Alpha Elimination: Using Deep Reinforcement Learning to Reduce Fill-In during Sparse Matrix Decomposition
Abstract: A large number of computational and scientific methods commonly require decomposing a sparse matrix into triangular factors as LU decomposition. A common problem faced during this decomposition is that even though the given matrix may be very sparse, the decomposition may lead to a denser triangular factors due to fill-in. A significant fill-in may lead to prohibitively larger computational costs and memory requirement during decomposition as well as during the solve phase. To this end, several heuristic sparse matrix reordering methods have been proposed to reduce fill-in before the decomposition. However, finding an optimal reordering algorithm that leads to minimal fill-in during such decomposition is known to be a NP-hard problem. A reinforcement learning based approach is proposed for this problem. The sparse matrix reordering problem is formulated as a single player game. More specifically, Monte-Carlo tree search in combination with neural network is used as a decision making algorithm to search for the best move in our game. The proposed method, alphaElimination is found to produce significantly lesser non-zeros in the LU decomposition as compared to existing state-of-the-art heuristic algorithms with little to no increase in overall running time of the algorithm. The code for the project will be publicly available here\footnote{\url{https://github.com/misterpawan/alphaEliminationPaper}}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper looks at a common math tool called LU decomposition, which helps solve lots of equations quickly. The problem is: when the original matrix (a big grid of numbers) is mostly zeros—called “sparse”—the LU process can accidentally create many new non-zeros, a mess called “fill-in.” That slows everything down and uses lots of memory. The authors propose a new AI method, called Alpha Elimination, that learns a smart order to process the rows so that much less fill-in happens.
What the researchers wanted to find out
They asked:
- Can we use reinforcement learning (a kind of AI that learns by trial and error) to pick the best order of rows so LU decomposition creates fewer extra non-zeros?
- Can this learned method beat popular “rule-based” tricks (heuristics) that people already use?
- Can it do that without taking too long?
How they did it (in simple terms)
First, some key ideas in everyday language:
- Sparse matrix: Imagine a huge grid where most squares are empty (zeros) and only a few have dots (non-zeros).
- LU decomposition: A way to break a matrix into two triangular pieces (L and U) that make solving equations faster—like reorganizing a messy bookshelf so you can find books quickly.
- Fill-in: During LU, zeros can turn into non-zeros—like making new messes while cleaning. More fill-in = more work and more memory.
- Reordering rows: Choosing the order in which you clean (process) rows can avoid making extra messes.
- NP-hard: A fancy way of saying “this is super hard to solve perfectly, even for very fast computers.”
Now, their approach:
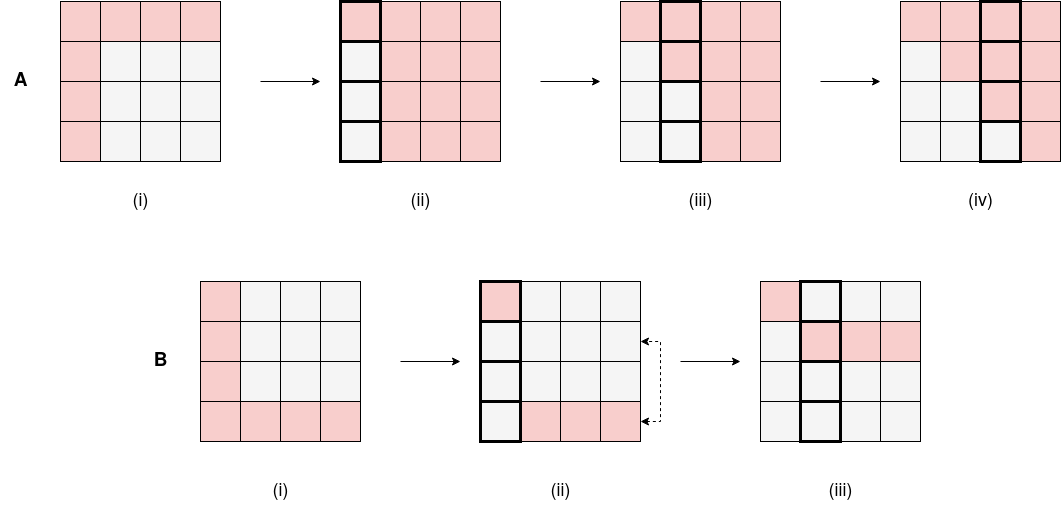
- They turned row ordering into a single-player “game.” At each step, the “player” picks which row to use next (the pivot) to eliminate values in a column. The “score” (reward) is better when fewer new non-zeros are created.
