- The paper presents GeM-CoT, a framework that overcomes traditional Chain-of-Thought limitations by dynamically selecting task-specific demonstrations via a type matching module.
- The methodology leverages Sentence-BERT for semantic similarity, enabling automated demonstration selection for both matched and unmatched question types.
- Experimental results on 10 reasoning tasks and 23 BBH tasks demonstrate significant accuracy improvements and broader generalization over traditional Zero-Shot and Few-Shot approaches.
Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with LLMs
Introduction
The paper presents GeM-CoT, a novel Chain-of-Thought (CoT) prompting mechanism designed for mixed-task scenarios in LLMs. Traditional CoT prompting methods, such as General Zero-Shot-CoT and Specific Few-Shot-CoT, face challenges in balancing generalization with performance. The General Zero-Shot-CoT method lacks performance due to its broad applicability, while Specific Few-Shot-CoT suffers from poor generalization because it heavily relies on pre-defined task-specific demonstrations. GeM-CoT addresses these limitations by categorizing question types and leveraging automatic pattern construction from pre-constructed demo pools to enhance performance across diverse task types without manual intervention.
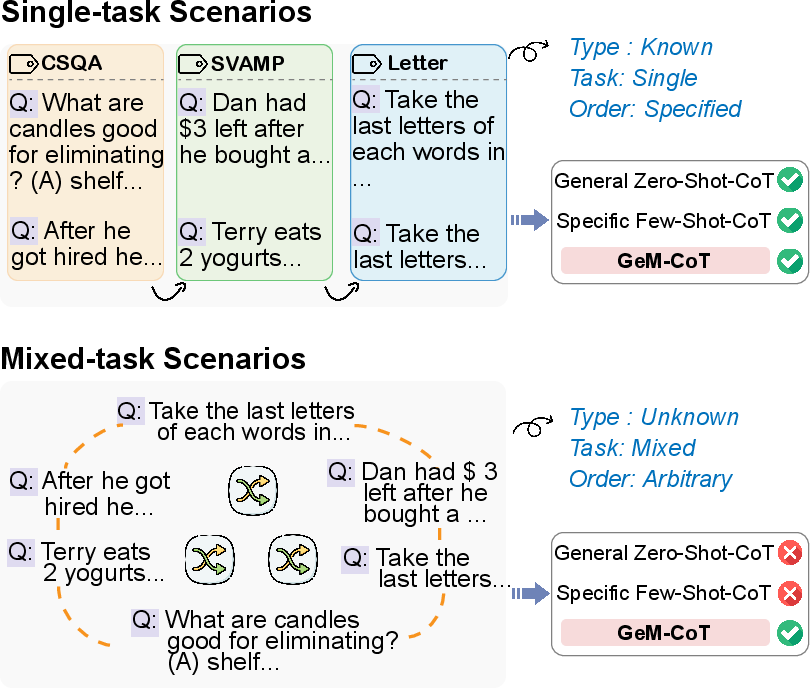
Figure 1: Comparison of conventional single-task scenarios and our proposed setting: mixed-task scenarios.
GeM-CoT Mechanism
GeM-CoT introduces a mechanism for handling unknown types of input questions in mixed-task scenarios by utilizing a Type Matching module to guide questions into paths based on successful or failed matches. Successfully matched questions obtain demonstrations from a demo pool for inference, while unmatched questions undergo zero-shot reasoning, followed by caching for clustering and demonstration construction. This two-pronged strategy ensures adaptability and preserves high-performance capabilities across varied reasoning tasks.
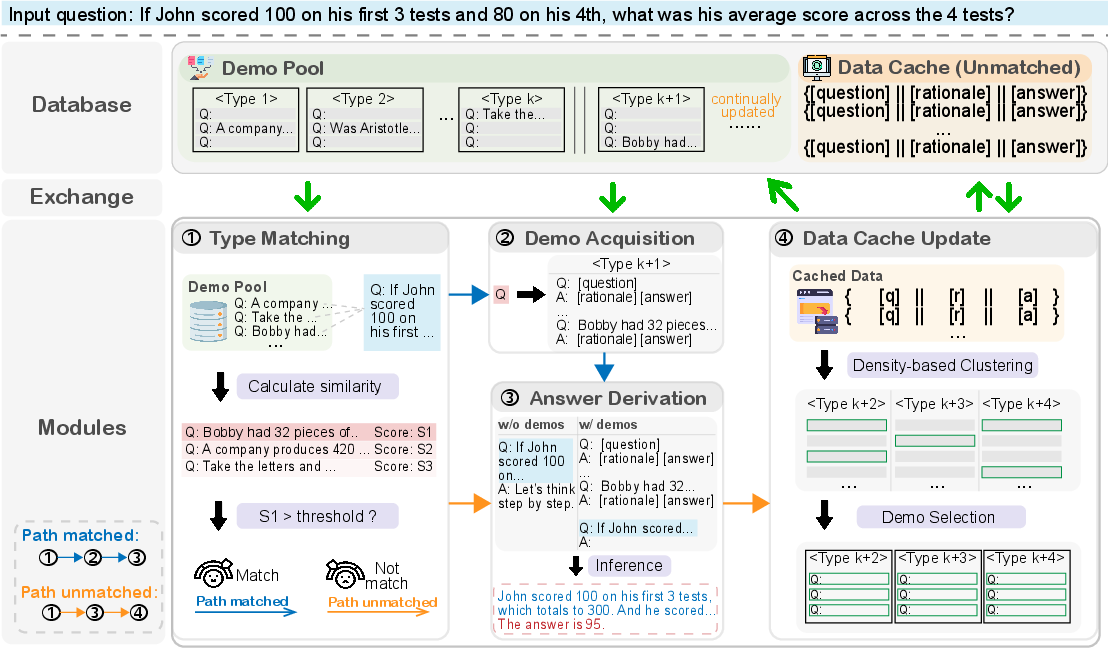
Figure 2: Overview of our proposed GeM-CoT mechanism. GeM-CoT routes the input question to different paths, facilitating both matched and unmatched scenarios.
