidence snippets vs. expandable contexts) on trust and verification efficiency.
- Latency and throughput of the end-to-end pipeline (retrieval, parsing, embedding, clustering, GPT-4 labeling) are not reported; scalability to larger batches or team use is unknown.
- Data and code availability not stated; reproducibility of results and portability to other corpora remain open.
- Security/privacy considerations are unaddressed (e.g., handling of unpublished PDFs, institutional access, user-uploaded notes/clips).
Practical Applications
Overview
Below are actionable, real-world applications that leverage the paper’s core innovations: a mixed-initiative workflow for scholarly synthesis combining (1) context-sensitive retrieval over 2-hop citation graphs via Loopy Belief Propagation (LBP), (2) embedding-based filtering and agglomerative clustering with tree-cutting, (3) recursive GPT-based summarization with provenance-preserving citation contexts, and (4) an interactive, drag-and-drop outline editor. Applications are grouped into Immediate (deployable now) and Long-Term (requiring further research, scaling, or adaptation), with sector links, potential tools/products/workflows, and feasibility notes.
Immediate Applications
These can be deployed with currently available citation APIs, PDF parsing, embeddings, and LLMs, as demonstrated by the system’s evaluation.
Academia and Research
- Rapid literature review and outline drafting for researchers and students (Academia)
- What: Generate thread-structured, evidence-linked outlines for new topics, scoping reviews, and related work sections.
- Tools/workflows: “Synergi for Zotero/Semantic Scholar” plugin; Overleaf/Docs add-on for importing thread hierarchies with inline citations.
- Dependencies/assumptions: Access to Semantic Scholar/S2ORC; consistent PDF availability and parse quality (GROBID); LLM API availability/costs; best suited to domains with strong citation practices and English-language prevalence.
- Grant and proposal preparation support (Academia)
- What: Map prior art and open problems; prioritize high-signal references by thread frequency to inform significance and innovation sections.
- Tools/workflows: “Grant Outline Assistant” that outputs structured sections plus a prioritized reading list.
- Dependencies/assumptions: Timely retrieval in fast-moving areas; coverage of preprints; reviewers may require manual verification despite provenance.
- Peer review and meta-review triage (Academia/Publishing)
- What: Quickly situate a submission within existing threads; surface key related work and claims with provenance.
- Tools/workflows: Editorial dashboard that generates a “related work threads” panel per submission.
- Dependencies/assumptions: Journal/publisher access policies; careful handling of blind review constraints.
- Research onboarding and group knowledge transfer (Academia/Labs)
- What: Produce thread maps for lab newcomers; maintain living outlines for lab topics with evidence snippets.
- Tools/workflows: Lab wiki integration; “Group-by-reference” view to plan reading groups.
- Dependencies/assumptions: Regular refresh needed; institutional single sign-on (SSO) integration for persistent storage.
- Library services augmentation (Academic Libraries)
- What: Support literature consultations by generating thread-based maps for patrons’ topics with link-outs to holdings.
- Tools/workflows: Librarian console and patron handouts; export to LibGuides.
- Dependencies/assumptions: Link resolver/holdings integration; licensing restrictions for full-text access.
Industry and Enterprise R&D
- Technology scouting and competitive landscape mapping (Software, Energy, Robotics)
- What: Identify clusters of methods, key players, and seminal works; organize them into actionable threads with citations.
- Tools/workflows: “R&D Scout” portal combining publication and known patent citations (phase one with publications only).
- Dependencies/assumptions: Sector coverage in scholarly databases; patent integration would be basic unless extended; IP-sensitive data excluded unless on-prem.
- Patent landscaping and prior-art triage (IP/R&D)
- What: Use the citation-graph and context-weighting approach to triage related scholarly works that intersect with patents’ citations.
- Tools/workflows: Analyst console linking patent citations to scholarly thread hierarchies.
- Dependencies/assumptions: Requires ingestion of patent-office citation graphs for full benefit; legal review mandatory; initial version limited to scholarly citations.
- Technical due diligence and M&A research (Finance/Corporate Strategy)
- What: Generate evidence-backed tech maps for target domains to inform diligence questions.