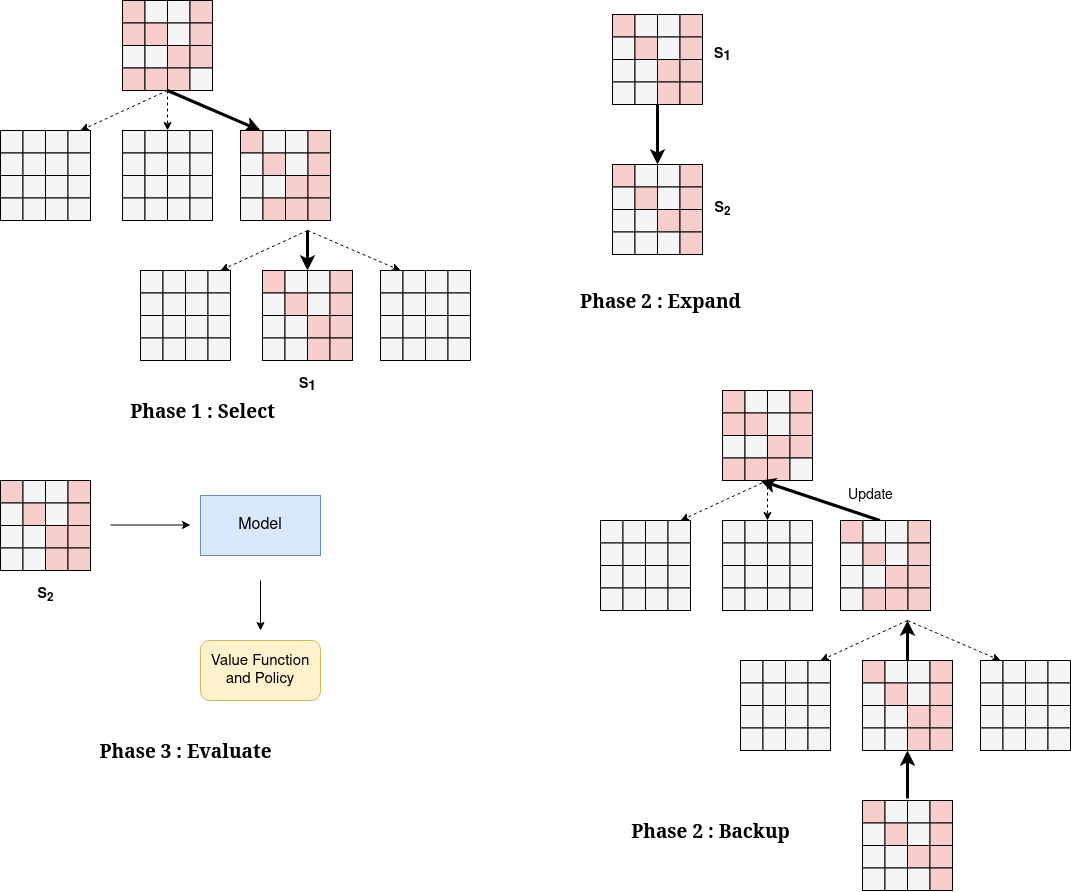
- They used Deep Reinforcement Learning (DRL), specifically Monte Carlo Tree Search (MCTS) plus a neural network, inspired by how AlphaGo learned to play Go.
- Think of MCTS like planning many possible future moves in a board game and choosing the path that leads to the best long-term result.
