- The paper proposes a self-refinement mechanism where a large language model iteratively improves reward functions for robotic DRL tasks.
- It employs a three-phase methodology: initial design using natural language prompts, automated evaluation via PPO, and iterative refinement based on performance feedback.
- Experimental results on diverse robotic systems show that refined reward functions can achieve over 95% success rates, matching or outperforming manual designs.
Self-Refined LLM for Automated Reward Function Design in Robotics
The paper "Self-Refined LLM as Automated Reward Function Designer for Deep Reinforcement Learning in Robotics" (2309.06687) introduces a novel framework leveraging LLMs with a self-refinement mechanism to automate reward function design for DRL in robotics. The core idea revolves around using LLMs to generate initial reward functions from natural language instructions and iteratively refining these functions based on performance feedback from the trained agents. This approach aims to address the challenge of manually designing effective reward functions, which often requires significant domain expertise and manual tuning.
Methodology
The proposed framework consists of three key steps, as illustrated in (Figure 1): initial design, evaluation, and a self-refinement loop.
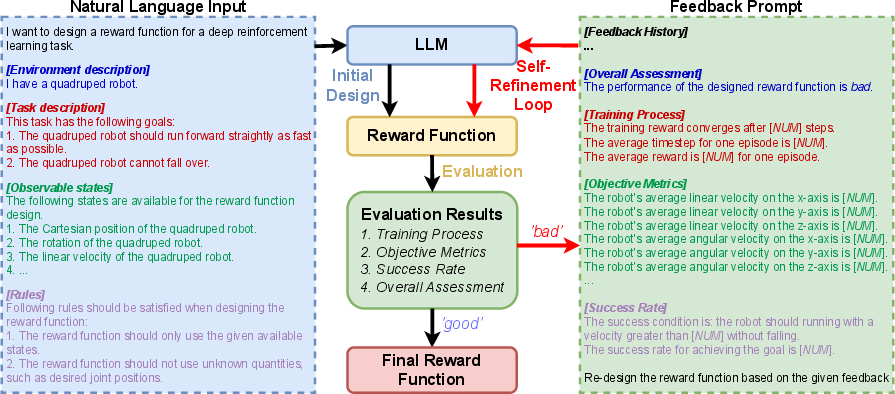
Figure 1: The self-refine LLM framework for reward function design, encompassing initial design, evaluation, and a self-refinement loop, demonstrated using a quadruped robot forward running task.
In the initial design phase, the LLM formulates a reward function based on a natural language prompt, which is segmented into environment description, task description, observable states, and rules. This structured prompt aims to provide the LLM with sufficient context to understand the robotic control task and generate a suitable initial reward function. The authors employ the LLM as a zero-shot reward function designer, excluding examples in the prompts, because finding universally applicable examples for a diverse array of robotic control tasks proves challenging. The initial reward function is typically a weighted combination of multiple individual reward components, expressed as R=∑i=0nwiri. The weights wi are then adjusted through the self-refinement process.
The evaluation phase assesses the efficacy of the designed reward function through an automated procedure. This involves training a DRL policy using the designed reward function and then sampling trajectories from this policy. The performance of the reward function is evaluated based on the training process, objective metrics, and success rate in task accomplishments. The success rate is determined using STL to define the core objective of the task. The overall performance of the designed reward function is categorized as either 'good' or 'bad' based on whether the success rate exceeds a predefined threshold.
The self-refinement loop enhances the designed reward function by iteratively refining it based on feedback from the evaluation process. A feedback prompt is constructed for the LLM, summarizing the evaluation results, including the overall assessment, training process, objective metrics, and success rate. Guided by this feedback, the LLM attempts to develop an updated reward function. The evaluation and self-refinement processes are repeated until a predefined maximum number of iterations is reached, or the evaluation suggests 'good' performance.
Experimental Results
The authors evaluated the performance of the proposed framework through nine distinct continuous robotic control tasks across three diverse robotic systems, including a robotic manipulator, a quadruped robot, and a quadcopter. The tasks included ball catching, ball balancing, ball pushing, velocity tracking, running, walking to target, hovering, flying through a wind field, and velocity tracking. (Figure 2) shows the robotic systems used in the experiments.





Figure 2: Continuous robotic control tasks with three diverse robotic systems: robotic manipulator, quadruped robot, and quadcopter.
The reward functions obtained by using three different methods were compared: the LLM's initial design (RInitial), the final reward function formulated by the proposed self-refined LLM framework (RRefined), and a manually designed reward function (RManual). Proximal Policy Optimization (PPO) was used as the DRL algorithm to find the optimal policy for each reward function. The success rate threshold for the overall assessment was set at 95\%, and the maximum number of self-refinement iterations was set to 5.
(Figure 3) and (Figure 4) illustrates the reward function design process and the corresponding system behaviors for the quadruped robot forward running task.
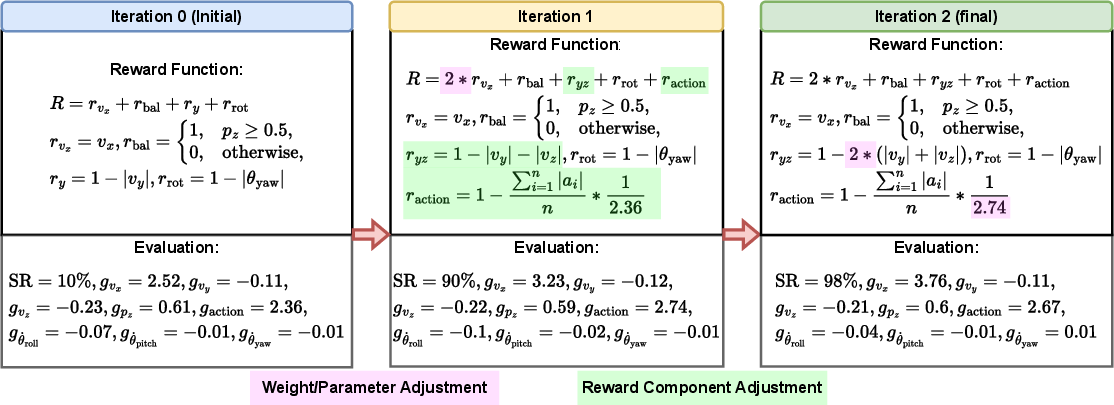
Figure 3: Reward functions in different self-refinement iterations for the quadruped robot forward running task.

Figure 4: System behaviors corresponding to reward functions in different self-refinement iterations, alongside the manually designed reward function.
The results indicated that the initial reward function demonstrated a binary level of performance. For tasks with straightforward objectives, the LLM could devise a high-performing reward function on its first attempt. However, for more complex tasks, the initial reward function often registered a success rate of 0\%. By leveraging the evaluation results, the LLM was capable of effectively revising its reward function design, achieving success rates that matched or even surpassed those of manually designed reward functions for all examined tasks.
Discussion and Future Work
The paper discusses potential improvements to the proposed framework, including integrating the LLM with AutoRL techniques to optimize the parameters of the reward function and fine-tuning the LLM specifically for reward function design. The limitations of the approach are also acknowledged, such as its inability to address nuanced aspects of desired system behaviors that are difficult to quantify through the automated evaluation process and the reliance of the LLM on its pre-trained common-sense knowledge.
Conclusion
The paper presents a novel self-refined LLM framework as an automated reward function designer for DRL in continuous robotic control tasks. The experimental results demonstrate that the proposed approach can generate reward functions that are on par with, or even superior to, those manually designed ones. The authors propose integrating the LLM with AutoRL techniques in future work, enabling not only the reward function but also all learning parameters to be designed autonomously.