How Much Training Data is Memorized in Overparameterized Autoencoders? An Inverse Problem Perspective on Memorization Evaluation
Abstract: Overparameterized autoencoder models often memorize their training data. For image data, memorization is often examined by using the trained autoencoder to recover missing regions in its training images (that were used only in their complete forms in the training). In this paper, we propose an inverse problem perspective for the study of memorization. Given a degraded training image, we define the recovery of the original training image as an inverse problem and formulate it as an optimization task. In our inverse problem, we use the trained autoencoder to implicitly define a regularizer for the particular training dataset that we aim to retrieve from. We develop the intricate optimization task into a practical method that iteratively applies the trained autoencoder and relatively simple computations that estimate and address the unknown degradation operator. We evaluate our method for blind inpainting where the goal is to recover training images from degradation of many missing pixels in an unknown pattern. We examine various deep autoencoder architectures, such as fully connected and U-Net (with various nonlinearities and at diverse train loss values), and show that our method significantly outperforms previous memorization-evaluation methods that recover training data from autoencoders. Importantly, our method greatly improves the recovery performance also in settings that were previously considered highly challenging, and even impractical, for such recovery and memorization evaluation.
- Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process., 19(9):2345–2356, 2010.
- Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3(1):1–122, 2011.
- Turning a denoiser into a super-resolver using plug and play priors. In 2016 IEEE International Conference on Image Processing (ICIP), 2016.
- Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pp. 2633–2650, 2021.
- Membership inference attacks from first principles. In 2022 IEEE Symposium on Security and Privacy (SP), pp. 1897–1914, 2022.
- Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pp. 5253–5270, 2023.
- Plug-and-play ADMM for image restoration: Fixed-point convergence and applications. IEEE Trans. Comput. Imag., 3(1):84–98, 2017.
- Postprocessing of compressed images via sequential denoising. IEEE Transactions on Image Processing, 25(7):3044–3058, 2016.
- Subspace fitting meets regression: The effects of supervision and orthonormality constraints on double descent of generalization errors. In International Conference on Machine Learning (ICML), pp. 2366–2375, 2020.
- Convolutional proximal neural networks and plug-and-play algorithms. Linear Algebra and its Applications, 631:203–234, 2021.
- Membership inference attacks on machine learning: A survey. ACM Comput. Surv., 54(11s), sep 2022.
- Y. Jiang and C. Pehlevan. Associative memory in iterated overparameterized sigmoid autoencoders. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 4828–4838. PMLR, 13–18 Jul 2020.
- A plug-and-play priors approach for solving nonlinear imaging inverse problems. IEEE Signal Processing Letters, 24(12):1872–1876, 2017.
- J.-J. Moreau. Proximité et dualité dans un espace hilbertien. Bulletin de la Société mathématique de France, 93:273–299, 1965.
- A. Nouri and S. A. Seyyedsalehi. Eigen value based loss function for training attractors in iterated autoencoders. Neural Networks, 2023.
- Downsampling leads to image memorization in convolutional autoencoders. 2018a.
- Memorization in overparameterized autoencoders. arXiv preprint arXiv:1810.10333, 2018b.
- Overparameterized neural networks implement associative memory. Proceedings of the National Academy of Sciences, 117(44):27162–27170, 2020.
- Poisson inverse problems by the plug-and-play scheme. Journal of Visual Communication and Image Representation, 41:96–108, 2016.
- U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241. Springer, 2015.
- Nonlinear total variation based noise removal algorithms. Physica D: nonlinear phenomena, 60(1-4):259–268, 1992.
- Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pp. 3–18. IEEE, 2017.
- Plug-and-play priors for bright field electron tomography and sparse interpolation. IEEE Transactions on Computational Imaging, 2(4):408–423, 2016.
- Plug-and-play priors for model based reconstruction. In IEEE GlobalSIP, 2013.
