- The paper introduces VideoPrompter, a framework that fuses discriminative vision-language models with generative text models to improve zero-shot video analysis.
- It employs language-guided visual feature enhancement and video-specific prompts to generate enriched semantic representations of video content.
- Experimental results demonstrate significant improvements in action recognition and retrieval tasks, emphasizing the framework's efficacy in handling complex temporal dynamics.
Videoprompter: An Ensemble of Foundational Models for Zero-Shot Video Understanding
Introduction
The paper "Videoprompter: an ensemble of foundational models for zero-shot video understanding" (2310.15324) introduces a novel framework, VideoPrompter, designed to enhance the capabilities of existing vision-LLMs (VLMs) in zero-shot video understanding settings. This framework combines discriminative vision-LLMs with generative video-to-text and text-to-text models to improve the interpretative scope of video content through enriched semantic representations. The methodology addresses key challenges in extending pre-trained image-LLMs to video tasks, primarily focusing on the limitations of current text-based classifier improvements which overlook visual content.
Proposed Framework
The VideoPrompter framework introduces two major modifications to the standard zero-shot video classification setup:
- Language-Guided Visual Feature Enhancement: This involves using a video-to-text model to transform the input video into detailed textual descriptions that capture essential visual cues such as object presence and their spatio-temporal interactions. The generated descriptions are then integrated with VLMs, providing additional semantic context that enhances zero-shot performance.
- Video-Specific Prompts: By employing video-specific language descriptors and constructing a Tree Hierarchy of Categories, this component enriches class label representations. The prompting techniques generate high-level action contexts and language attributes which resolve ambiguities among closely related fine-grained classes.
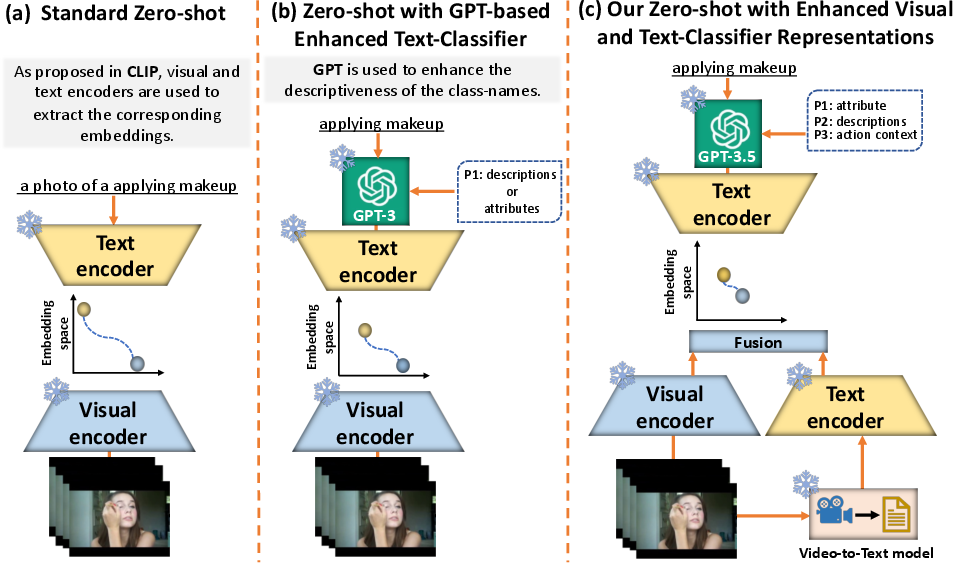
Figure 1: The standard pre-training paradigm for zero-shot classification and the proposed VideoPrompter framework, highlighting enhancements in both classifier and visual representations.
Experimental Validation
The paper evaluates VideoPrompter across three zero-shot video understanding tasks: video action recognition, video-to-text and text-to-video retrieval, and time-sensitive video tasks, demonstrating consistent improvements over various benchmarks and models. For instance, significant top-1 accuracy gains are seen in action recognition settings compared to existing methods like CLIP, with enhancements noted even in traditional approaches requiring extensive training [Figures 3 & 4].
