- The paper introduces a recursive summarization method that improves dialogue memory in LLMs by synthesizing past interactions.
- It recursively aggregates summaries from previous conversations to maintain context and coherence in extended dialogues.
- Experiments show enhanced response consistency and engagement, outperforming traditional memory-based methods.
Recursively Summarizing Enables Long-Term Dialogue Memory in LLMs
Introduction
The paper "Recursively Summarizing Enables Long-Term Dialogue Memory in LLMs" (2308.15022) addresses a critical limitation in current LLMs like GPT-4—the inability to effectively recall and incorporate past interactions in long-term conversations. Despite the impressive conversational abilities afforded by large context windows, these models fall short in maintaining consistency across extended dialogues. The authors propose a method to enhance dialog generation by recursively summarizing past dialogue sessions, using these summaries as memory aids to improve coherence in long-term interactions.
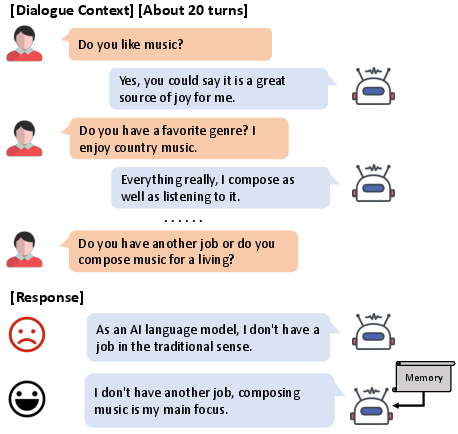
Figure 1: A long-term conversation example from the Multi-Session Chat Dataset, highlighting challenges in maintaining coherence over extended dialogue turns.
Proposed Method: Recursive Summarization
The novel approach outlined involves a recursive summary generation process to address memory constraints. Initially, the model generates a summary from small dialogue contexts, storing key information about speaker interactions. As subsequent dialogs occur, new memories are generated by integrating prior summaries with fresh dialog contexts. This iterative mechanism ensures that the LLM has access to an up-to-date, concise summary of past interactions, which serves as a robust memory aid during response generation.
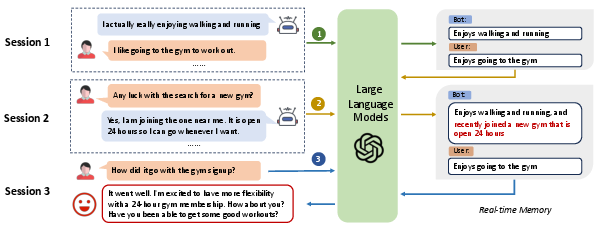
Figure 2: The schematic overview of our method, illustrating the recursive generation and updating of memory over multiple sessions.
Experiments and Results
The method was tested on datasets like Multi-Session Chat (MSC) and CareCall, using prominent LLMs such as Llama, ChatGLM, and GPT-3.5-Turbo. Quantitative results showed consistent improvements in response coherence and consistency across sessions, outperforming traditional retrieval-based and memory-based methods without recursive summarization.
In terms of human evaluations, the method demonstrated better engagement and coherence, with scores indicating improvements in conversational flow and context-sensitive interactions. Furthermore, employing the GPT-4 as an evaluator confirmed the superiority of this recursive summarization approach.
Implications and Future Work
The implications of this research are profound, particularly for applications requiring sustained interaction and memory retention, such as personal AI companions or health assistants. The recursive summarization technique provides a simple yet effective mechanism for enhancing dialogue coherence across extended interactions, a crucial element for user-facing AI systems.
Future developments could explore finer-tuned summarization strategies to mitigate minor factual inconsistencies, with potential applications extending to narrative generation and long-form content synthesis. Additionally, incorporating retrieval-enhanced methods could further bolster the memory handling capabilities of LLMs, establishing them as powerful tools for complex conversational tasks.
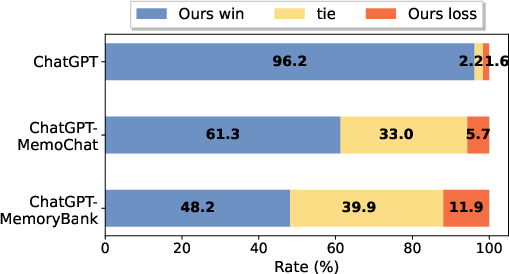
Figure 3: Comparative win rate of our method against competitive baselines, demonstrating the advantages of recursive summarization.
Conclusion
Overall, the recursive summarization method proposed affirms a significant step forward in the quest to improve long-term dialogue coherence in LLMs. It highlights a promising direction for research in natural language processing, where memory mechanisms are crucial for the development of truly intelligent and context-aware conversational agents.
The simplicity and universality of this method make it a valuable addition to existing frameworks, enhancing the consistency and coherence of LLMs in a wide range of applications. This work lays the groundwork for future explorations into efficient memory handling techniques in large-scale LLMs.