Scalable Neural Network Kernels
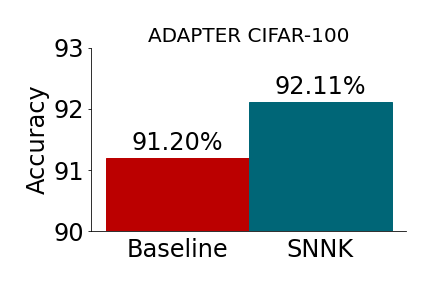
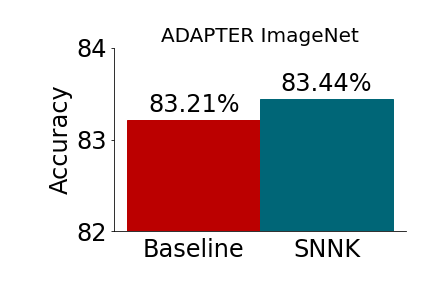
Abstract: We introduce the concept of scalable neural network kernels (SNNKs), the replacements of regular feedforward layers (FFLs), capable of approximating the latter, but with favorable computational properties. SNNKs effectively disentangle the inputs from the parameters of the neural network in the FFL, only to connect them in the final computation via the dot-product kernel. They are also strictly more expressive, as allowing to model complicated relationships beyond the functions of the dot-products of parameter-input vectors. We also introduce the neural network bundling process that applies SNNKs to compactify deep neural network architectures, resulting in additional compression gains. In its extreme version, it leads to the fully bundled network whose optimal parameters can be expressed via explicit formulae for several loss functions (e.g. mean squared error), opening a possibility to bypass backpropagation. As a by-product of our analysis, we introduce the mechanism of the universal random features (or URFs), applied to instantiate several SNNK variants, and interesting on its own in the context of scalable kernel methods. We provide rigorous theoretical analysis of all these concepts as well as an extensive empirical evaluation, ranging from point-wise kernel estimation to Transformers' fine-tuning with novel adapter layers inspired by SNNKs. Our mechanism provides up to 5x reduction in the number of trainable parameters, while maintaining competitive accuracy.
- An almost optimal unrestricted fast johnson-lindenstrauss transform. ACM Trans. Algorithms, 9(3):21:1–21:12, 2013. doi: 10.1145/2483699.2483701. URL https://doi.org/10.1145/2483699.2483701.
- Scaling learning algorithms towards ai. In L. Bottou, O. Chapelle, D. DeCoste, and J. Weston (eds.), Large-scale kernel machines. MIT Press, 2007.
- A corrective view of neural networks: Representation, memorization and learning. In Jacob Abernethy and Shivani Agarwal (eds.), Proceedings of Thirty Third Conference on Learning Theory, volume 125 of Proceedings of Machine Learning Research, pp. 848–901. PMLR, 09–12 Jul 2020. URL https://proceedings.mlr.press/v125/bresler20a.html.
- Adaptformer: Adapting vision transformers for scalable visual recognition. arXiv preprint arXiv:2205.13535, 2022.
- Kernel methods for deep learning. In Y. Bengio, D. Schuurmans, J. Lafferty, C. Williams, and A. Culotta (eds.), Advances in Neural Information Processing Systems, volume 22. Curran Associates, Inc., 2009. URL https://proceedings.neurips.cc/paper_files/paper/2009/file/5751ec3e9a4feab575962e78e006250d-Paper.pdf.
- Analysis and extension of arc-cosine kernels for large margin classification. CoRR, abs/1112.3712, 2011. URL http://arxiv.org/abs/1112.3712.
- The geometry of random features. In Amos J. Storkey and Fernando Pérez-Cruz (eds.), International Conference on Artificial Intelligence and Statistics, AISTATS 2018, 9-11 April 2018, Playa Blanca, Lanzarote, Canary Islands, Spain, volume 84 of Proceedings of Machine Learning Research, pp. 1–9. PMLR, 2018. URL http://proceedings.mlr.press/v84/choromanski18a.html.
- Hybrid random features, 2022.
- The unreasonable effectiveness of structured random orthogonal embeddings. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 219–228, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/bf8229696f7a3bb4700cfddef19fa23f-Abstract.html.
- Rethinking attention with performers. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=Ua6zuk0WRH.
- A sparse johnson–lindenstrauss transform. CoRR, abs/1004.4240, 2010. URL http://arxiv.org/abs/1004.4240.
- An elementary proof of a theorem of johnson and lindenstrauss. Random Struct. Algorithms, 22(1):60–65, 2003. doi: 10.1002/rsa.10073. URL https://doi.org/10.1002/rsa.10073.
- Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009. doi: 10.1109/CVPR.2009.5206848.
- BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://aclanthology.org/N19-1423.
- Linearized two-layers neural networks in high dimension, 2020.
- Deep Learning. Adaptive computation and machine learning. MIT Press, 2016. ISBN 978-0-262-03561-3. URL http://www.deeplearningbook.org/.
- Random gegenbauer features for scalable kernel methods, 2022.
- Towards a unified view of parameter-efficient transfer learning. In International Conference on Learning Representations, 2022a. URL https://openreview.net/forum?id=0RDcd5Axok.
