- The paper presents a novel benchmark, SciEval, that evaluates LLMs using Bloom's taxonomy across disciplines like chemistry, physics, and biology.
- It introduces a multi-level evaluation system that assesses knowledge, application, scientific calculation, and research ability through static, dynamic, and experimental data.
- Experimental results reveal gaps in knowledge application and higher-order cognitive tasks, emphasizing the need for refined data generation and evaluation strategies.
Overview of "SciEval: A Multi-Level LLM Evaluation Benchmark for Scientific Research"
The paper "SciEval: A Multi-Level LLM Evaluation Benchmark for Scientific Research" introduces a novel benchmark specifically designed to evaluate the performance of LLMs in scientific research contexts. SciEval aims to address the limitations of existing benchmarks, which are often restricted to objective questions and vulnerable to data leakage. This benchmark incorporates a multi-disciplinary approach, grounded in Bloom's taxonomy, to assess various cognitive capabilities of LLMs in scientific domains, notably chemistry, physics, and biology.
Evaluation System and Cognitive Dimensions
The SciEval benchmark uses Bloom's taxonomy as a foundation for its evaluation system, which spans four primary dimensions: Basic Knowledge, Knowledge Application, Scientific Calculation, and Research Ability. These dimensions are mapped to different cognitive levels, enabling a comprehensive assessment of LLMs’ ability to recall, understand, apply, analyze, evaluate, and create based on scientific principles.
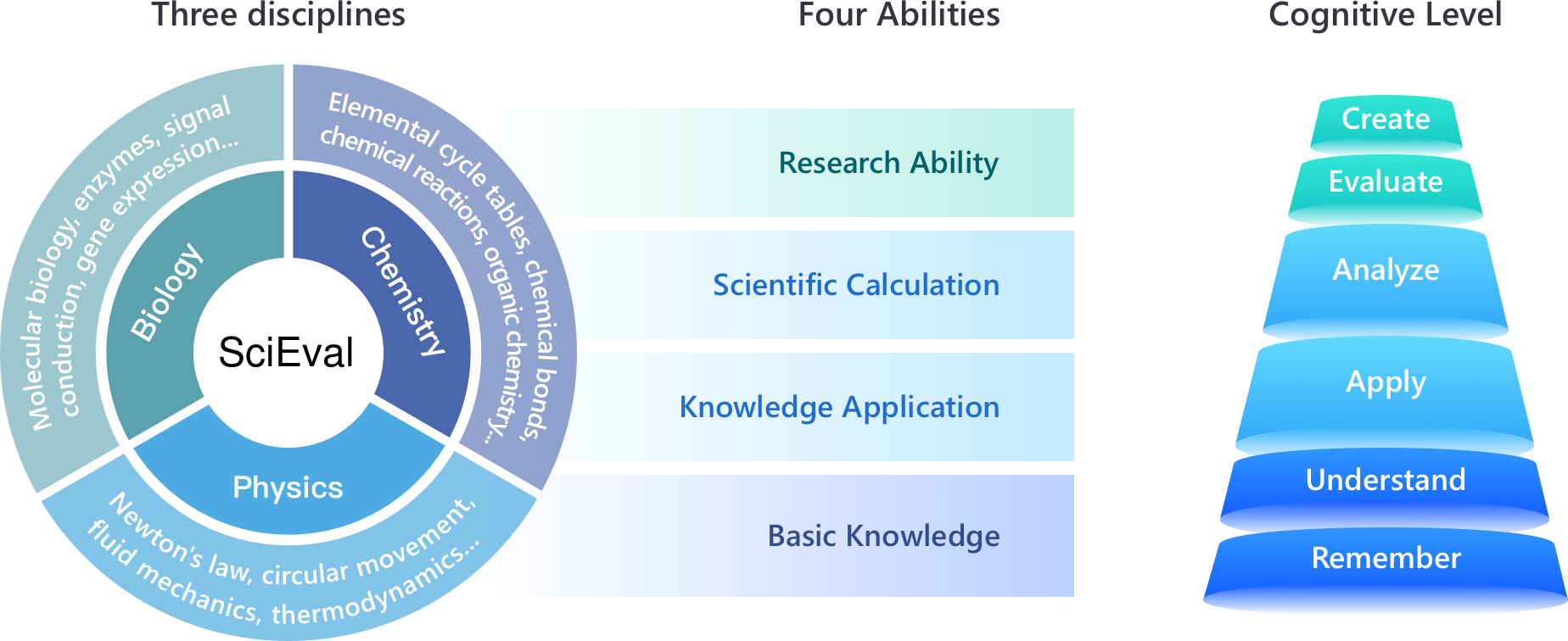
Figure 1: The illustration of the evaluation system. SciEval covers three disciplines with amounts of sub-topics, and investigates four abilities, corresponding to six cognitive levels.
Data Collection Process
Data for SciEval is categorized into three types: Static Data, Dynamic Data, and Experimental Data. The Static Data is curated from existing datasets such as Socratic Q&A, MedQA, and PubMedQA to ensure a diverse range of questions. Dynamic Data is generated to mitigate data leakage risks, allowing for periodic updates. Experimental Data provides subjective questions that evaluate experimental design and analysis capabilities, further testing the nuanced research abilities of LLMs.

Figure 2: Data Collection steps of Static Data.
Evaluation Methodology
SciEval evaluates models across various settings, namely Answer-Only (AO), Chain-of-Thought (CoT), and 3-Shot settings. These setups are critical in assessing the models' reasoning and application capabilities beyond basic accuracy metrics.