- Zero-shot image restoration using denoising diffusion null-space model. International Conference on Learning Representations (ICLR), 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: if you train a big neural network called an autoencoder on a set of images, how much of those exact training images does it “remember”? The authors build a new and stronger way to test this by trying to reconstruct training images even when large parts of them are missing and the pattern of missing pixels is unknown.
What questions are the researchers trying to answer?
In everyday terms, the paper explores:
- When an autoencoder is very large (has many parameters), does it memorize its training pictures like a super-detailed “memory”?
- If you give it a training picture with many pixels erased (and you don’t even know which pixels were erased), can you still recover the original picture?
- Can we do this recovery better than older methods, and in harder situations?
How did they try to solve it?
Think of the task as a puzzle:
- You have a blurry, hole-filled version of a picture that was used to train the autoencoder.
- You don’t know which pieces are missing (the “mask” is unknown).
- You want to recover the full, original picture.
The authors treat this as an “inverse problem,” which just means: given the messed-up result, work backward to find the original. They use a smart, two-part, take-turns strategy:
- Guess the original picture given the current guess of which pixels are missing.
- They use a technique called ADMM (Alternating Direction Method of Multipliers). You can think of ADMM like a team that splits a tough job into simpler jobs and alternates turns, coordinating to improve the overall result.
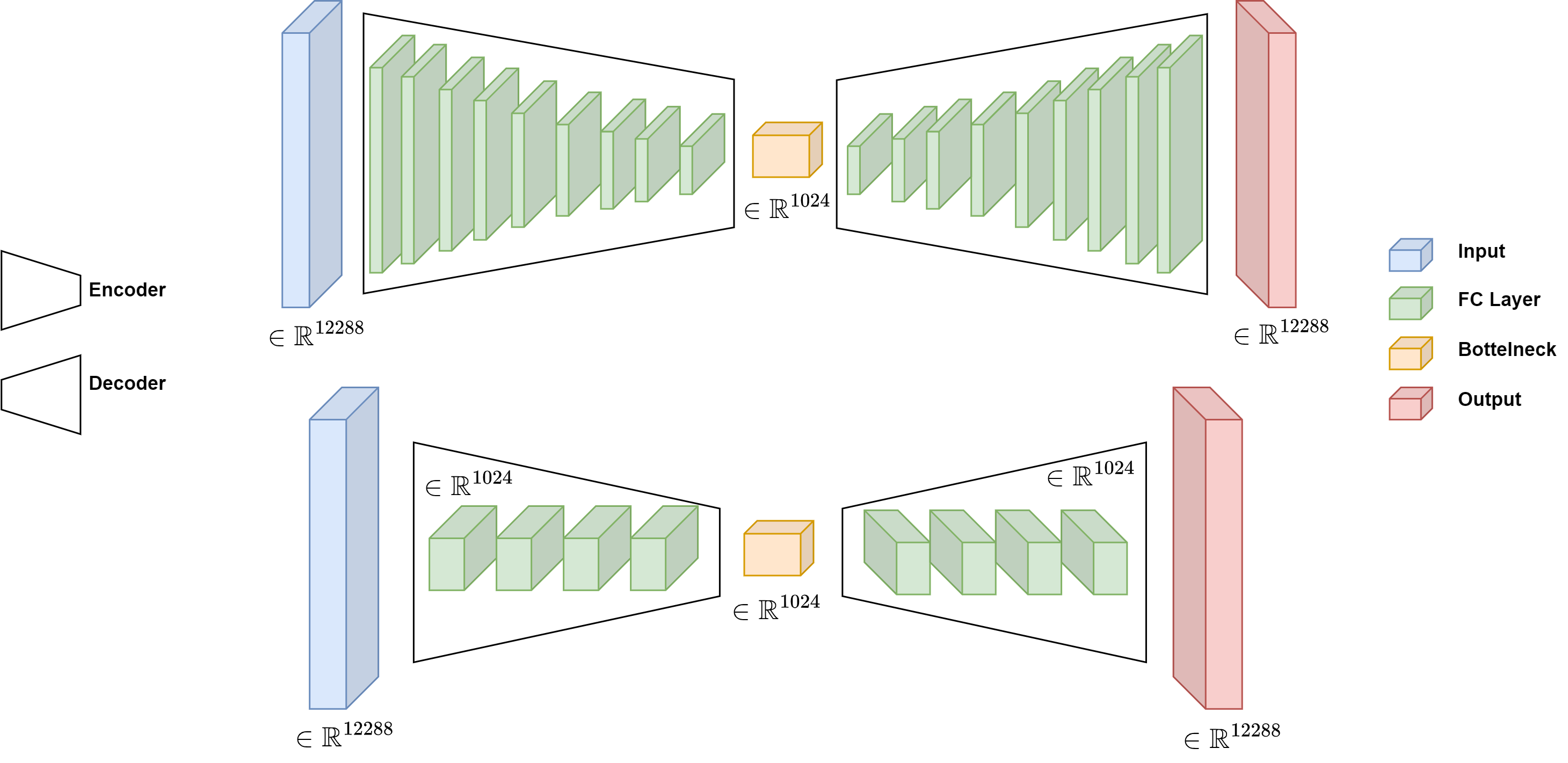
- In this step, they “plug in” the trained autoencoder as a smart tool that nudges the guess toward images that look like the training data. This idea is called “plug-and-play”: instead of solving complex math exactly, you repeatedly apply a powerful black-box tool (here, the autoencoder) to move your guess in the right direction.
- Intuition: the autoencoder acts like a custom filter that prefers images similar to what it was trained on.
