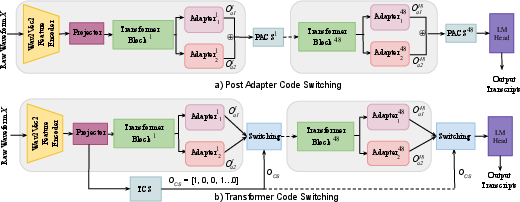
- The paper introduces novel adapter configurations, namely PACS and TCS, to optimize multilingual ASR performance on code-switched speech.
- It employs a Wav2Vec 2.0 framework with dynamic, frame-level binary switching to effectively modulate language adapter outputs.
- Experiments on Mandarin-English, Arabic-English, and Hindi-English datasets demonstrate significant reductions in Character Error Rates (CER) and Mixed Error Rates (MER).
Adapting the Adapters for Code-Switching in Multilingual ASR
The paper "Adapting the adapters for code-switching in multilingual ASR" (2310.07423) presents methods for fine-tuning large pre-trained multilingual speech models on code-switched speech. The goal is to address the limitations inherent in the existing formulations of language adapters, particularly when dealing with code-switching scenarios where two languages are mixed within the same utterance.
Introduction and Motivation
Multilingual ASR systems incorporating language adapters can enhance performance by capturing language-specific features while sharing parameters for cross-lingual transfer. However, code-switching, an inherently challenging phenomenon in spoken language, degrades performance due to the need for models to recognize and predict mixed language patterns within an utterance. The paper proposes solutions to enable effective fine-tuning of such models on code-switched speech by integrating information from multiple language adapters. Specifically, it conceptualizes the code-switching process as a sequence of latent binary sequences guiding information flow from each language adapter at the frame level.
Proposed Approaches
This research introduces two innovative methods for adapting adapters in the MMS ASR architecture, which relies on the Wav2Vec 2.0 framework:
Post Adapter Code Switching (PACS)
PACS integrates outputs from two language adapters corresponding to the matrix and embedded languages, merging them at each language adaptation point in the network.
TCS introduces a transformer network to estimate binary sequences demarcating CS points within utterances.
- Architecture: TCS predicts frame-level CS points, allowing the network to switch adapter output paths dynamically based on estimated binary codes.
- Activation: The transformer block uses a sigmoid activation function, partitioning the outputs into mask sequences that blend language-specific adapter outputs.
- Output Regulation: The binary code sequence modulates the combination of adapter outputs through multiplication, enhancing the model's sensitivity to CS phenomena.
Data Preparation and Evaluation
The evaluation utilizes three code-switched datasets: ASCEND, ESCWA, and MUCS, representing Mandarin-English, Arabic-English, and Hindi-English language pairs. Baseline results indicate that pre-trained MMS models perform inadequately on CS tasks using a single adapter, emphasizing the need for CS-specific fine-tuning. The proposed approaches significantly reduce Character Error Rates (CER) across datasets by effectively integrating adapter outputs.
Experimental Setup
The models are fine-tuned using the CTC loss function with a learning rate adjustment strategy involving initial warm-up phases. Experiments are conducted on Nvidia A100 GPUs, utilizing the HuggingFace Transformers library. The results demonstrate substantial improvements in CER and Mixed Error Rate (MER) through the proposed approaches compared to baseline MMS and Whisper models.
Results and Discussion
Both PACS and TCS outperform direct fine-tuning of MMS language adapters, offering consistent reductions in error rates across all datasets. The TCS model demonstrates superior performance, underscoring its ability to dynamically adapt language representations at the frame level while maintaining a minimal increase in parameter count.
An intriguing observation is the Whisper model's inherent strength on CS tasks even without retraining, posing a benchmark for comparison. The proposed approaches, however, provide a modular solution for rapidly deploying multilingual ASR systems with CS capabilities, especially in lower-resourced language scenarios.
Conclusion
The paper introduces novel configurations for modulating language adapters in the MMS framework for enhanced CS speech recognition. By allowing controlled, frame-level language predictions, these strategies offer robust improvements without substantial increases in computational demands. Future work may explore integrating external LLMs or reinforcement learning techniques to further refine CS recognition capabilities.