Figure 3: An example of the prompt we used for AO setting. The red text is the response from the model, while the black text is the inputted prompt.

Figure 4: An example of the prompt we used for CoT setting. The red text is the response from the model, while the blue text and black text are the inputted prompt.
Experimental Results and Analysis
Static and Dynamic Data Results
The results on Static Data indicate that GPT-4 achieves the highest average accuracy, although gaps remain in Knowledge Application and Scientific Calculation. In Dynamic Data, while a few models achieve notable performance in counting and calculation problems, most LLMs struggle with chemistry and physics questions, indicating significant knowledge gaps.
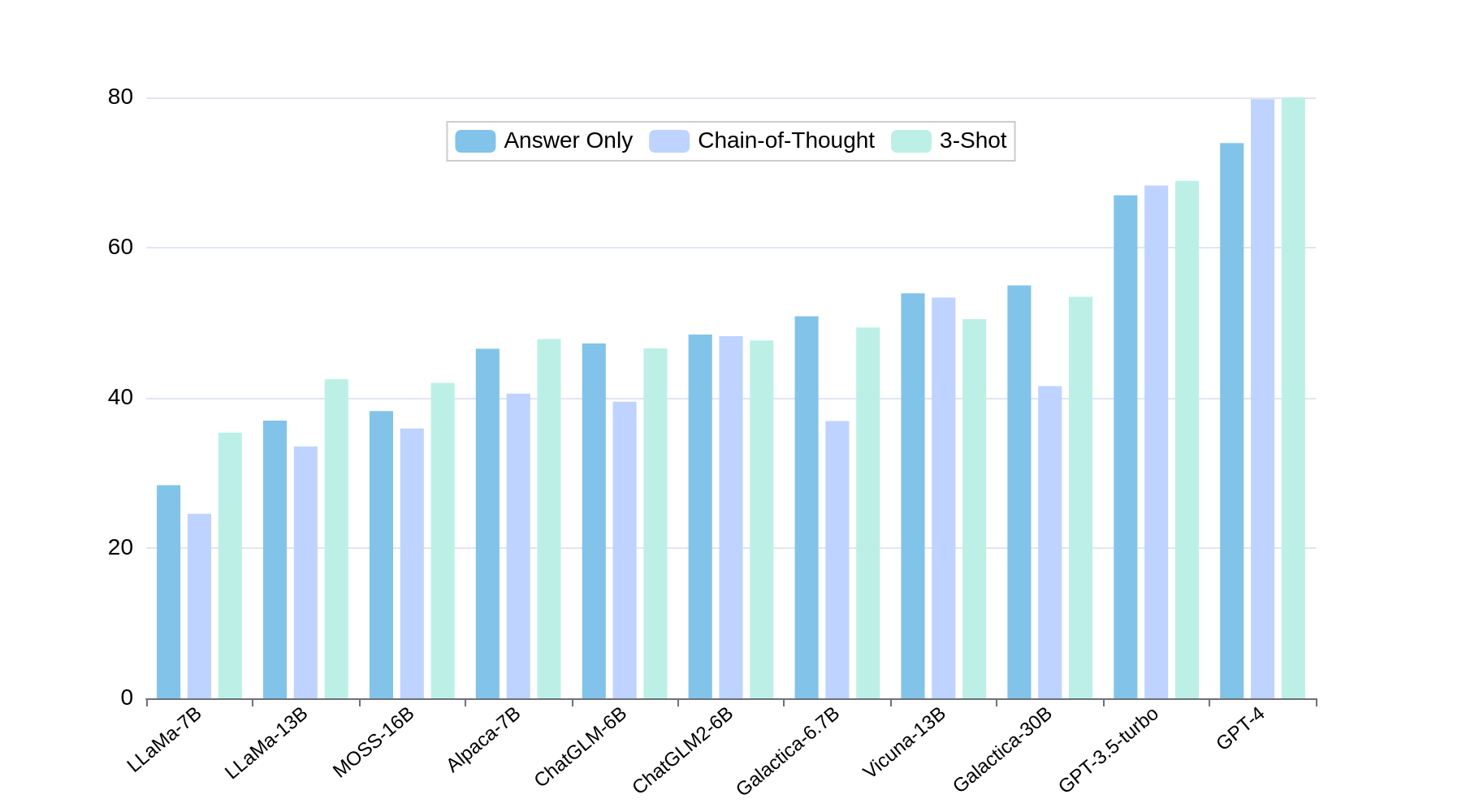
Figure 5: Accuracy on Answer Only, Chain-of-Thought and 3-Shot settings of each LLMs for Static Data.
Experimental Data
On Experimental Data, GPT-4 and Claude models proved proficient in experimental principle and design but consistently underperformed in analyzing experimental results, revealing a prevalent weakness in higher-order cognitive tasks.
Conclusion and Implications
SciEval presents a robust, multi-faceted benchmark pertinent to assessing LLMs in scientific contexts, addressing crucial gaps in existing evaluation paradigms. Future work may focus on refining dynamic data generation methods, enhancing subjective question evaluations, and expanding the benchmark to encompass a broader range of scientific fields. By furnishing a comprehensive evaluation toolkit for scientific research capabilities of LLMs, SciEval promotes ongoing advancements and application of AI in scientific inquiry.