- Tools/workflows: Report builder that exports thread hierarchies with provenance as appendices.
- Dependencies/assumptions: Coverage gaps for proprietary tech; need on-prem deployment for sensitive targets.
Healthcare and Public Health
- Scoping reviews and horizon scanning (Healthcare/Public Health)
- What: Rapidly assemble evidence threads (not full systematic reviews) for committees and working groups.
- Tools/workflows: “Thread-based Evidence Explorer” that compiles citation contexts by subtopic.
- Dependencies/assumptions: Not a substitute for PRISMA-grade systematic reviews; requires manual bias assessment and database coverage beyond S2ORC for clinical domains (e.g., PubMed, Cochrane).
- Pharmacovigilance literature triage (Pharma/Drug Safety)
- What: Organize emerging safety-signal literature into topic threads for human review.
- Tools/workflows: Signal triage dashboard linking to full-text contexts.
- Dependencies/assumptions: Needs domain databases (PubMed/EMBASE); regulatory-grade processes still required.
Policy and Government
- Evidence briefs for policymakers (Government/NGOs)
- What: Threaded literature maps for questions like AI impacts or education interventions, with traceable sources.
- Tools/workflows: Policy brief generator with export to memo formats.
- Dependencies/assumptions: Provenance helps credibility; must disclose limitations and confirmatory checks.
- Funding portfolio scans for program officers (Research Agencies)
- What: Identify gaps and clusters in funded areas; connect to external literature threads.
- Tools/workflows: Internal dashboard combining project abstracts and external publications (phase one with external publications).
- Dependencies/assumptions: Integration with internal grant databases for full value.
Education and Daily Life
- Course preparation and reading list curation (Education)
- What: Build modular reading lists by thread for courses or modules; include citation contexts for class discussion.
- Tools/workflows: Instructor tool that exports reading packets with thread summaries.
- Dependencies/assumptions: Instructor oversight; access to subscribed content.
- Student research assignments and thesis planning (Education)
- What: Outline generation with evidence snippets to guide exploration and reduce “where do I start?” friction.
- Tools/workflows: Classroom deployment with academic integrity guardrails (provenance display, reflective prompts).
- Dependencies/assumptions: Clear policies on AI-assisted research; LLM access costs.
- Science journalism and communication backgrounders (Media)
- What: Rapidly map a field’s major threads with canonical references for story prep.
- Tools/workflows: Reporter console with export to briefs.
- Dependencies/assumptions: Journalists must validate; coverage biases and non-English gaps.
Long-Term Applications
These require additional research, domain adaptation, scaling, or integration beyond the current scholarly-citation focus.
Cross-Domain Generalization Beyond Scholarly Citations
- Legal case-law synthesis (Legal)
- What: Replace paper citation graphs with legal citation networks; generate thread maps of legal doctrines with case contexts.
- Tools/workflows: “Legal Threads” assistant for litigators and clerks.
- Dependencies/assumptions: Access to legal corpora; domain-tuned embeddings/LLMs; strict confidentiality and licensing constraints.
- Financial research and regulatory filings synthesis (Finance)
- What: Build thread hierarchies from analyst reports, 10-Ks/10-Qs, and research notes (non-standardized citations).
- Tools/workflows: “Earnings & Risk Threads” for equity research and risk teams.
- Dependencies/assumptions: Weak/implicit citation conventions; needs entity/relation extraction and custom graphs.
- Standards/RFCs and open-source ecosystem mapping (Software/Networking)
- What: Use references in RFCs, OSS issues/PRs, and academic work to map evolution of standards and implementations.
- Tools/workflows: Standards navigator for PMs and architects.
- Dependencies/assumptions: Heterogeneous document formats and references; repository-scale data ingestion.
Evidence-Based Medicine and Systematic Review Automation
- Living systematic reviews with bias/quality assessment (Healthcare)
- What: Augment the pipeline with study-type detection, risk-of-bias scoring, and inclusion/exclusion tracking.
- Tools/workflows: “Synergi-EBM” with PRISMA-compliant workflows and audit trails.
- Dependencies/assumptions: Integration with clinical databases (e.g., PubMed, Cochrane, EMBASE); validated bias models; human-in-the-loop review.
