- The paper introduces GEAR, a distributed GPU-centric experience replay system that optimizes trajectory management, selection, and collection for large-scale reinforcement learning models.
- The methodology employs pipeline-aware trajectory sharding and zero-copy GPU memory access to reduce latency and achieve up to six times higher throughput compared to conventional systems like Reverb.
- Experimental validations with models such as Gato and MAT demonstrate consistent convergence and scalability, highlighting GEAR's efficacy in reducing operational costs and enhancing training performance.
Summary of "GEAR: A GPU-Centric Experience Replay System for Large Reinforcement Learning Models"
Introduction
The paper entitled "GEAR: A GPU-Centric Experience Replay System for Large Reinforcement Learning Models" (2310.05205) introduces GEAR, a distributed, GPU-centric experience replay system aimed at optimizing the training of large sequence models using reinforcement learning (RL). The framework addresses critical bottlenecks in existing systems like Reverb, particularly in memory, computation, and communication capacities, thereby enhancing the scalability and efficiency of RL tasks involving substantial sequence models such as transformers.
System Design and Architecture
Trajectory Management
GEAR innovatively facilitates trajectory management by decentralizing operations across distributed servers, each equipped with substantial GPU capacities. This approach mitigates the need for numerous additional servers traditionally required for trajectory storage, thereby reducing operational costs. The design incorporates pipeline-aware trajectory sharding, optimizing data locality by considering pipeline parallelism topologies.
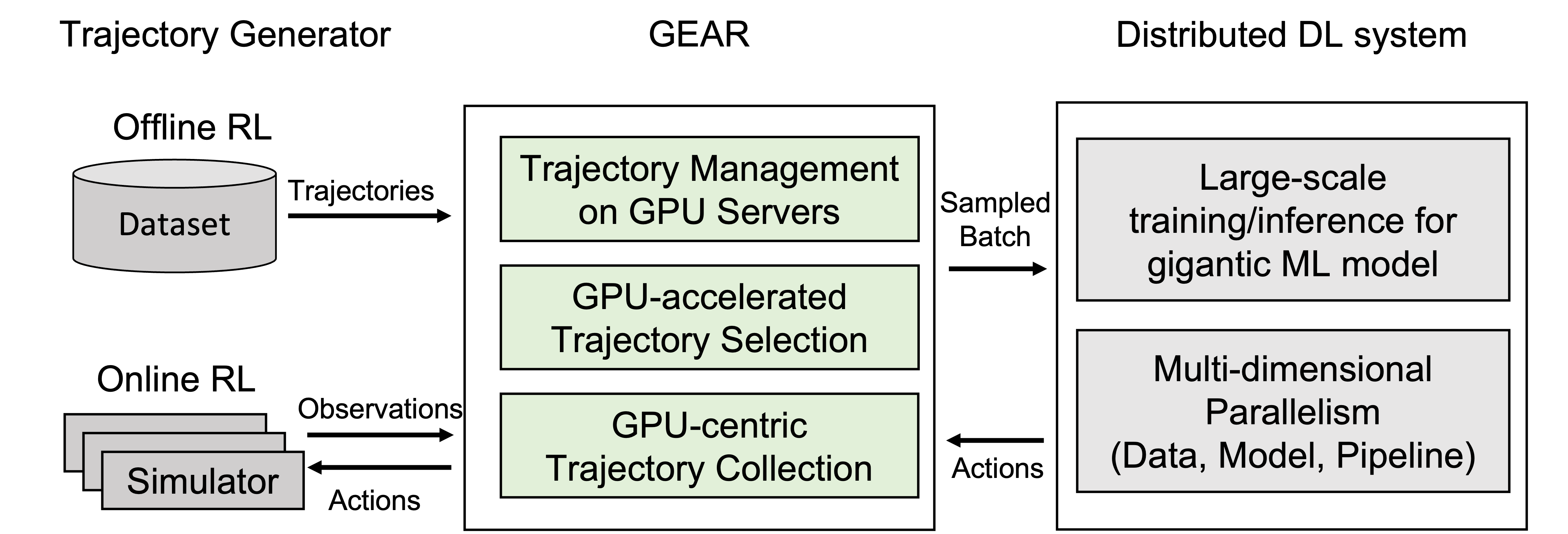
Figure 1: Overview of GEAR.
