- The paper introduces TOMATO, a task that leverages LLMs to autonomously generate innovative and valid scientific hypotheses from raw web data.
- The MOOSE framework integrates multi-module feedback—past, present, and future—to iteratively refine the hypothesis generation process.
- Evaluations by GPT-4 and social science experts show that the approach significantly enhances hypothesis novelty and creativity compared to traditional methods.
LLMs for Automated Open-domain Scientific Hypotheses Discovery (2309.02726)
Introduction
The paper presents a novel approach to developing an NLP system for automated generation of scientific hypotheses using LLMs. The central task, named TOMATO, involves creating systems that autonomously propose innovative and useful hypotheses in the social science domain by leveraging a raw web corpus as the sole data input. This methodology signifies a departure from prior constrained settings that relied on carefully curated datasets, which limited the scope of generated hypotheses to largely commonsensical concepts already familiar to scientific discourse.
New Task Definition: TOMATO
The authors introduce "auTOmated open-doMAin hypoThetical inductiOn" (TOMATO), an entirely automated task designed to generate hypotheses that are both novel and valid without human intervention. The dataset comprises 50 recent social science publications, with accompanying raw web corpus resources necessary for hypothesis development extracted from platforms like news sites and Wikipedia. Crucially, proposed hypotheses should not merely reiterate existing knowledge but instead offer new insights or explanations not previously documented—a quality the paper refers to as being "novel to humanity."
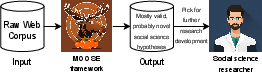
Figure 1: Overview of the new task setting of hypothetical induction and the role of the MOOSE framework.
MOOSE Framework
To tackle this task, the authors developed MOOSE (Multi-mOdule framewOrk with paSt, present, future feEdback), a multi-module architecture utilizing LLM prompting to facilitate the induction process. MOOSE comprises several interconnected modules executing in sequence: Background Finder, Inspiration Title Finder, Inspiration Finder, Hypothesis Suggestor, and Hypothesis Proposer. Each module processes raw web data to iteratively refine and propose hypotheses.
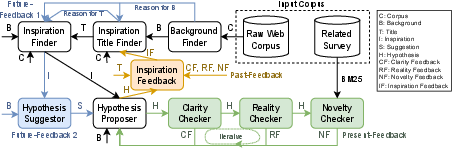
Figure 2: MOOSE: Our multi-module framework for TOMATO task. The black part is the base framework; \textcolor{ORANGE}{orange part} represents past-feedback; \textcolor{GREEN}{green part} represents present-feedback; \textcolor{BLUE}{blue part} represents future-feedback
.
MOOSE incorporates multiple feedback mechanisms:
- Present-feedback: Real-time feedback is provided by LLMs to enable immediate refinement of newly generated hypotheses.
- Past-feedback: Evaluates earlier module outputs based on the current state of hypothesis development, allowing backward correction of potential flaws.
- Future-feedback: Proposes implications and guiding frameworks that assist subsequent module outputs, enhancing hypothesis generation fidelity.
Evaluation
The authors evaluated MOOSE using a dual approach—GPT-4 evaluation and assessments conducted by social science experts. The results indicate a marked improvement in generating hypotheses with increased novelty and helpfulness in comparison to baseline LLM configurations. Notably, the proposed framework was able to yield hypotheses deemed valid yet previously unasserted within scientific literature.
Analysis
A detailed analysis revealed intriguing capabilities of the MOOSE framework. For instance, introducing heuristic-based past-feedback substantially heightened the novelty of the developed hypotheses. Intriguingly, even hypotheses generated from randomized inspirations demonstrated a baseline level of creativity, suggesting inherent novelty in the data-to-hypothesis mapping recognized by the framework.
Conclusion
The research unearths the potential of LLMs not only to serve as computational aides in hypothesis generation but to autonomously contribute novel scientific propositions. This indicates a significant step towards AI systems capable of bolstering human researchers in the ideation and verification phases of the scientific method, particularly within the expansive context of social sciences. Nevertheless, enhancing cross-domain applications remains a compelling direction for future exploration.