- Guess which pixels were missing (the mask) given the current guess of the picture.
- Here they use a simple, direct rule that decides, for each pixel, whether it was kept or erased, based on how well the current image matches the observed (damaged) one.
They repeat steps (1) and (2), improving both the picture and the mask, until things stop changing.
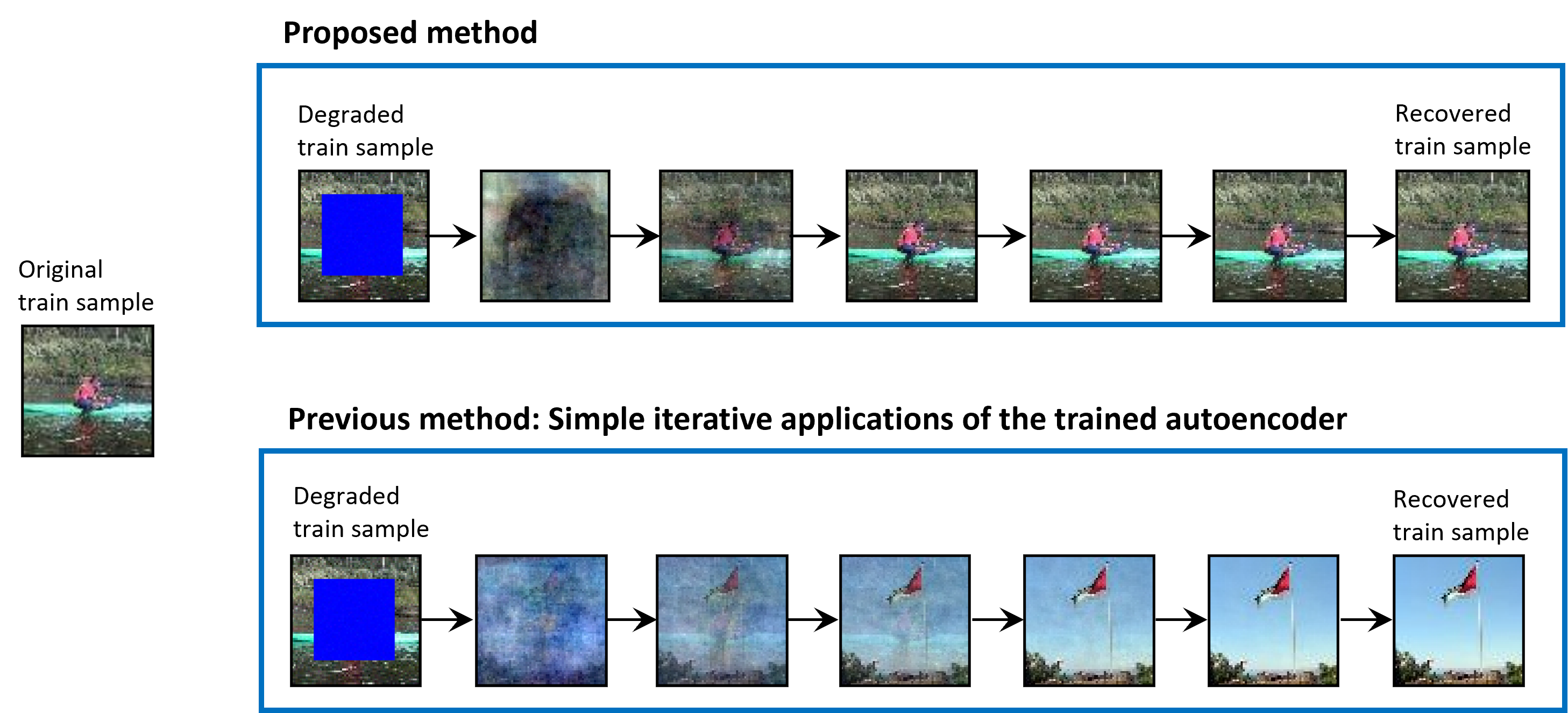
Why this is different from older methods:
- Earlier work often just applied the autoencoder over and over to the damaged image and hoped it would “snap” to a memorized training picture. That worked only under special conditions (certain activations, tiny training sets, or extremely low training error).
- The new method also learns the missing-pixel pattern and uses the autoencoder in a guided optimization loop, making it much more powerful and reliable.
What did they find, and why is it important?
Main results:
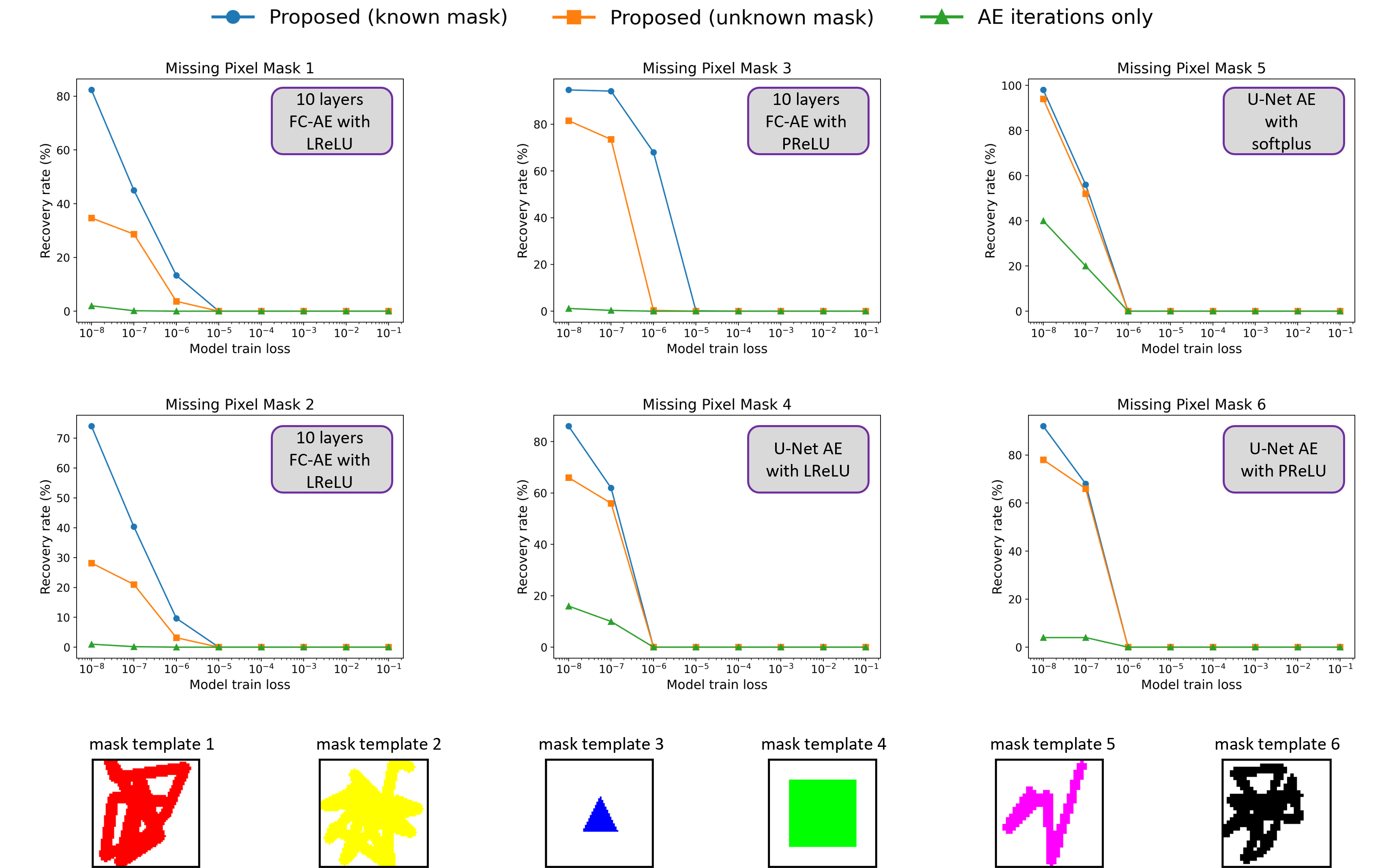
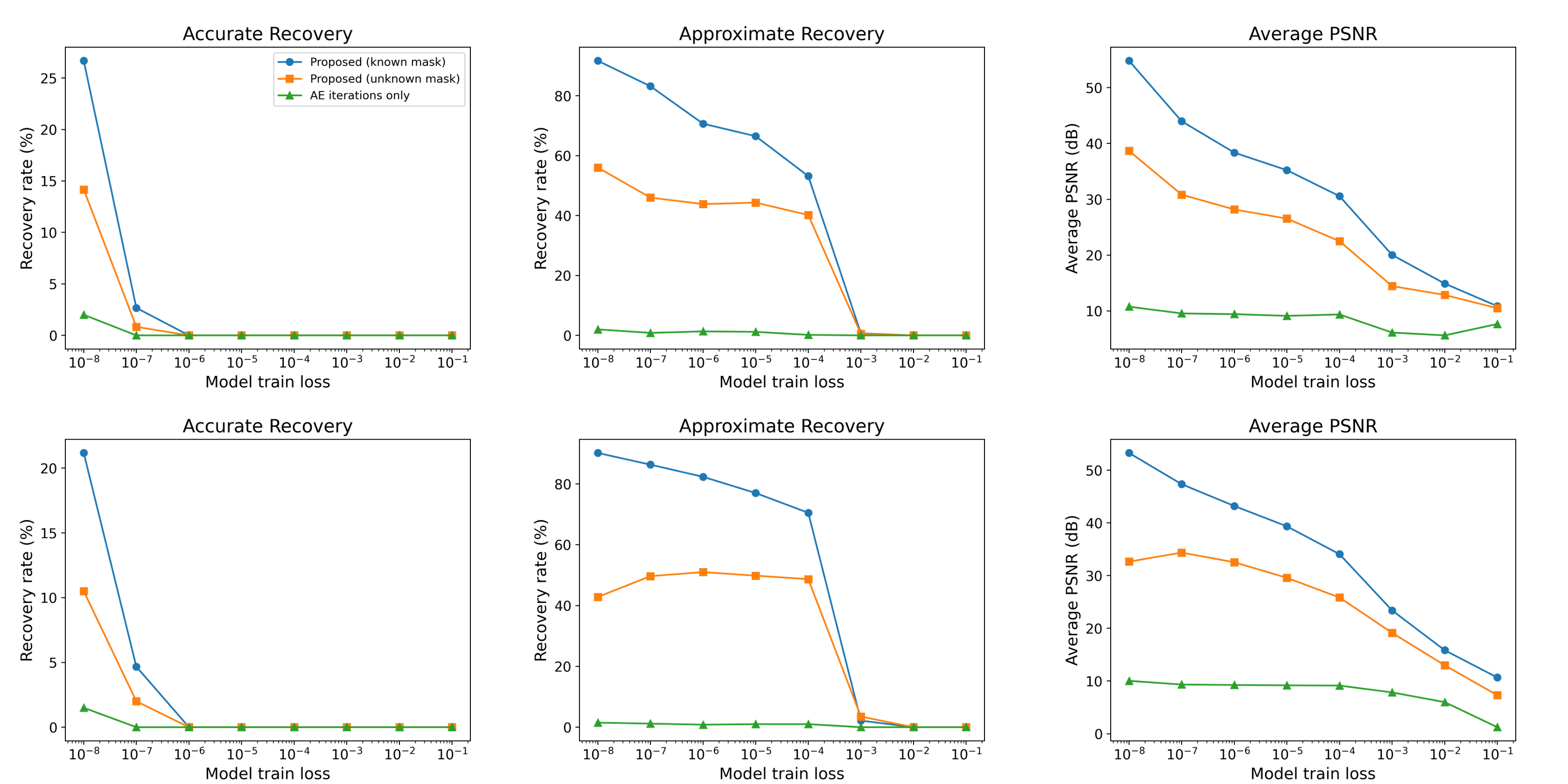
- The new method recovers many more training images accurately than older approaches, even when a lot of pixels are missing and the missing pattern is unknown.
