- The paper introduces TD-MPC2, which advances model-based reinforcement learning with an implicit world model and unified hyperparameters for diverse control tasks.
- It employs encoder latent dynamics, reward prediction, and model predictive control to optimize trajectories across 104 continuous tasks.
- Experimental results and ablation studies demonstrate few-shot learning capabilities and scalability improvements over traditional model-free and model-based approaches.
TD-MPC2: Scalable, Robust World Models for Continuous Control
Introduction
The paper introduces TD-MPC2, an improved model-based reinforcement learning (RL) algorithm building on its predecessor, TD-MPC. The enhancements focus on achieving superior performance across a diverse range of tasks using a single set of hyperparameters. TD-MPC2 is designed to consume large, uncurated datasets, accommodating variations between tasks in an unsupervised manner.
An overview of the improved results of TD-MPC2 against existing model-free and model-based RL methods is shown below.
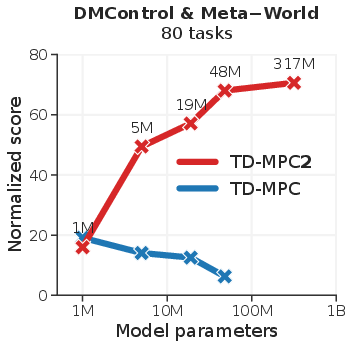
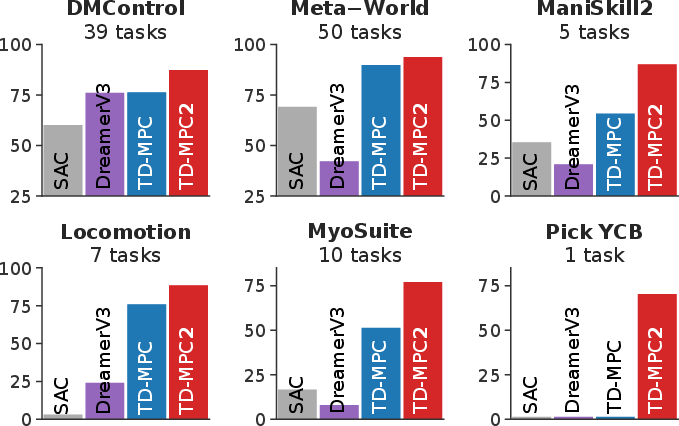
Figure 1: Overview demonstrating TD-MPC2's favorable performance across 104 continuous control tasks.
Architecture and Model Objectives
TD-MPC2 eschews explicit reconstruction, instead leveraging a learned implicit world model for local trajectory optimization. This solver-oriented architecture leverages the following components:
- Encoder and Latent Dynamics: These facilitate mapping of observations into a latent space and subsequent forward dynamics modeling.
- Reward and Terminal Value: These predict rewards and the discounted sum of future rewards.
- Policy Prior: Aids trajectory optimization, shaping actions to maximize the learned value function.
The model is trained on a loss function incorporating joint embedding prediction, reward prediction, and value prediction within a multitask framework.
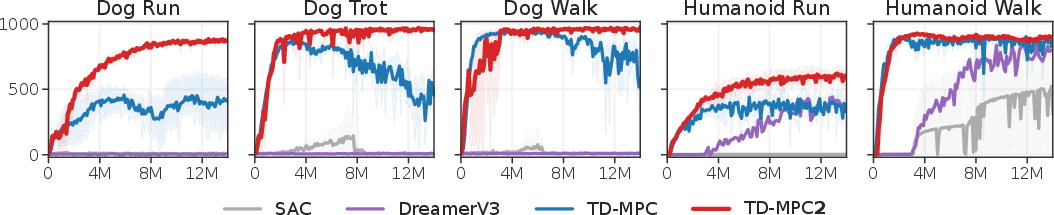
Figure 3: High-dimensional locomotion task results.
Multi-task Learning and Planning
TD-MPC2 supports multitask learning with a unified set of hyperparameters, employing a learned task embedding that simplifies the model's interaction with varied tasks. It uses Model Predictive Control (MPC) with a Policy Prior for closed-loop control, performing trajectory optimization with planning horizons (Figure 2).
Learning is achieved across categories such as DMControl, Meta-World, ManiSkill2, and MyoSuite with comprehensive scaling, ensuring that agent capabilities grow with increased model size and data availability.
Experimental Evaluation
The experiments are structured to address TD-MPC2's comparison to cutting-edge RL methods, scalability, and the contribution of its architectural modifications. The comprehensive results show that TD-MPC2 consistently outstrips performance metrics across all task domains (Figures 3 and 5).