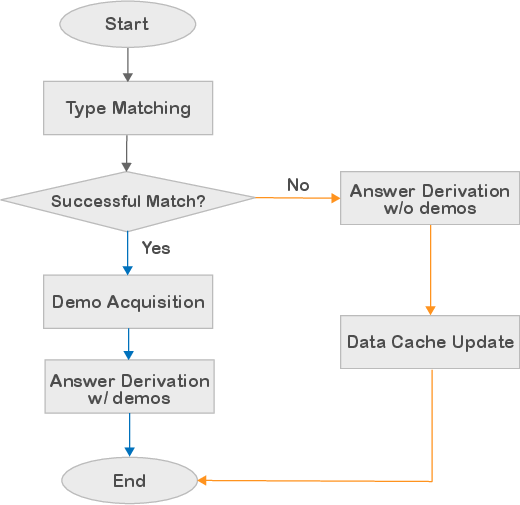
Figure 3: Flow chart of our GeM-CoT mechanism depicting the routing mechanism based on the Type Matching module.
Experimental Results
Experiments conducted on 10 reasoning tasks and 23 BIG-Bench Hard (BBH) tasks demonstrate GeM-CoT's ability to outperform or match existing CoT prompting techniques in accuracy while maintaining broader generalization. Particularly, GeM-CoT's design allows it to handle questions of unknown types in automated and generalizable fashions, yielding an average accuracy improvement across datasets and showing competitive results against both Zero-Shot and Few-Shot approaches.
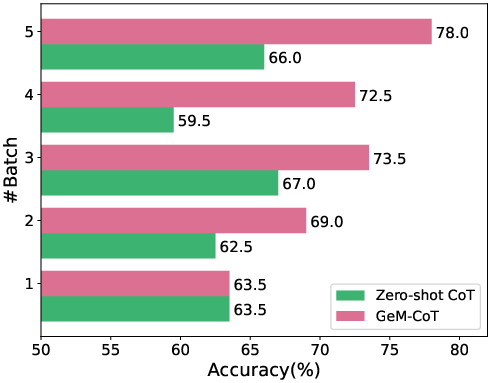
Figure 4: Process of five subsequent streaming batch data with batch size of 400 on BBH datasets.
Analysis of Type Matching and Demonstration Selection
GeM-CoT's Type Matching module utilizes Sentence-BERT for semantic similarity, allowing it to autonomously assign question types based on contextual relevance rather than handcrafted rules. This feature is especially beneficial in realistic scenarios where mixed-type questions are common. GeM-CoT emphasizes diverse demonstration selection to enhance generalization and avoids pitfalls associated with less varied datasets that lead to suboptimal performance.
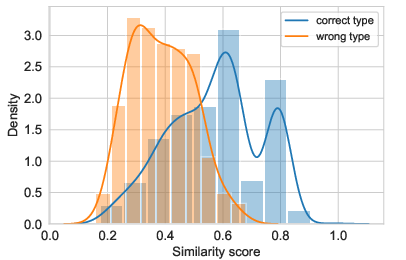
Figure 5: Distribution of similarity scores in Type Matching module with separate presentation of correctly and incorrectly matched scores.
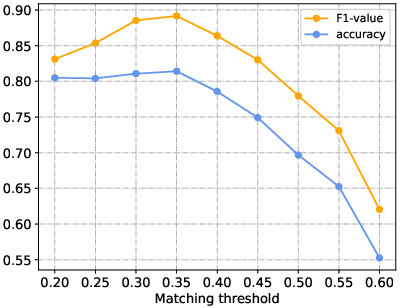
Figure 6: F1 value and accuracy of type matching with respect to varying matching thresholds.
Conclusion
GeM-CoT presents a significant advancement in CoT prompting, excelling in mixed-task scenarios by bridging the gap between generalizability and performance without requiring task-specific adjustments. This framework not only broadens the applicability of LLMs in real-world task settings but also supports future developments in adaptive reasoning processes by demonstrating the successful integration of automated type classification, dynamic demonstration handling, and scalable inference techniques. The approach sets a precedent for further exploration into the integration of LLMs into diverse application infrastructures, aiming towards more autonomous and robust AI systems.