LLark: A Multimodal Instruction-Following Language Model for Music
Abstract: Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for \emph{music} understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained LLM. In evaluations on three types of tasks (music understanding, captioning, reasoning), we show that LLark matches or outperforms existing baselines in music understanding, and that humans show a high degree of agreement with its responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LLark: A simple explanation
What is this paper about?
This paper introduces LLark, an AI system that can listen to short clips of music and answer questions about them using plain language. It can do things like tell the tempo (speed), name the instruments, describe the mood, write captions for the music, and even explain why a song might fit a certain setting (like studying or a party). The goal is to make a single model that understands music in many ways, not just one task.
What questions were the researchers trying to answer?
They focused on three big questions:
- Can one model understand core musical facts, like tempo, key, genre, and instruments?
- Can it write clear, detailed captions that describe what you hear in a song?
- Can it reason about music at a higher level, like explaining style, mood, or appropriate uses?
How does LLark work? (Methods explained simply)
Think of LLark as a team made of three parts:
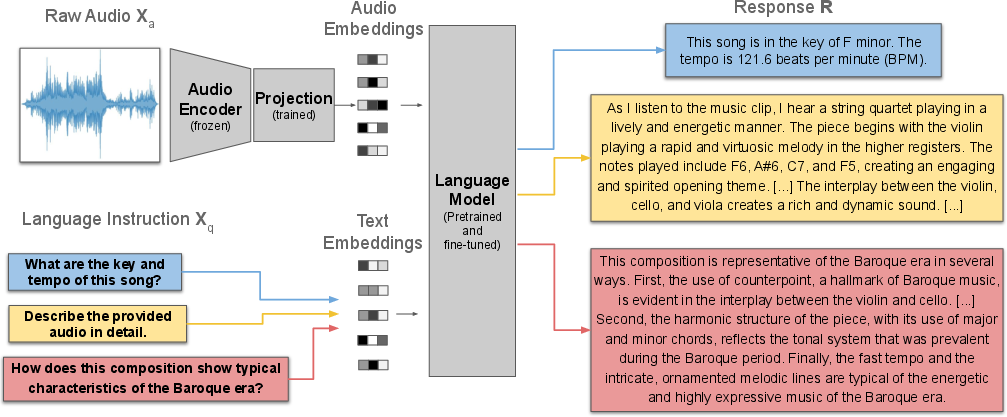
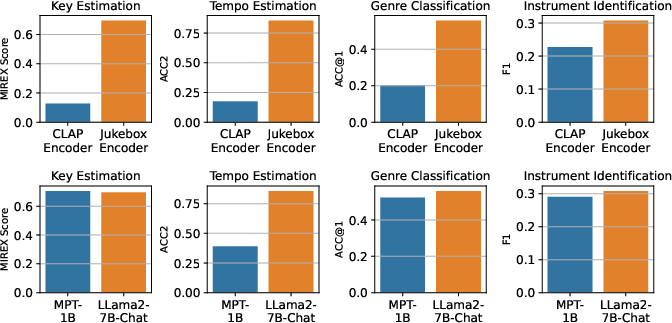
- The “ears” (audio encoder): This part listens to the music and turns the sound into numbers a computer can work with. The paper uses a strong “listening” model called Jukebox. It’s generative, which means it’s trained to model music in a rich way, not just label it.
- The “translator” (projection layer): This is a small adapter that helps the “ears” talk to the “brain” below. It maps the music numbers into a form the language part understands.
- The “brain” (LLM): This is a LLM (Llama 2) that reads questions and the music features, and then writes the answer in natural language.
How LLark is trained:
- Instruction-tuning: Imagine giving the model lots of practice questions and answers so it learns to follow instructions, like “What is the tempo?” or “Describe this clip.”
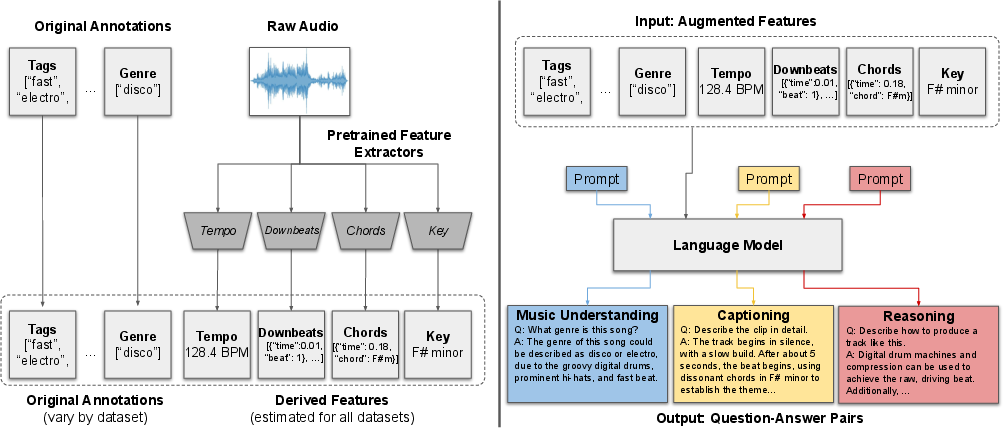
- Unified format: Music data on the internet is messy and comes with different kinds of labels. The authors collected open music datasets and converted all the different annotations into a single question–answer style format so one model could learn from all of them.
