- The paper introduces a novel SFI convolutional layer that adapts to various sampling frequencies without requiring resampling.
- It integrates these layers into the SuDoRM-RF network, enabling effective separation of diverse sound sources under different recording conditions.
- Experimental results on the FUSS48k dataset demonstrate significant improvements in SI-SDR metrics compared to traditional resampling-based methods.
Sampling-Frequency-Independent Universal Sound Separation
Introduction
The paper "Sampling-Frequency-Independent Universal Sound Separation" introduces a universal sound separation (USS) method that is capable of handling untrained sampling frequencies (SFs) through the incorporation of sampling-frequency-independent (SFI) convolutional layers. The primary motivation is to develop a sound separator that universally applies to diverse source types and recording conditions. While previous efforts have emphasized the need for handling various source types, executing separation across different SFs has remained underexplored. Recognizing the SF's variable nature across tasks, the proposed work integrates SFI convolutional layers within the SuDoRM-RF network, demonstrating notable improvements over traditional signal-resampling techniques.


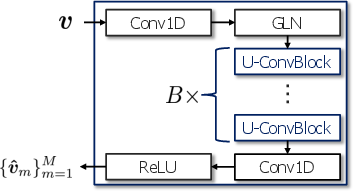
Figure 1: Network architectures of the proposed SFI version of SuDoRM-RF, original SuDoRM-RF, and mask predictor.
SuDoRM-RF Network Overview
SuDoRM-RF is a state-of-the-art USS network characterized by its computational efficiency and superior performance in handling a diverse range of source types. It employs a one-dimensional convolutional layer architecture with trainable analysis and synthesis filterbanks, often referred to as the encoder and decoder. The encoder transfigures input signals into a pseudo time-frequency domain, which the mask predictor uses to derive separation masks for each source. The network innovatively addresses scenarios with variable numbers of sources, allowing for robust assignment and permutation invariant training through a negative average SNR-based loss function.
SFI Convolutional Layer
The paper introduces a novel extension, the SFI convolutional layer, which generates convolutional kernels compatible with the SF of the input. By employing analog filters as archtypes, the digital filter analogously adapts through a frequency-domain filter design method, making it invariant to the input SF. This adaptability is pivotal in environments with a wide distribution of SFs, enabling the network to maintain consistent performance without the inefficiencies introduced by signal resampling.
The SFI convolutional layer replaces traditional convolution layers within SuDoRM-RF, ensuring the network's seamless transition between different SF environments with negligible computational overhead, beyond the initial generation of weights per unique SF.
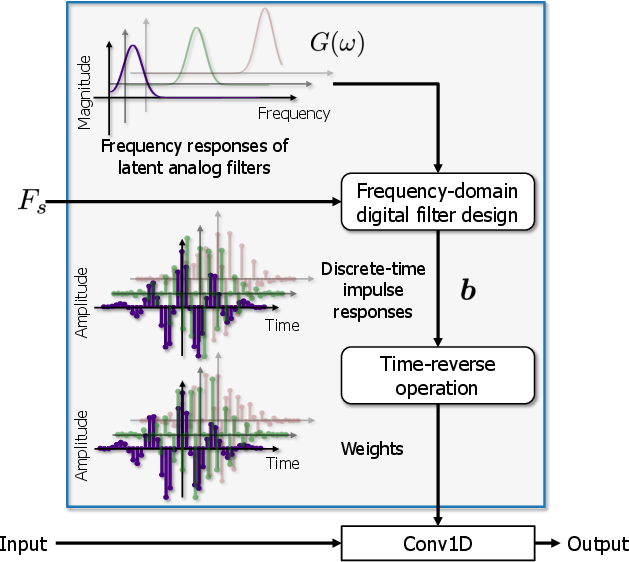
Figure 2: Architecture of SFI convolutional layer using frequency-domain digital filter design.
Experimental Evaluation
Experiments conducted using the FUSS48k dataset affirm the effectiveness of the SFI approach. By resampling the dataset at various SFs, the proposed method significantly outperforms traditional methods which rely on signal resampling. This performance superiority is evident in both SI-SDR and SI-SDR improvement metrics across all evaluated N sources.
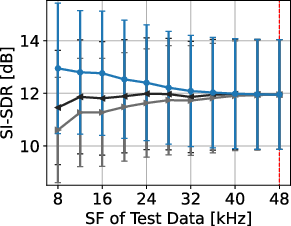
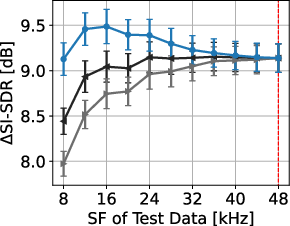
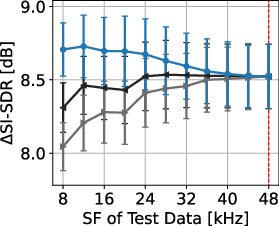
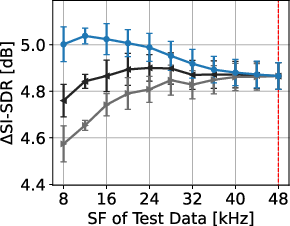
Figure 3: Separation performances of proposed and signal-resampling-based methods for each N. Red dotted lines denote trained SF. Error bars show standard errors.
The results underscore the degradation introduced by resampling-based methods, particularly at lower SFs, which contrasts sharply with the consistent results obtained using the proposed SFI layers. The SFI extension of SuDoRM-RF demonstrates maintained efficacy across a diverse SF spectrum, validating the utility of the proposed framework for universal separation tasks.
Conclusion
This research delivers a practical and efficient solution for universal sound separation in environments with variable SFs. By innovatively integrating SFI convolutional layers within the SuDoRM-RF structure, the approach elegantly circumvents challenges posed by SF inconsistencies, ensuring high performance across various recording contexts. The paper paves the way for universally applicable sound separation models, providing a crucial step toward seamless preprocessing capabilities across myriad audio signal processing applications. Future research may explore further optimizations for real-time applications and broader testing across additional datasets.