Trajectory data is stored efficiently in columnar formats, enabling quick access to specific fields during retrieval processes. The system leverages trajectory sharding strategies that take advantage of multi-dimensional parallelism to enhance the efficiency of trajectory collection and storage.
Trajectory Selection
GEAR employs distributed GPUs to perform trajectory selection, a process traditionally hampered by computational inefficiency and communication overhead in CPU-centric frameworks. It supports both centralized and decentralized selection strategies, with GPU-enhanced operations that significantly reduce communication and processing time compared to existing methods.
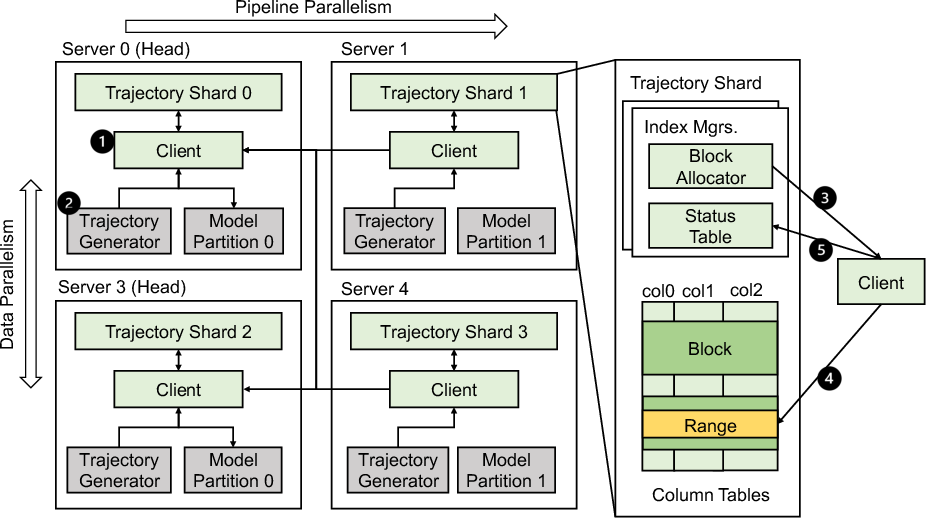
Figure 2: Trajectory management on distributed training servers.
Centralized selection ensures consistent training outcomes, while decentralized methods allow parallel processing across multiple GPUs, optimizing selection tasks for large datasets. This dual approach enhances scalability and accuracy in trajectory selection.
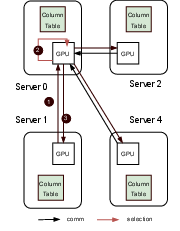
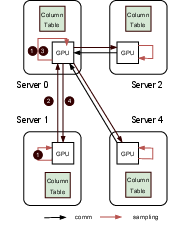