- Smart data augmentation: Many songs don’t come with detailed musical facts. So the authors used trusted music tools to estimate things like tempo (speed in BPM), key (like “F# minor”), chords over time, and beats. These extra details were used to create better practice questions and more accurate answers.
- Building lots of practice: Using both the original labels and the added musical facts, they asked a LLM (like ChatGPT) to generate multiple question–answer pairs for each song clip, covering three families of tasks: understanding, captioning, and reasoning. In total, they created over a million such pairs from more than a hundred thousand tracks.
A note on clip length:
- LLark listens to 25-second clips. That’s long enough to catch the main feel of a song, but not the entire thing.
What did they find, and why does it matter?
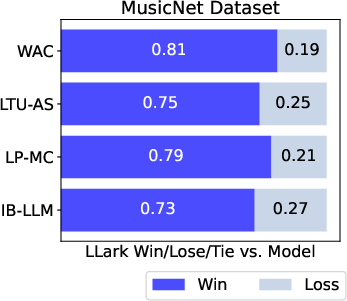
Music understanding (facts like tempo, key, genre, instruments):
- LLark often matched or beat other general audio–LLMs on these tasks, even though many of the test datasets were “zero-shot” (the model hadn’t seen them during training).
- On some tasks, LLark came close to the best specialized models that were trained only for that one task. That’s impressive because LLark is a single model handling many tasks at once.
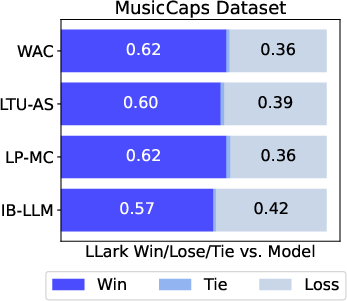
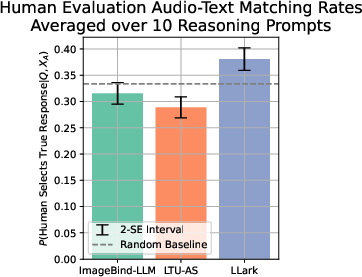
Captioning (describing what you hear):
- In human studies, people usually preferred LLark’s captions over those from other models. LLark’s captions tended to include more musical detail (e.g., specific instruments, playing styles) rather than vague or irrelevant descriptions.
- Even when evaluated by another AI (GPT-4), LLark’s captions were judged to contain more musical specifics than the baselines.
Reasoning (higher-level explanations):
- Reasoning about music is hard—sometimes it requires skills even human non-musicians don’t have. Still, LLark’s answers were more aligned with the actual audio and included more musical detail than other multimodal models in the study.
- Human raters and GPT-4 both favored LLark’s responses more often, though the authors note that evaluating this fairly is challenging without expert musicians.
Why this matters:
- A single “listen-and-talk” model that understands music can help with accessibility (audio descriptions), music discovery (better search and recommendations), education (explaining theory and structure), and creative tools (summaries, mood matches, script ideas with music).
What are the limitations and what comes next?
Limitations:
- 25-second hearing window: LLark only listens to short clips at a time. Longer context could help with songs that change a lot.
- Non-expert evaluators: Some human tests used raters who weren’t trained musicians, which may miss finer musical points.
- Bias and coverage: Music datasets tend to focus on Western music and common instruments. This can limit how well the model understands other musical traditions.
- No copyrighted training audio: LLark uses only open-source datasets. While this is ethical and transparent, more varied (but copyrighted) data might improve performance—though that raises legal and ethical issues.
Future directions:
- Better “ears” and “brain”: Upgrading the audio encoder and LLM (or scaling them up) could lead to bigger gains than just adding more of the same training data.
- Richer musical annotations: Using improved tools for tempo, key, chords, and beyond would lead to better training examples.
- Better benchmarks: The field needs higher-quality tests for music tasks—especially for reasoning—so progress can be measured fairly and reliably.
Bottom line
LLark shows that an instruction-following, multimodal AI can learn to listen to music and talk about it clearly. By adding musical details to training data and connecting a strong “listener” to a strong “writer,” the authors built a single model that does well on many music tasks at once. This is a step toward music-savvy AI that can help people understand, explore, and create with music more easily.
Collections
Sign up for free to add this paper to one or more collections.