- Learning with asymmetric kernels: Least squares and feature interpretation. IEEE Trans. Pattern Anal. Mach. Intell., 45(8):10044–10054, 2023. doi: 10.1109/TPAMI.2023.3257351. URL https://doi.org/10.1109/TPAMI.2023.3257351.
- Parameter-efficient model adaptation for vision transformers. arXiv preprint arXiv:2203.16329, 2022b.
- Orthogonal recurrent neural networks with scaled cayley transform. In Jennifer G. Dy and Andreas Krause (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pp. 1974–1983. PMLR, 2018. URL http://proceedings.mlr.press/v80/helfrich18a.html.
- Parameter-efficient transfer learning for NLP. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 2790–2799. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/houlsby19a.html.
- LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Neural tangent kernel: Convergence and generalization in neural networks, 2020.
- Visual prompt tuning. In European Conference on Computer Vision (ECCV), 2022.
- Random feature maps for dot product kernels. In Neil D. Lawrence and Mark Girolami (eds.), Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, volume 22 of Proceedings of Machine Learning Research, pp. 583–591, La Palma, Canary Islands, 21–23 Apr 2012. PMLR. URL https://proceedings.mlr.press/v22/kar12.html.
- Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks. In Annual Meeting of the Association for Computational Linguistics, 2021.
- An image is worth 16x16 words: Transformers for image recognition at scale. In Ninth International Conference on Learning Representations. ICLR, 2021.
- Kernel methods for learning languages. Theor. Comput. Sci., 405(3):223–236, 2008. doi: 10.1016/j.tcs.2008.06.037. URL https://doi.org/10.1016/j.tcs.2008.06.037.
- Cifar-10 (canadian institute for advanced research), 2009. URL http://www.cs.toronto.edu/~kriz/cifar.html.
- MNIST handwritten digit database. http://yann.lecun.com/exdb/mnist/, 2010.
- Deep learning. Nat., 521(7553):436–444, 2015. doi: 10.1038/nature14539. URL https://doi.org/10.1038/nature14539.
- What would elsa do? freezing layers during transformer fine-tuning, 2019.
- Chefs’ random tables: Non-trigonometric random features. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/df2d62b96a4003203450cf89cd338bb7-Abstract-Conference.html.
- Favor#: Sharp attention kernel approximations via new classes of positive random features. CoRR, abs/2302.00787, 2023. doi: 10.48550/arXiv.2302.00787. URL https://doi.org/10.48550/arXiv.2302.00787.
- Decoupled weight decay regularization, 2019.
- A kernel-based view of language model fine-tuning. arXiv preprint arXiv:2210.05643, 2022.
- Unipelt: A unified framework for parameter-efficient language model tuning, 2022.
- Adaptable adapters. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3742–3753, Seattle, United States, July 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.naacl-main.274.
- Radford M. Neal. Priors for infinite networks, 1996. URL https://api.semanticscholar.org/CorpusID:118117602.
- Learning with non-positive kernels. In Carla E. Brodley (ed.), Machine Learning, Proceedings of the Twenty-first International Conference (ICML 2004), Banff, Alberta, Canada, July 4-8, 2004, volume 69 of ACM International Conference Proceeding Series. ACM, 2004. doi: 10.1145/1015330.1015443. URL https://doi.org/10.1145/1015330.1015443.
- Adapterhub: A framework for adapting transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020): Systems Demonstrations, pp. 46–54, Online, 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.7.
- Random features for large-scale kernel machines. In J. Platt, D. Koller, Y. Singer, and S. Roweis (eds.), Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007. URL https://proceedings.neurips.cc/paper_files/paper/2007/file/013a006f03dbc5392effeb8f18fda755-Paper.pdf.
- Geometrically coupled monte carlo sampling. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 195–205, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/b3e3e393c77e35a4a3f3cbd1e429b5dc-Abstract.html.
- Adapterdrop: On the efficiency of adapters in transformers, 2021.
- A spectral analysis of dot-product kernels, 2021.
- Jürgen Schmidhuber. Deep learning in neural networks: An overview. CoRR, abs/1404.7828, 2014. URL http://arxiv.org/abs/1404.7828.
- Learning with kernels : support vector machines, regularization, optimization, and beyond. Adaptive computation and machine learning. MIT Press, 2002. URL http://www.worldcat.org/oclc/48970254.
- Learning potentials of quantum systems using deep neural networks, 2021.
- Implicit neural representations with periodic activation functions. In Proc. NeurIPS, 2020.
- Improved random features for dot product kernels. arXiv preprint arXiv:2201.08712, 2022a.
- Complex-to-real random features for polynomial kernels. arXiv preprint arXiv:2202.02031, 2022b.
- GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 353–355, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/W18-5446. URL https://aclanthology.org/W18-5446.
- Christopher K. I. Williams. Computing with infinite networks. In Proceedings of the 9th International Conference on Neural Information Processing Systems, NIPS’96, pp. 295–301, Cambridge, MA, USA, 1996. MIT Press.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.
- Towards a unified view on visual parameter-efficient transfer learning. ArXiv, abs/2210.00788, 2022. URL https://api.semanticscholar.org/CorpusID:252683240.
- Orthogonal random features. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pp. 1975–1983, 2016. URL https://proceedings.neurips.cc/paper/2016/hash/53adaf494dc89ef7196d73636eb2451b-Abstract.html.
- Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.