Figure 3: Centralized and decentralized trajectory selection.
Trajectory Collection
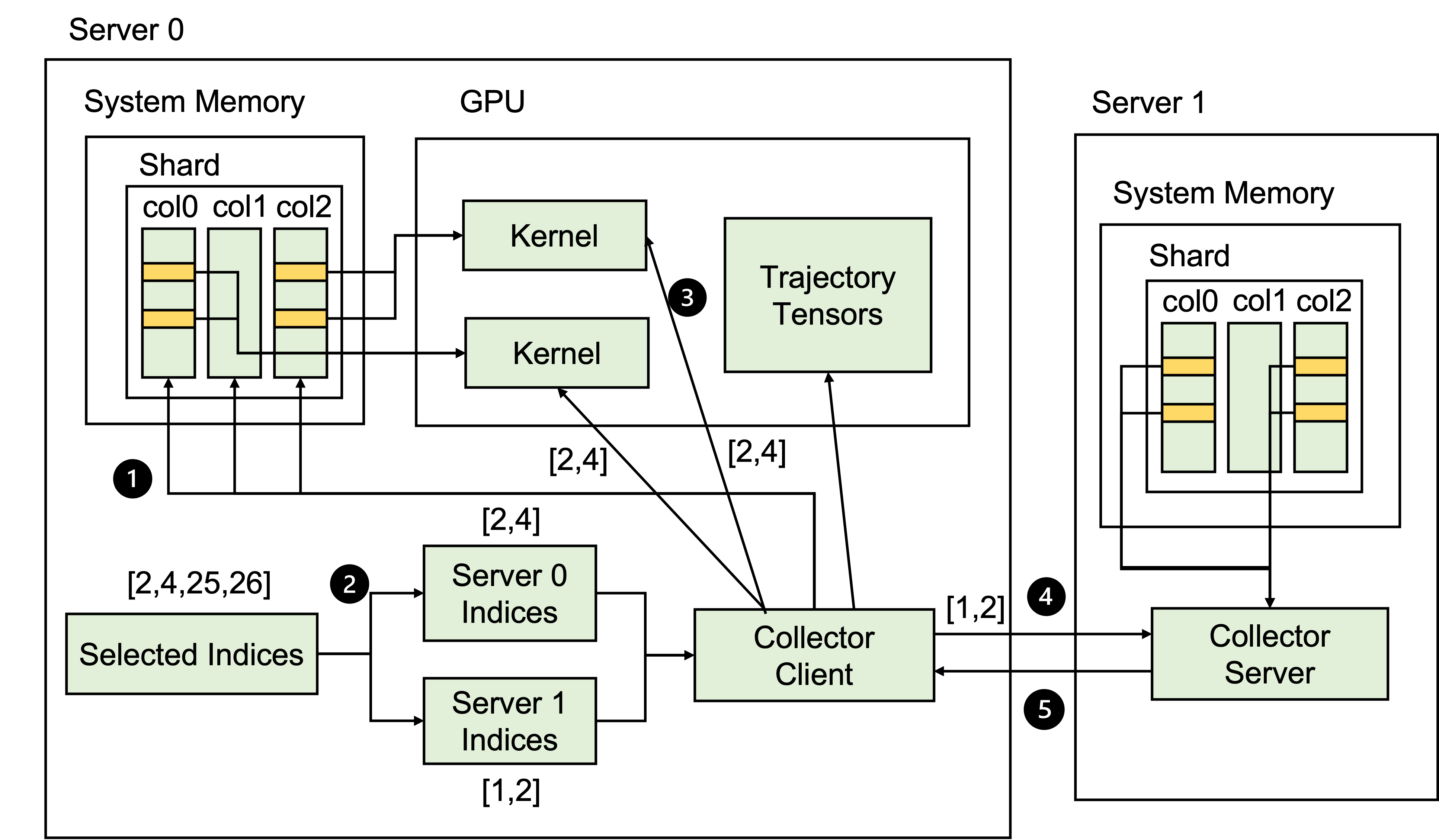
Figure 4: Trajectory collection on distributed GPUs.
GEAR further innovates in trajectory collection by enabling GPU-centric operations that minimize latency. It utilizes zero-copy access features of NVIDIA GPUs and InfiniBand for high-bandwidth data transfer, enhancing throughput significantly. These capabilities are instrumental in reducing data movement and serialization overheads, fostering efficient large-scale RL model training.
Experimental Validation
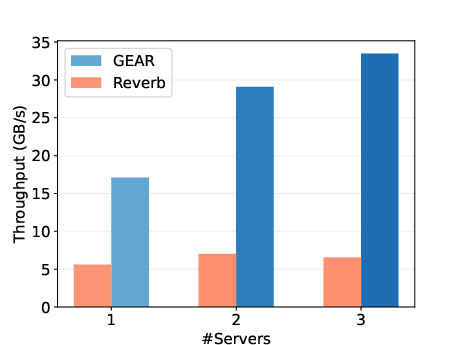
Figure 5: End-to-end throughput comparison with Reverb.
GEAR undergoes extensive evaluations against Reverb, demonstrating superior throughput performance under varied trajectory sizes and batch configurations. Experimental setups spanning multiple nodes establish GEAR's capacity to achieve up to six times higher throughput than Reverb, highlighting the system's scalability and efficiency.
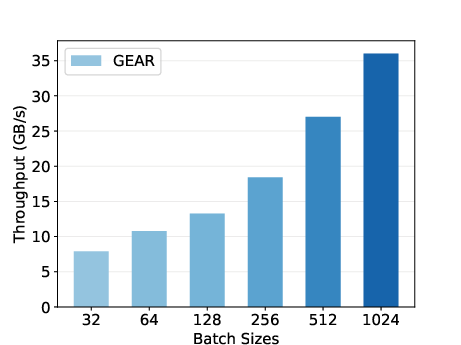
Figure 6: Trajectory collection throughput with varied batch sizes.