The study emphasizes the capability of VideoPrompter to handle complex temporal dynamics in videos, showcasing improved interpretability and time-awareness in VLMs. This is particularly evident in time-sensitive video tasks, where VideoPrompter enhances performance by effectively incorporating temporal cues from generated descriptions.
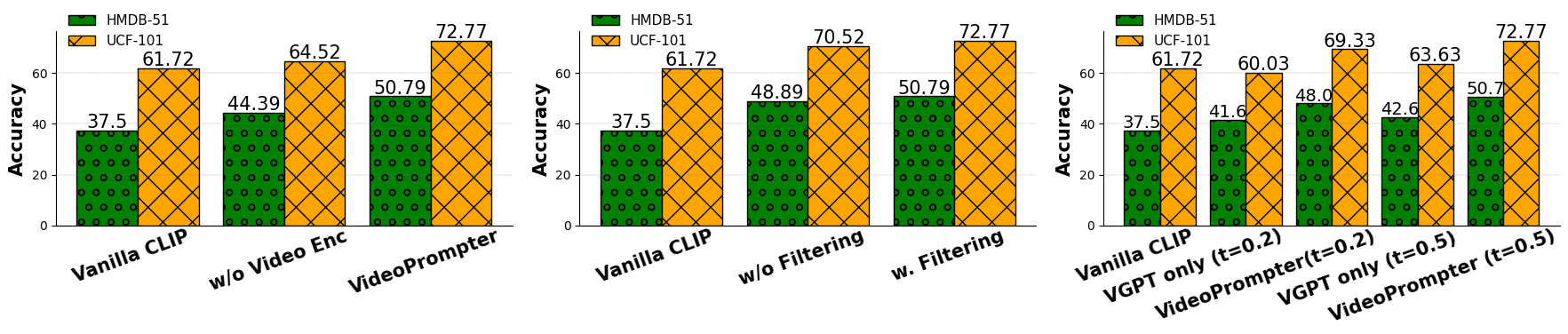
Figure 2: VideoPrompter's effectiveness in combining embeddings from query videos and their textual descriptions, with additional gains from preprocessing techniques like CLIP-based filtering.
Discussion on Design and Components
The paper explores various design choices, analyzing the contribution of individual components to the overall framework's performance. Removing either the video-to-text or text-to-text module, filtering erroneous descriptions, and exploiting the diversity of video textual descriptions are examined. Notably, a higher temperature setting in VideoPrompter's description generation leads to more diverse and effective results, underscoring the importance of description variability in enhancing VLMs' interpretative accuracy.
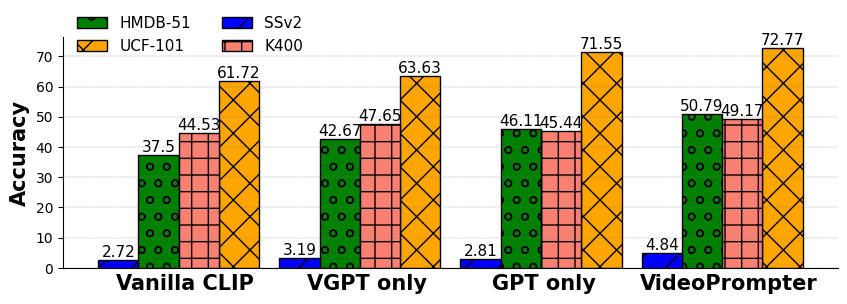
Figure 3: Complementary nature of video-textual descriptions and language descriptors in VideoPrompter, leading to optimal results across benchmarks.
Conclusion and Future Directions
VideoPrompter compellingly demonstrates how integrating generative text models with existing VLMs can bridge existing gaps in zero-shot video understanding. By addressing limitations in both visual and textual realms, the framework paves the way for future explorations into more nuanced semantic networks and contextual learning paradigms in AI models.
Further research could explore the potential of extending such frameworks to additional domains and test configurations or enhancing the interpretability mechanisms provided by the LLMs. The work underscores a significant step towards refined video understanding capabilities in zero-shot contexts, highlighting directions for practical and theoretical advancements in AI and machine learning models.