- The paper introduces SASANet, a novel method that integrates intrinsic self-attribution with Shapley value distillation for faithful neural network interpretation.
- It demonstrates efficient marginal contribution modeling by aligning intermediate outputs with permutation-invariant Shapley values.
- Empirical evaluations reveal that SASANet outperforms traditional interpretable models while matching the accuracy of popular black-box models.
Intrinsic Interpretation with Shapley Additive Self-Attribution
Introduction
The paper "Towards Faithful Neural Network Intrinsic Interpretation with Shapley Additive Self-Attribution" presents SASANet, an innovative method for intrinsic neural network interpretation. The proposed approach focuses on addressing the absence of the Shapley value in current self-attributing frameworks, providing self-attribution values that align with the output's Shapley values. This section examines the underlying principles and implementation strategies outlined in the paper.
Conceptual Framework: Additive Self-Attribution
Self-interpreting networks have consistently grappled with the trade-off between expressiveness and interpretability. The framework outlined in the paper highlights this dynamic and addresses it through Additive Self-Attribution (ASA). This framework is integral to the design and implementation of SASANet. By linearizing the feature attributions, the ASA framework aligns with Shapley values, which are widely recognized for their fairness in contribution allocation due to their adherence to coalition game theory axioms.
Below is a representation of SASANet's procedure, showcasing how the network models feature contributions (Figure 1).
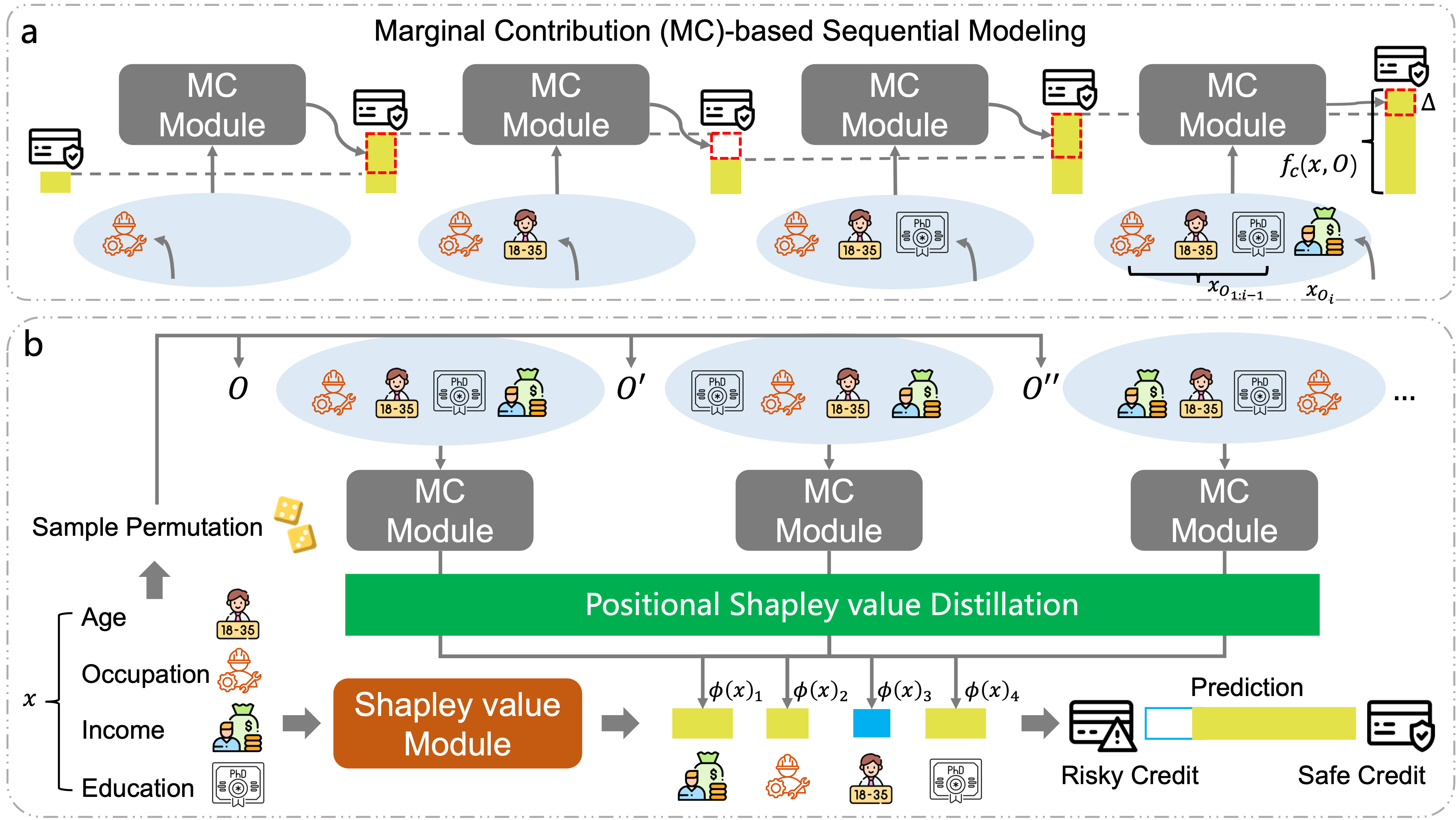
Figure 1: A schematic of the SASANet procedure. (a) Each sample is viewed as a set of features. The intermediate sequential module models a permutation-variant intermediate output as the cumulative contributions of these features. (b) The Shapley Value module trains a self-attributing network via internal Shapley value distillation, in which the attribution values proven to converge to the permutation-invariant final output's Shapley value.
