- The paper introduces a dual-process memory mechanism that coordinates short- and long-term memory to enhance personalized responses without retraining the entire model.
- It leverages parameter-efficient fine-tuning with LoRA to update only a subset of parameters, ensuring efficient adaptation to individual medical dialogue contexts.
- Empirical results show significant improvements in response win rate, preference classification, and ROUGE scores, emphasizing the approach's scalability and precision.
Parameter-Efficient Personalization of LLM-based Medical Assistants via Short- and Long-Term Memory Coordination
Motivation and Problem Statement
The paper "LLM-based Medical Assistant Personalization with Short- and Long-Term Memory Coordination" (2309.11696) identifies a critical gap in medical assistant systems built upon LLMs: the inability to deliver personalized, user-specific responses without retraining or excessive computational resources. Existing memory-augmented approaches rely predominantly on rigid, dictionary-style memory structures or prompt engineering. These fail to account for patient preferences and nuanced histories, which are essential for medical advice. The work proposes a dual-process memory mechanism (DPeM) and a unified framework (MaLP) integrating parameter-efficient fine-tuning (PEFT), specifically LoRA, to achieve effective personalization while retaining efficiency.
Dual-Process Enhanced Memory (DPeM): Mechanism and Architecture
Drawing inspiration from cognitive neuroscience, the authors introduce a memory model coordinated by dual processes—rehearsal (learning and summarizing) and executive (memorizing)—to mimic working, short-term, and long-term memory. The DPeM mechanism filters, buffers, and registers information at different stages of dialog, thereby distinguishing between common-sense and user-specific knowledge.
The user’s historical dialogues are processed via a coordinator equipped with advanced NLU capabilities, such as ChatGPT, which extracts salient notes. Working memory serves as a buffer, STM accumulates relevant, recent knowledge, and LTM archives frequently accessed information. Memory retrieval operates differently for STM (Levenshtein distance search) and LTM (semantic vector search).
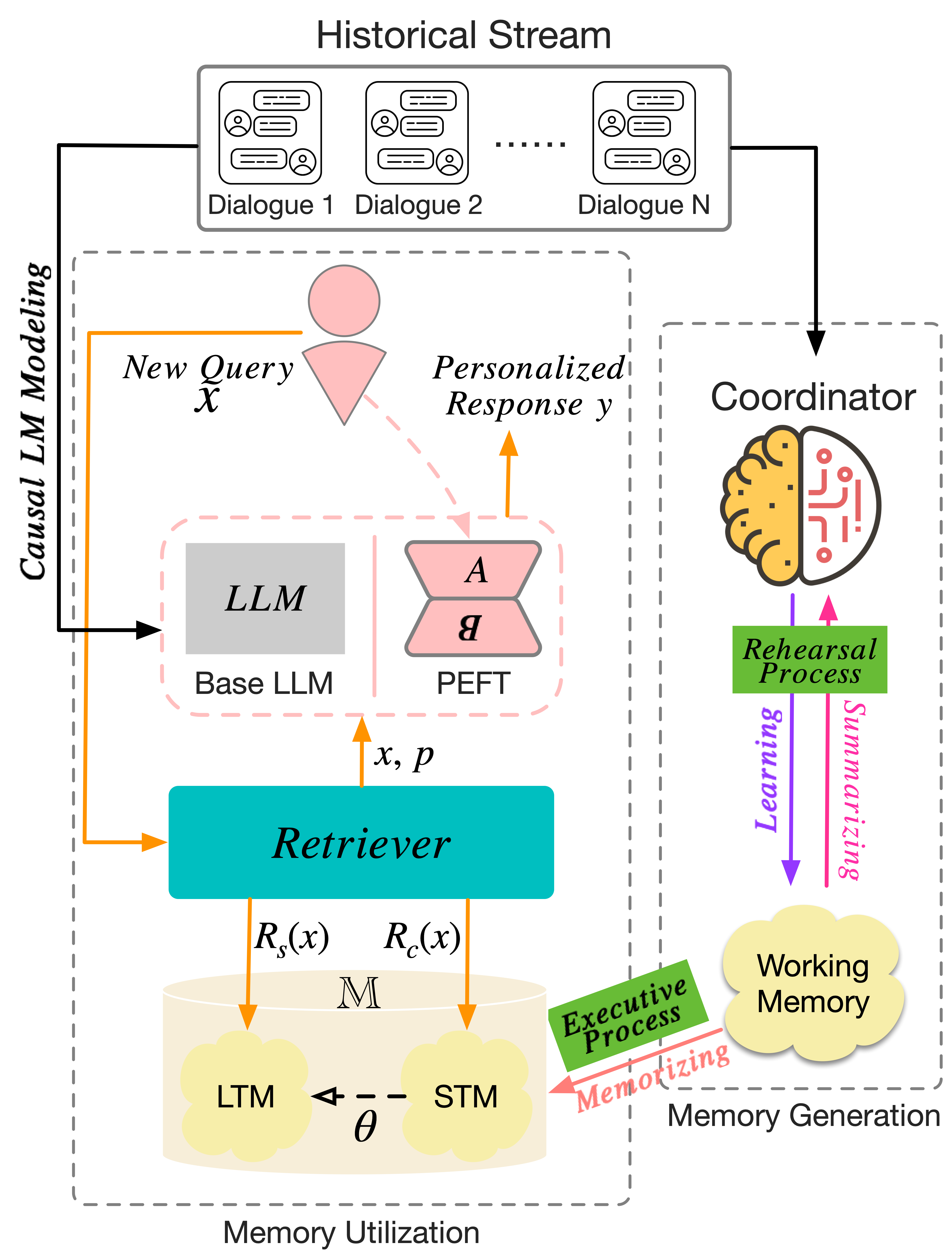
Figure 1: Overview of MaLP: depicting the coordination of historical dialogs, dual-process memory generation, and causal language modeling for personalized response generation.
Parameter-Efficient Fine-Tuning (PEFT) via LoRA
Traditional fine-tuning is prohibitive in computational and data requirements. The MaLP framework leverages LoRA, updating only a low-rank subset of the base LLM’s parameters. This allows efficient adaptation to user preferences without retraining the full model. The integration of DPeM-generated memory prompts with LoRA-adapted LLMs ensures responses are not only factually accurate but also tailored to the user's dialog style and medical background.
Dataset Construction and Evaluation Practices
The authors construct a novel medical dialog dataset through self-chat simulations between synthetic doctor and patient personas. Patient profiles are derived from a medical corpus, imbuing the chat simulations with both medical domain expertise and individualized dialogue preferences.
