- The paper presents a quantization-aware low-rank adaptation method that combines parameter-efficient fine-tuning with INT4 quantization for resource-constrained environments.
- The paper introduces group-wise quantization to optimize memory and computational requirements while preserving model accuracy.
- Empirical results on LLaMA and LLaMA2 models demonstrate that QA-LoRA maintains accuracy and delivers significant efficiency gains compared to mixed-precision methods.
Overview of QA-LoRA
The paper "QA-LoRA: Quantization-Aware Low-Rank Adaptation of LLMs" addresses the challenges posed by the computational demands of LLMs. The proposed approach, QA-LoRA, introduces a quantization-aware algorithm enabling both efficient fine-tuning and deployment on resource-limited devices without sacrificing accuracy.
Introduction and Motivation
The rapid growth of LLMs, such as those in the LLaMA model family, has driven the need for methods that reduce computational and memory requirements, particularly for deployment on edge devices. Traditionally, two separate lines of research aim to address this: parameter-efficient fine-tuning (PEFT) and parameter quantization. However, integrating these two methods has proven challenging due to accuracy trade-offs and computational inefficiencies.
Existing solutions like QLoRA attempt to reduce memory usage by quantizing weights during fine-tuning but often revert to high precision for inference. QA-LoRA overcomes this limitation by allowing both fine-tuning and inference to be conducted with quantized weights, thus maintaining efficiency throughout the entire lifecycle of the model.
Methodology
QA-LoRA introduces group-wise quantization and adaptation as its key technical innovation. This approach increases the freedom for quantization while decreasing adaptation complexity. During fine-tuning, LLM weights are quantized (e.g., to INT4), ensuring reduced time and memory usage. After fine-tuning, the pre-trained weights and auxiliary weights are merged into a quantized representation, circumventing the need for post-training quantization and avoiding accuracy loss.
The technique involves applying group-wise operations which segment columns of weights into groups for individual quantization, with each group sharing adaptation parameters. This not only optimizes memory and computational requirements but also enables the model to retain accuracy post-adaptation.
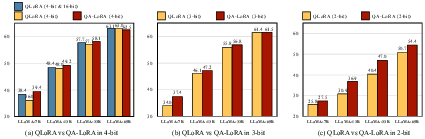
Figure 1: The comparison of 5-shot MMLU accuracy (%) with different quantization bit widths based on the LLaMA model family. QLoRA (\textsf{NF4}) models were compared to QA-LoRA.
The figure illustrates QA-LoRA's performance across multiple quantization bit widths compared against QLoRA, highlighting consistent accuracy without requiring post-training quantization.
Implementation
The implementation of QA-LoRA is straightforward, involving minor modifications to existing LoRA-based systems to incorporate quantization-aware strategies. The pseudocode provided demonstrates the ease of integrating QA-LoRA into existing LLM frameworks with minimal additional computational overhead.
Important to note is the efficient use of CUDA-optimized INT4 operations, which accelerates both the fine-tuning and inference stages relative to traditional float representations. This efficiency is particularly pronounced at lower quantization bit widths, making QA-LoRA suitable for environments with stringent computational constraints.
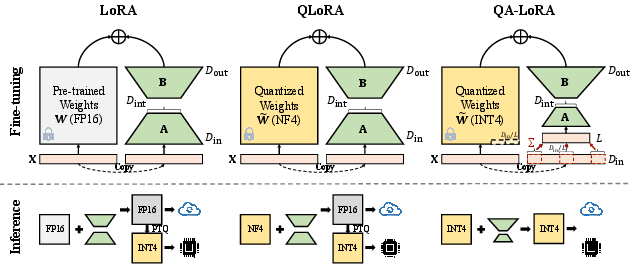
Figure 2: An illustration of the goal of QA-LoRA. Our approach is computationally efficient in both the fine-tuning and inference stages, outperforming previous methods.
Empirical Results
QA-LoRA's effectiveness is validated through its application on the LLaMA and LLaMA2 model families. Extensive benchmarks, including evaluations on the Massive Multitask Language Understanding (MMLU) dataset, demonstrate QA-LoRA's capability to maintain superior accuracy compared to both its LoRA and QLoRA counterparts, especially at lower bit-width quantizations.
The results indicate that the INT4 version of QA-LoRA can perform on par or even better than the mixed-precision QLoRA models, with significant computational savings during inference.
Conclusion
QA-LoRA fundamentally advances the adaptation and deployment of LLMs by introducing an efficient, easily implementable solution that combines low-rank adaptation with quantization awareness. Its ability to effectively marry memory efficiency with computational speed without compromising accuracy positions QA-LoRA as a robust solution for deploying LLMs in resource-constrained environments.
The broader implications of this research suggest potential for further refinements in both the quantization of neural networks and parameter-efficient fine-tuning frameworks, anticipating future developments that may extend these concepts to a wider array of models and deployment scenarios.