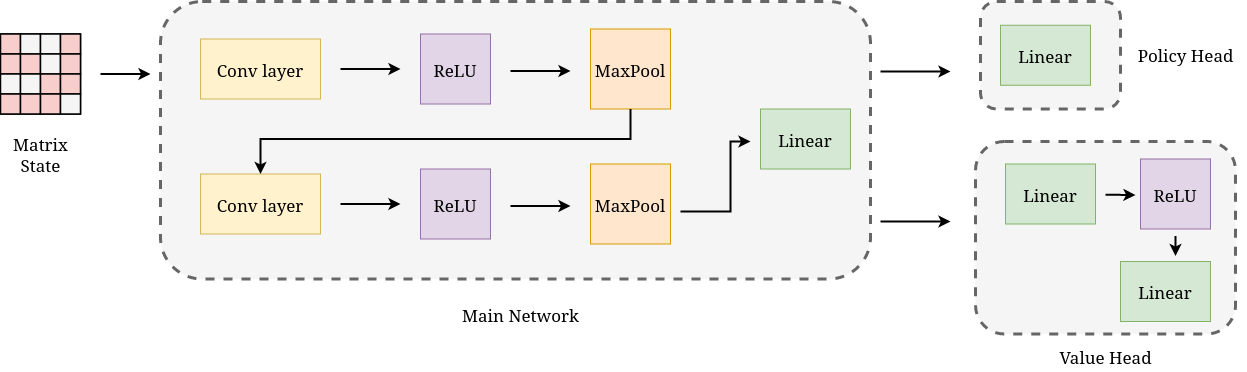
- The neural network is like a guide that looks at the current matrix (as if it were an image) and suggests which move looks promising, plus how good the position is.
- Game pieces (in RL terms):
- State: The current matrix and which column we’re eliminating now.
- Action: Pick a row that has a non-zero in the current column; swap it to the top and eliminate below.
- Reward: Fewer new non-zeros = higher reward (they give negative points for creating fill-in, so less is better).
- Training details:
- The neural network reads the matrix like a picture using a convolutional neural network (CNN). To make learning easier, they “mask” the matrix: they replace all non-zeros with 1 and zeros with 0, so the network focuses on where the dots are, not their exact values.
- The model learns by self-play: it repeatedly tries reorderings, sees the results, and improves its strategy.
- To handle very large matrices, they split big problems into smaller chunks using a graph partitioning tool (METIS). This is similar to dividing a huge puzzle into smaller sections.
What they found and why it matters
They tested on many real-world matrices (from engineering, graphics, networks, etc.) and compared against widely used methods like ColAMD, SymAMD, and SymRCM.
Main results (in plain terms):
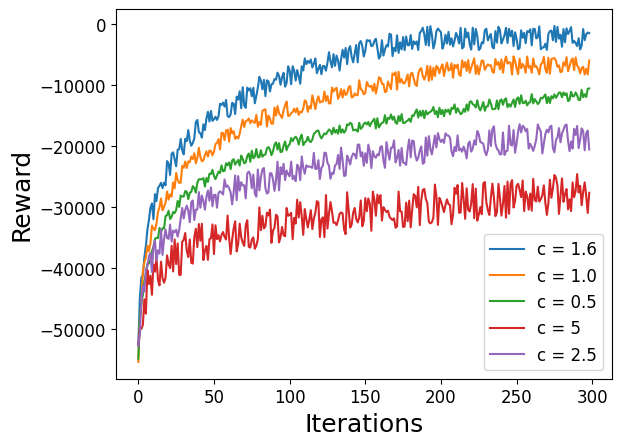
- Alpha Elimination produced significantly fewer non-zeros in the LU factors than the standard heuristics and the naive “no reordering” approach.
- On large matrices, it cut fill-in by up to about:
- 61% compared to naive LU (no special ordering).
- 40% compared to the best heuristic methods.
- Fewer non-zeros means:
- Less memory needed to store the factors.
- Faster computation when solving the system.
- Importantly, this improvement came with little to no increase in total running time (ordering plus factorization), especially on larger problems where the savings add up.
Why this is important and what could come next
- Impact:
- Many scientific and engineering tasks rely on solving big systems of equations fast (think simulations, computer graphics, machine learning, physics, economics). Reducing fill-in saves time and memory across these fields.
- This work shows that reinforcement learning can discover better strategies than hand-made rules for tricky math problems.
- What’s next:
- Make the neural network scale even better to huge matrices.
- Combine the AI method with existing heuristics to get the best of both worlds.
- Improve numerical stability (in LU, picking the largest pivot can be safer; the authors note this as future work).
- Bonus: They plan to share code online so others can try it.
In short, Alpha Elimination is like teaching a smart assistant to choose the order of cleaning in a giant, sparse grid so that you don’t create more mess than necessary—and it works better than the usual rules people have used for years.
Collections
Sign up for free to add this paper to one or more collections.