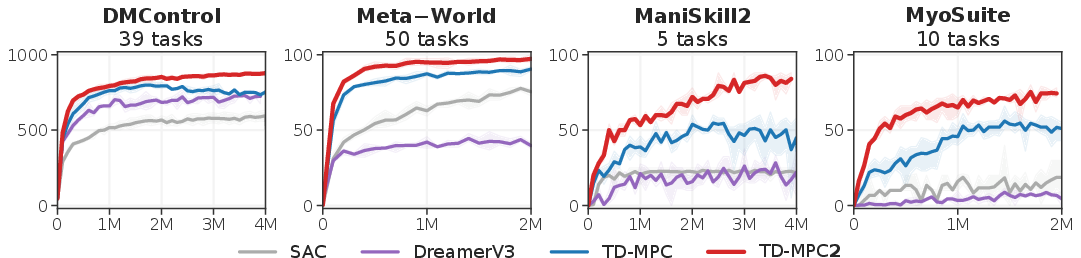
Figure 4: Single-task RL performance across 104 tasks.
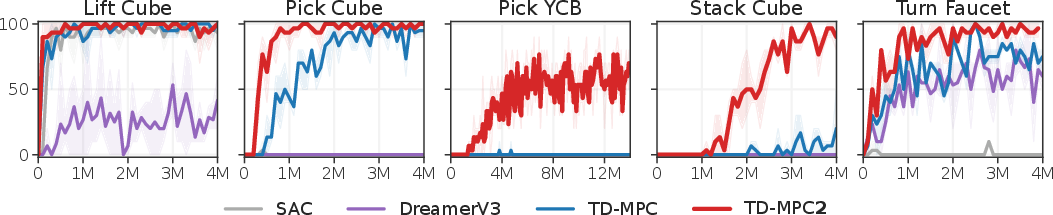
Figure 5: Object manipulation task results from ManiSkill2.
Ablations and Few-shot Learning
A comprehensive ablation study reveals critical insights into design decisions impacting the robustness and efficiency of TD-MPC2. Furthermore, the model demonstrates few-shot learning capabilities, rapidly adapting to new tasks through online RL finetuning, showing improvements in previously unseen tasks (Figures 15 and 16).
Discussion: Lessons, Opportunities, and Risks
The refined TD-MPC2 opens up significant opportunities for the deployment of generalist models capable of interfacing with diverse task domains. However, the model faces unique risks, like task reward specification issues and unanticipated behavior due to unconstrained autonomy. These elements necessitate further investigation to map the full potential of this technology, especially in providing lower entry barriers for complex RL tasks.
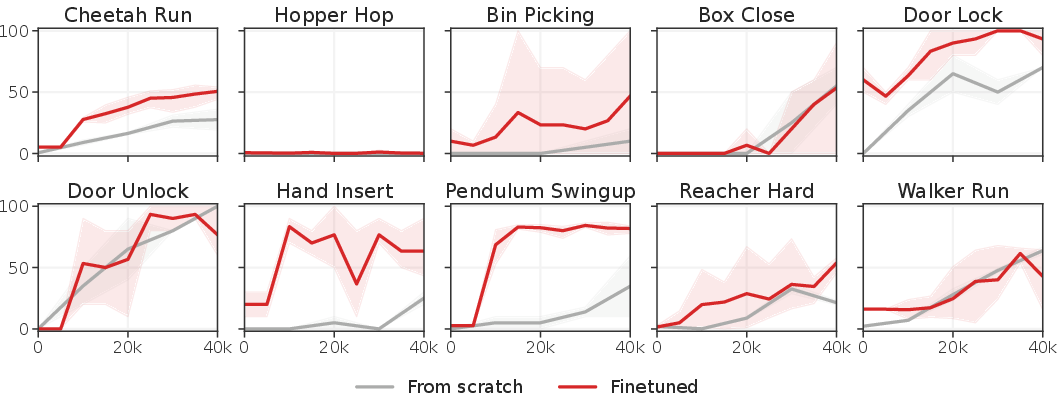
Figure 6: Few-shot learning efficacy through 19M parameter multi-task training.
Conclusion
TD-MPC2 provides substantial improvements over existing RL models for tasks with continuous control, leveraging scalability and robustness as cornerstones of its design. It promises significant potential in multitask domains, paving pathways for generalist model developments and presenting new challenges and opportunities in the field of reinforcement learning.