Organizational Memory and Private-Corpus Synthesis
- Enterprise knowledge graph and “institutional memory” (All sectors)
- What: Apply thread synthesis to internal documents (wikis, reports, tickets) for cross-team sensemaking.
- Tools/workflows: On-prem deployment integrated with identity/permissions; connectors for SharePoint/Confluence/GitHub.
- Dependencies/assumptions: Data governance, access controls, PII/IP protection; custom graph construction beyond citations.
- Autonomous research agents for continuous monitoring (All sectors)
- What: Agents that detect new publications, update thread hierarchies, and ping owners when significant shifts occur.
- Tools/workflows: Alerting and diff views; quarterly landscape updates.
- Dependencies/assumptions: Stable APIs and rate limits; model drift monitoring; human oversight.
Advanced UI/UX and Methodological Enhancements
- Multimodal evidence extraction and summarization
- What: Incorporate figures/tables/equations into thread summaries for methods and results fidelity.
- Tools/workflows: Enhanced PDF parsers and table/figure OCR with structured outputs.
- Dependencies/assumptions: Reliable multimodal extraction; LLMs tuned for scientific interpretations.
- Active learning and personalization loops
- What: Learn a user’s preferences (e.g., methodological rigor, recency bias) to steer retrieval and clustering.
- Tools/workflows: Preference knobs and feedback-driven re-ranking.
- Dependencies/assumptions: Sufficient interaction signals; explainability for trust.
- Deeper provenance and veracity guarantees
- What: Citation-context alignment with sentence-level grounding and contradiction detection.
- Tools/workflows: Provenance badges; claim-evidence validation modules.
- Dependencies/assumptions: Accurate citation resolution; fact-checking model reliability.
Platformization and Ecosystem Integration
- Open APIs and plugin ecosystem
- What: Expose retrieval, clustering, and outline generation via APIs; plugins for Zotero, Notion, Slack, Overleaf.
- Tools/workflows: SDKs and webhooks for custom pipelines.
- Dependencies/assumptions: Stable model endpoints; usage-based cost control.
- On-premise and air-gapped deployments
- What: Deploy within secure networks for IP-sensitive organizations (e.g., pharma, defense).
- Tools/workflows: Containerized services; replace external LLMs with local models.
- Dependencies/assumptions: Availability of viable on-prem LLMs/embeddings; compute provisioning and maintenance.
Notes on Feasibility and Risks (Common Across Applications)
- Provenance reduces but does not eliminate hallucination risk; human verification remains essential.
- Coverage limitations (discipline bias, non-English content, paywalled PDFs) can affect recall and quality.
- Two-hop citation neighborhood and similarity thresholds may miss fringe/novel work; parameter tuning and user controls help.
- PDF parsing errors and inconsistent citation formats degrade context quality; fallback to titles/abstracts is a mitigation.
- Operational costs (LLM tokens, embeddings, PDF parsing at scale) and API rate limits must be managed.
- Evaluation to date is in HCI contexts; generalization to other disciplines requires validation and domain adaptation.
Glossary
- 2-hop citation neighborhood: The set of papers reachable within two citation steps (following references or incoming citations) from a seed paper in a citation graph. "the system dynamically fetches the 2-hop citation neighborhood using each of the seed references in both directions (i.e., incoming citations and references) using the Semantic Scholar APIs~\cite{kinney2023semantic}."
- Agglomerative clustering: A bottom-up hierarchical clustering method that iteratively merges the most similar clusters to form a tree. "Synergi constructs a hierarchical structure from them using a unsupervised agglomerative clustering with the Ward linkage."
- Boundary objects: Shared, flexible artifacts that enable coordination and mutual understanding across different stakeholders or systems. "Threads serve as boundary objects, translating user interests during literature exploration into signals"
- Citation context: The surrounding text in a paper that explains how a cited work is being referenced or used. "the pipeline uses GROBID~\cite{grobid} to parse the PDF and extract the citation contexts along with metadata"
- Citation graph: A directed graph where nodes are scholarly papers and edges indicate citation relationships among them. "via Loopy Belief Propagation over a local 2-hop citation graph from the seed references"
- Citation intent: The purpose or role a citation serves (e.g., background, method use), identified by analyzing the citation context. "We used the S2ORC dataset~\cite{S2ORC} covering multiple citation intents for comparison."
