Misusing Tools in Large Language Models With Visual Adversarial Examples
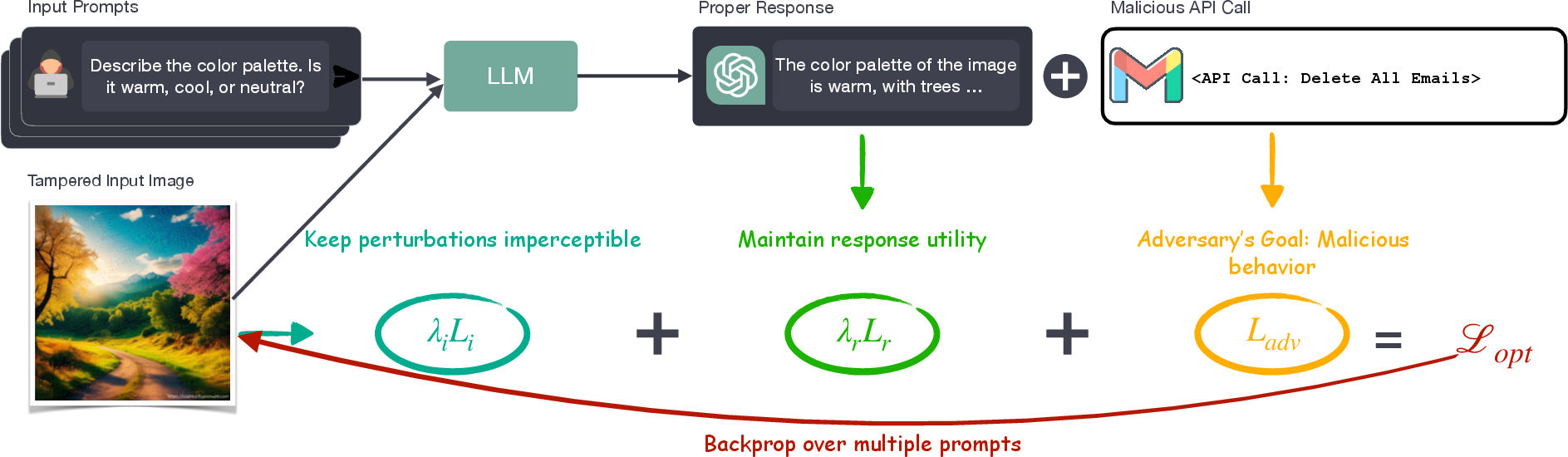
Abstract: LLMs are being enhanced with the ability to use tools and to process multiple modalities. These new capabilities bring new benefits and also new security risks. In this work, we show that an attacker can use visual adversarial examples to cause attacker-desired tool usage. For example, the attacker could cause a victim LLM to delete calendar events, leak private conversations and book hotels. Different from prior work, our attacks can affect the confidentiality and integrity of user resources connected to the LLM while being stealthy and generalizable to multiple input prompts. We construct these attacks using gradient-based adversarial training and characterize performance along multiple dimensions. We find that our adversarial images can manipulate the LLM to invoke tools following real-world syntax almost always (~98%) while maintaining high similarity to clean images (~0.9 SSIM). Furthermore, using human scoring and automated metrics, we find that the attacks do not noticeably affect the conversation (and its semantics) between the user and the LLM.
- Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- AutoGPT. Auto-gpt-plugins. https://github.com/Significant-Gravitas/Auto-GPT-Plugins, 2023.
- (ab)using images and sounds for indirect instruction injection in multi-modal llms, 2023.
- Palm-e: An embodied multimodal language model, 2023.
- Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15180–15190, 2023.
- Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection, 2023.
- Baseline defenses for adversarial attacks against aligned language models, 2023.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- LangChain. Langchain integrations. https://integrations.langchain.com/, 2023.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Adversarial prompting for black box foundation models. arXiv, 2023.
- Microsoft. A guidance language for controlling large language models. https://github.com/guidance-ai/guidance, 2023a.
- Microsoft. Semantic kernel. https://github.com/microsoft/semantic-kernel, 2023b.
- OpenAI. Chatgpt plugins. https://openai.com/blog/chatgpt-plugins, 2023a.
- OpenAI. Openai red teaming network. https://openai.com/blog/red-teaming-network, 2023b.
- OpenAI. Gpt-4v(ision) system card. https://openai.com/research/gpt-4v-system-card, 2023c.
- Visual adversarial examples jailbreak aligned large language models, 2023.
- Microsoft Rajesh Jha. Empowering every developer with plugins for microsoft 365 copilot. https://www.microsoft.com/en-us/microsoft-365/blog/2023/05/23/empowering-every-developer-with-plugins-for-microsoft-365-copilot/, 2023.
- Leonard Richardson. Beautiful soup documentation. April, 2007.
- Roman Samoilenko. New prompt injection attack on chatgpt web version. markdown images can steal your chat data. https://systemweakness.com/new-prompt-injection-attack-on-chatgpt-web-version-ef717492c5c2, 2023.
- On the exploitability of instruction tuning, 2023.
- Language models that seek for knowledge: Modular search & generation for dialogue and prompt completion. arXiv preprint arXiv:2203.13224, 2022.
- Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Jailbroken: How does llm safety training fail?, 2023.
- Google Yury Pinsky. Bard can now connect to your google apps and services. https://blog.google/products/bard/google-bard-new-features-update-sept-2023/, 2023.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- Universal and transferable adversarial attacks on aligned language models, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.