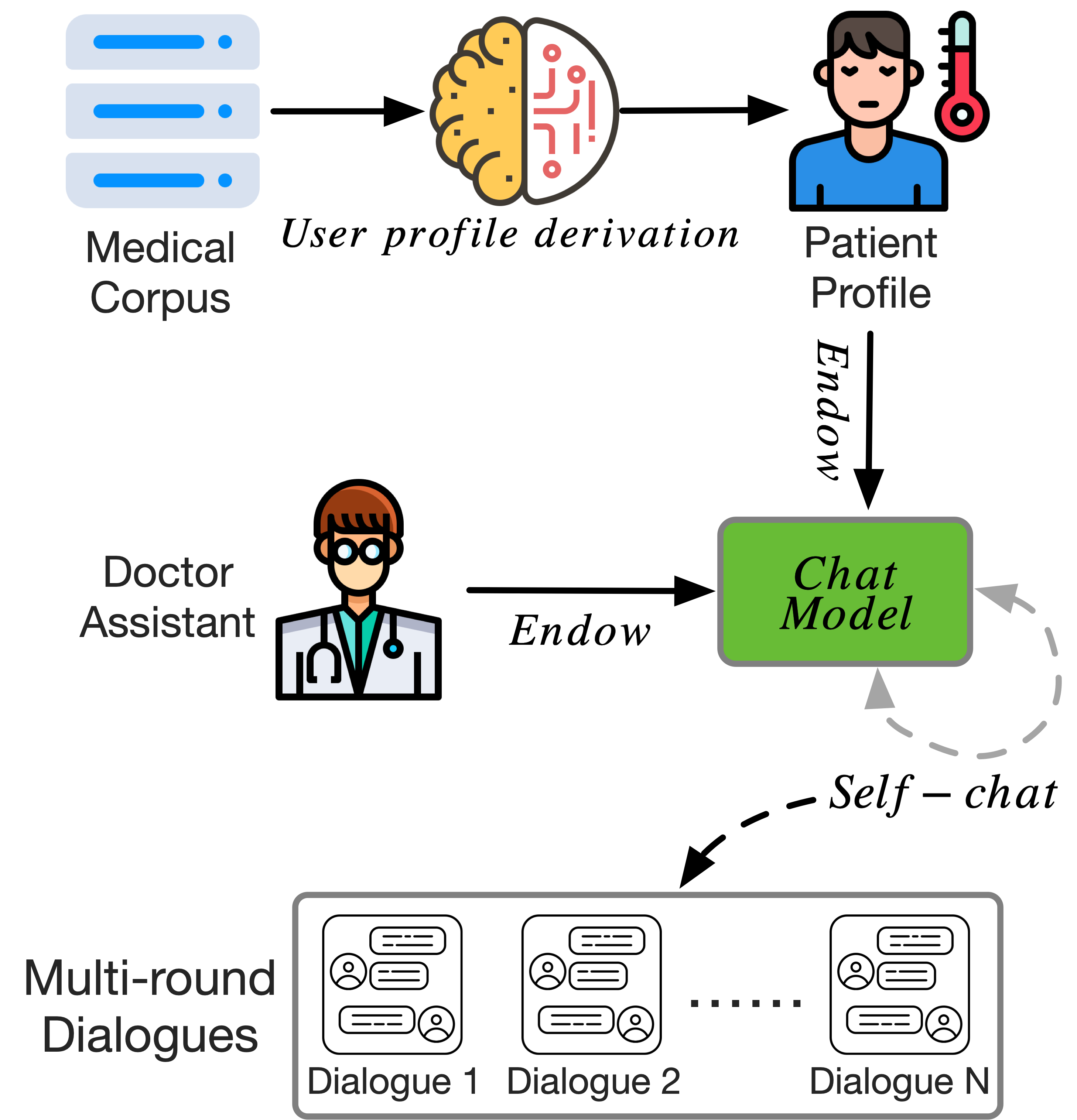
Figure 2: Data collection pipeline, showing profile derivation, dialogue simulation, and historical conversation accumulation.
Safety checks and human evaluation protocols are detailed, with the dataset achieving high quality (score 5.27/6) and safety (94%) metrics. The evaluation is further validated by human annotators, correlating highly (P.C = 0.72) with automatic scoring.
Empirical Results and Analysis
Results demonstrate the superiority of DPeM and MaLP across three tasks: QA, preference classification, and response generation. Notably, MaLP achieves significant improvements in response win rate (91.53% for LLaMA-7B, 91.27% for LLaMA-13B), preference classification accuracy, and ROUGE scores over baseline and prior memory-augmented approaches. The dual-process schema contributes to robust memory management, reducing erroneous or irrelevant retrieval.
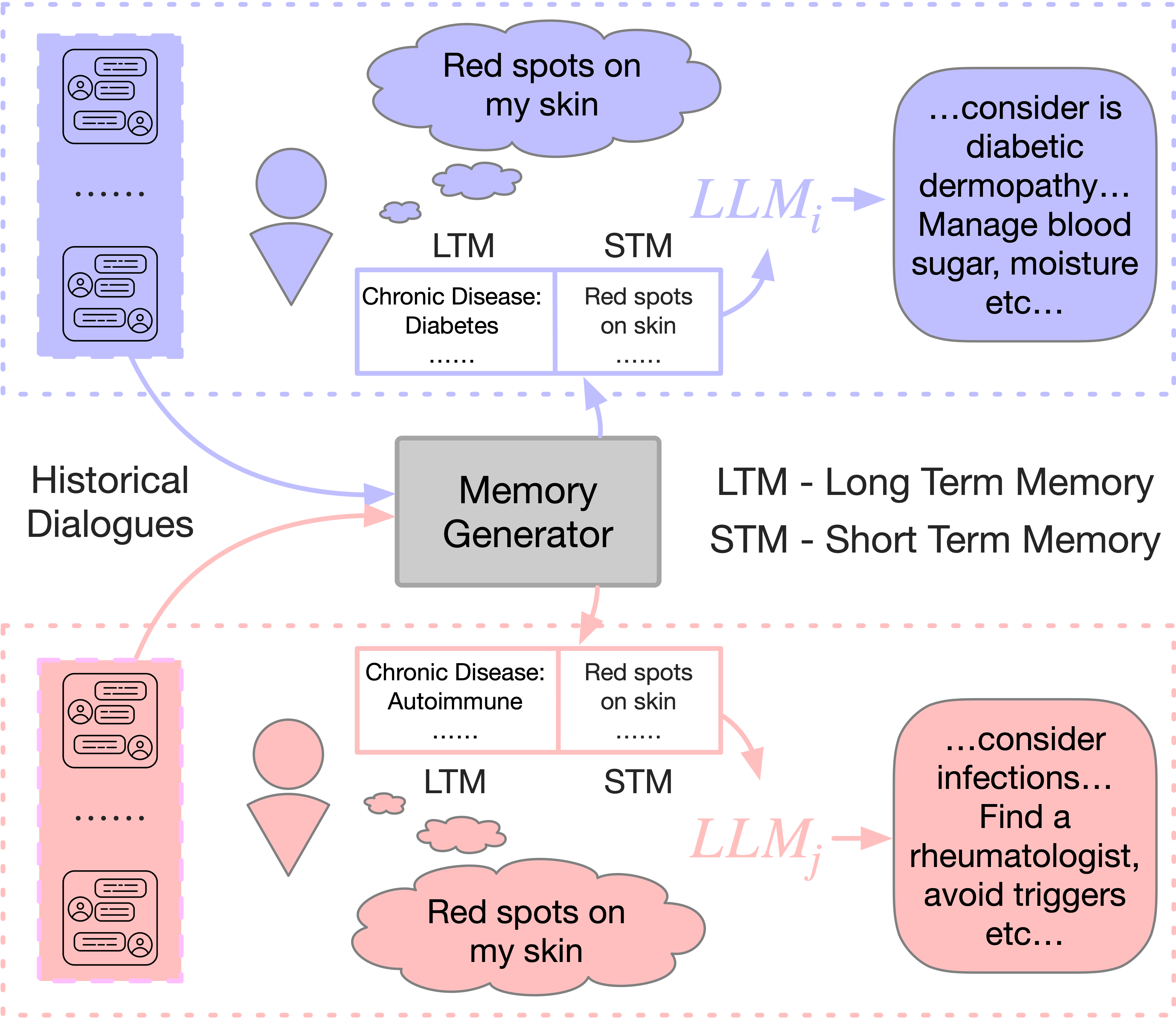
Figure 3: Example of personalized responses to equivalent queries for users with different histories and preferences.
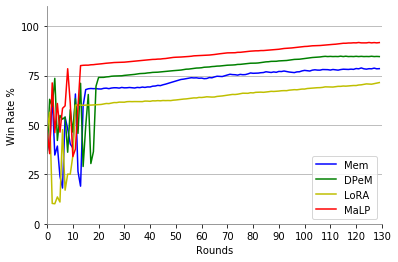
Figure 4: Response quality (win rate) increases steadily with accumulating historical dialogues, highlighting improved personalization over time.
Case studies illustrate response generation: MaLP consistently synthesizes both user-specific and common-sense knowledge, outperforming rigid memory or prompt-alone baselines.
Theoretical and Practical Implications
The DPeM framework advances memory-augmented LLM personalization by introducing a cognitively inspired, dynamically coordinated memory structure. When paired with PEFT, it balances response specificity, factual accuracy, and computational efficiency. Practically, this enables scalable deployment of LLM medical assistants capable of context-sensitive, preference-aware dialog. Theoretical progress includes the fusion of dual-process memory modeling with LLM parameter adaptation.
Challenges remain for real-world deployment, notably online learning from new queries, privacy in federated settings, and optimizing memory-forgetting mechanisms beyond simple frequency-based thresholds.
Future Directions
The authors propose augmenting the memory module for online, integrative learning, developing advanced loss functions to support avoidance learning, and exploring federated learning architectures for privacy-preserving personalization at scale. There is also interest in sharing LLM layers for multi-user support in large models, with privacy safeguards.
Conclusion
This work establishes a novel, resource-efficient paradigm for personalized LLM-based medical assistants by integrating nuanced memory modeling with parameter-efficient fine-tuning. The MaLP framework, empirically validated with strong numerical performance and human-aligned metrics, sets a strong foundation for scalable, context-aware personalization in AI health applications. The approach invites further exploration of adaptive memory integration and privacy-preserving multi-user personalization in complex, real-world environments.