Methodology: Shapley Additive Self-Attribution Network (SASANet)
Marginal Contribution Modeling
A unique aspect of SASANet is the marginal contribution-based sequential modeling, which enhances the network's ability to handle sets of features. This module generates permutation-variant outputs that reflect intermediate feature effects. As shown in Equation 5, this is achieved by explicitly modeling the marginal contribution of each feature individually:
Lm(x,y,O)=ylog(σ(fc(x,O;θ△)))+(1−y)log(1−σ(fc(x,O;θ△)))
Shapley Value Distillation
One of the pivotal improvements in SASANet is the use of Shapley value distillation, which ensures that the self-attribution values converge to the Shapley value. This is accomplished through an internal distillation strategy that optimizes the distillation loss for variable-size inputs:
$L^{(i)}_s(x_{\mathcal{S})=\frac{1}{|\mathcal{D}|}\sum_{O \in \mathcal{D} (\phi(x_\mathcal{S};\theta_{\phi})_i - \sum_{k \in \mathcal{S} \mathbb{I}\{O_k=i\} \triangle(x_i, x_{O_{1:k-1};\theta_{\triangle}))^2$
SASANet's performance was empirically evaluated across multiple datasets, and it demonstrates comparable or superior performance to traditional interpretable models such as Linear Regression (LR) and Neural Additive Model (NAM). It aligns closely with the performance of black-box models like LightGBM and MLPs, demonstrating its ability to balance interpretability and prediction accuracy.
Feature Attribution Evaluation
SASANet's ability to self-attribute was compared against KernelSHAP, revealing that SASANet provides more precise feature attribution due to its ability to model intrinsic relationships within data. Unlike post-hoc methods, SASANet offers a trustworthy representation of feature importance grounded in the model's actual behavior.