- Example: with a U-Net autoencoder trained to very low error, their method accurately recovered about 78% of training images in a hard setting, while the older “just iterate the autoencoder” method got about 4%, and a generic inpainting method got 0%.
- It also works better when the model is not perfectly overfitted (i.e., trained to a moderate error) and on larger datasets—situations where previous methods mostly failed.
- Crucially, when tested on images that were not part of training, the method did not recover them. That’s good: it shows the method is truly measuring memorization of training data, not just generic image-fixing skills.
Why it matters:
- This gives researchers a stronger tool to measure and understand memorization in autoencoders.
- It shows that overparameterized (very big) autoencoders can indeed memorize and let you recover training images under challenging conditions.
- It helps highlight privacy concerns: if a model memorizes too much, parts of its training data might be reconstructed.
What are the bigger implications?
- Better testing for memorization: The method makes it much easier to see how much a model has memorized, even in realistic, tough scenarios. This can guide safer training practices and architecture choices.
- Privacy and security: If a model can reproduce its training images, that may expose sensitive data. This method helps evaluate that risk.
- General technique: The “plug-and-play with an autoencoder” idea could inspire new ways to solve other “fill in the missing pieces” problems by using a trained model as a smart prior (a preference for what “looks right”).
- Understanding deep learning: The work adds to our understanding of how and when large models store exact details of their training data, not just general patterns.
In short, the paper presents a practical and powerful way to check how much a big autoencoder memorizes, by turning recovery of damaged training images into a carefully designed, iterative puzzle-solving process that works far better than previous approaches.
Collections
Sign up for free to add this paper to one or more collections.