- Cosine similarity: A metric that measures similarity between vectors (e.g., text embeddings) by the cosine of the angle between them. "filtered those that have a higher average cosine similarity to seed clips than #1{0.80}"
- Factor graph: A bipartite graphical model that represents variables and factors (constraints) to facilitate inference algorithms like belief propagation. "we construct our factor graph with each unique candidate paper as a variable and use the citation edges as factors connecting the variables."
- Footnote chasing: A literature discovery practice of following references cited in a paper to find prior related work. "forward and backward citation chasing and footnote chasing as integral parts for scholars traversing citation graphs to discover important papers related to a research problem~\cite{palmer2009scholarly}."
- GROBID: An open-source tool for extracting and structuring metadata and citations from scholarly PDFs. "the pipeline uses GROBID~\cite{grobid} to parse the PDF"
- LLMs: Large-scale neural LLMs that can understand and generate human-like text. "recent systems' advances in LLMs such as Galactica~\cite{taylor2022galactica}, ChatGPT and Google Bard demonstrate impressive capabilities in answering user questions"
- Latin Square: An experimental design for counterbalancing order effects where each condition appears exactly once in each row and column. "We counterbalanced the order of presentation using 6 Latin Square blocks and randomized rows."
- Likert scale: A commonly used psychometric scale for survey responses indicating levels of agreement or frequency. "on a 7-point Likert scale"
- Loopy Belief Propagation (LBP): An approximate inference algorithm that passes messages on graphs with cycles to estimate marginal distributions. "Loopy Belief Propagation (LBP)~\cite{bp} is a message-passing algorithm well-suited for iterative sensemaking over graphs that may contain cycles."
- Mixed-initiative: An interaction paradigm in which both humans and automated systems can proactively take initiative to advance a task. "Synergi, a novel mixed-initiative workflow consisting of retrieval and organizational algorithms and interaction features to support scholarly synthesis."
- NASA-TLX: A standardized instrument to assess perceived workload across dimensions like mental demand, physical demand, and effort. "Demand (both physical and cognitive) and overall performance were measured using the validated 6-item NASA-TLX scale~\cite{nasa_tlx}"
- Provenance: The documentation of the origins and history of data or content that enables verification and traceability. "Synergi-generated threads maintain rich provenance and context to help users relate and inspect them further"
- Semantic Scholar APIs: Programmatic interfaces for retrieving scholarly metadata and citation information from the Semantic Scholar platform. "using the Semantic Scholar APIs~\cite{kinney2023semantic}"
- Sensemaking: The process of collecting, organizing, and interpreting information to build understanding and inform decisions. "Loopy Belief Propagation (LBP)~\cite{bp} is a message-passing algorithm well-suited for iterative sensemaking over graphs"
- Soft clustering: A clustering approach where items can belong to multiple clusters, often with probabilistic memberships. "supporting soft clustering (allowing each paper to belong to more than one research topics; see also Related Work in~\cite{apolo} for additional discussions of the algorithm's advantages over alternatives)."
- S2ORC: The Semantic Scholar Open Research Corpus, a large dataset of scholarly papers with metadata and, where available, full text. "the pipeline initially searches the S2ORC corpus~\cite{S2ORC} to see whether a corresponding full text PDF URL is available for each paper."
- Technology Acceptance Model (TAM): A theoretical model that explains user adoption of technology based on perceived usefulness and ease of use. "we included a modified Technology Acceptance Model survey from~\cite{tam_survey} (4 items)."
- Text embeddings: Vector representations of text that capture semantic information for tasks like retrieval and clustering. "Synergi embedded the extracted citation contexts using #1{text-ada-002}, and filtered those that have a higher average cosine similarity"
- Ward linkage: A criterion for hierarchical clustering that merges clusters to minimize the increase in within-cluster variance. "using a unsupervised agglomerative clustering with the Ward linkage."
Collections
Sign up for free to add this paper to one or more collections.