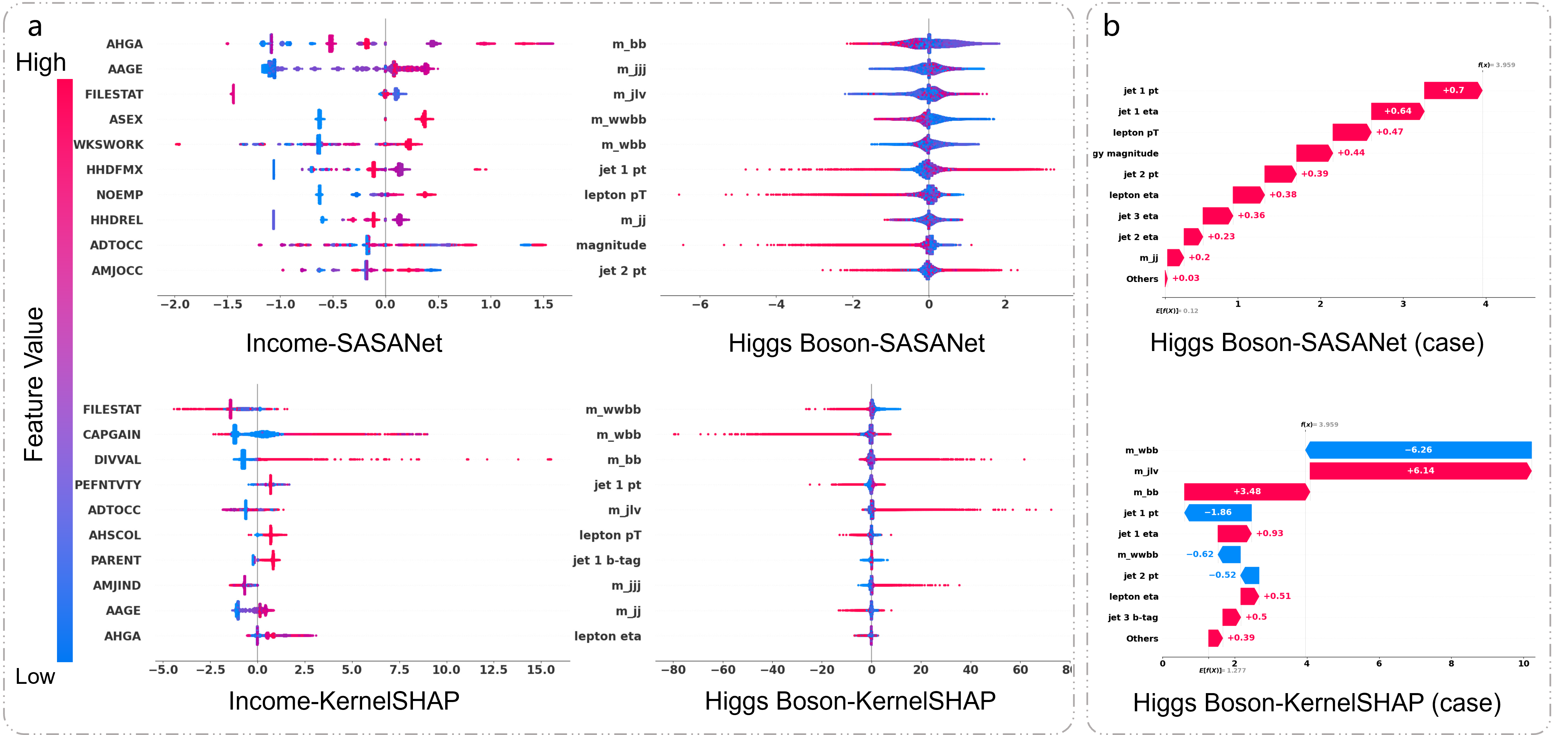
Figure 2: Feature attribution visualizations: x-axis shows attribution value; y-axis lists top features by decreasing average absolute attribution. (a) Overall attribution. (b) Single-instance attribution.
Efficiency and Scalability
SASANet's design facilitates rapid feature attribution without sacrificing accuracy or robustness. The model's execution time remains efficient, largely due to its intrinsic self-attribution process, eliminating the need for costly post-hoc computations typical in other methods such as KernelSHAP and LIME.
Conclusion
In conclusion, SASANet presents an innovative approach to neural network interpretation by bridging the gap between performance and interpretability. Its alignment with Shapley values ensures theoretically sound and faithful self-attribution, providing a robust framework for feature impact analysis. Future work could explore extending this framework to other domains, enabling broader adoption and application of trustworthy AI models in complex real-world scenarios.