Trajectory collection performance with increasing batch sizes showcases GEAR's capability to scale linearly, starting from 8 GB/s with smaller batches to reaching 36 GB/s at larger configurations.
Model Convergence
The paper details the successful application of GEAR in training state-of-the-art large RL models such as Gato and MAT, illustrating consistent convergence behavior in complex tasks, validating GEAR's robustness and integration capabilities with existing parallelism libraries.
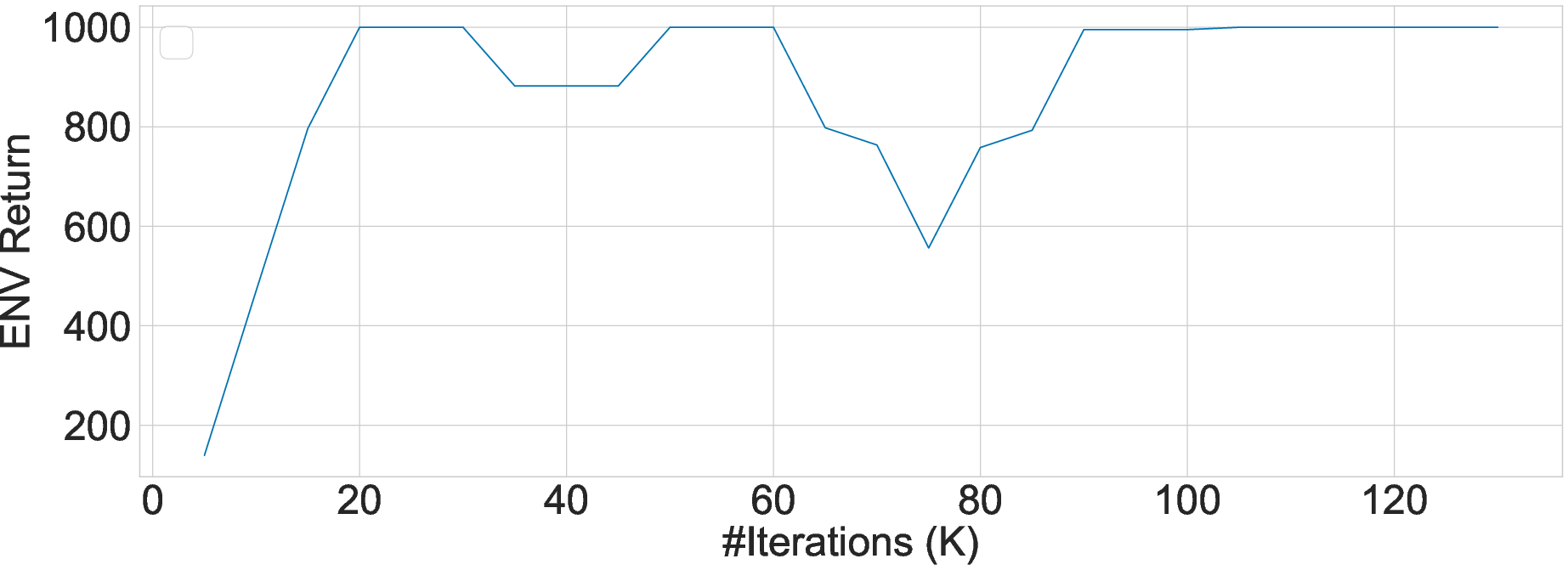
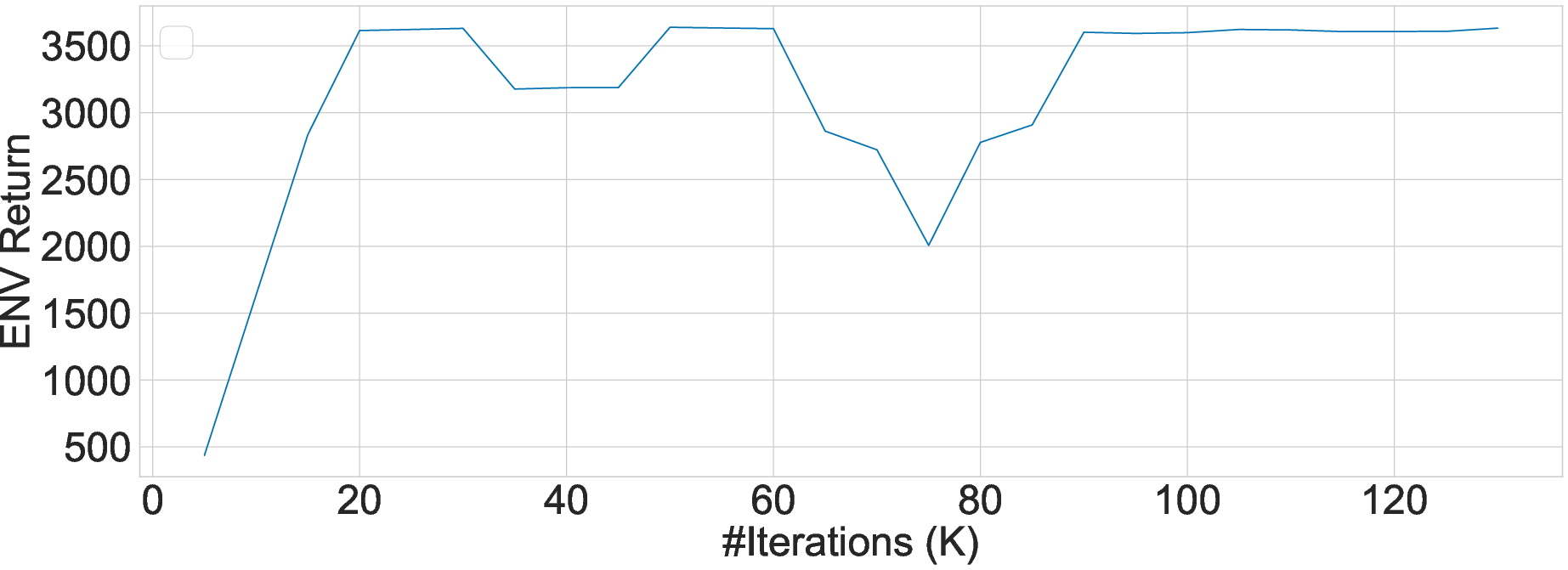
Figure 7: Convergence experiment of GATO with GEAR. The x-axis is the number of iterations and the y-axis is the environment return.
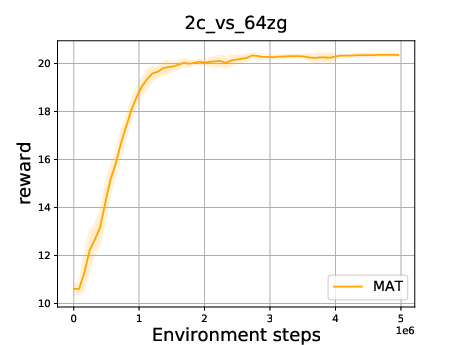
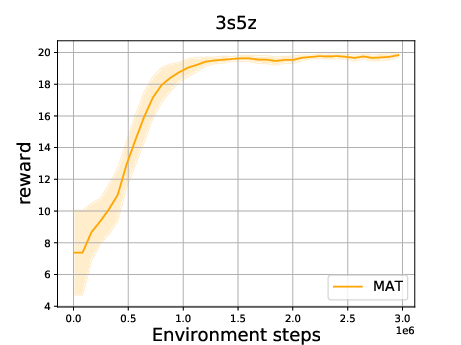
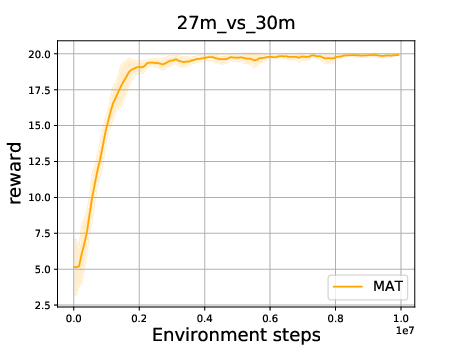
Figure 8: Convergence experiment of MAT with GEAR. The x-axis is the environment steps and the y-axis is the reward.
Conclusion and Future Work
GEAR stands out as a substantial advancement in experience replay systems for large-scale RL models, providing remarkable efficiency gains in trajectory management, selection, and collection. Its GPU-centric design is poised to play an integral role in facilitating the training of expansive and intricate RL models.
The paper acknowledges several limitations, notably the need for further research into scalability with even larger models and datasets, and seamless integration across the entire RL pipeline. Future developments are anticipated to expand GEAR's applicability and refine its architecture to accommodate evolving AI demands.