- The paper presents a taxonomy of black-box attacks by dissecting feedback granularity, query interactivity, and auxiliary data factors.
- The evaluation reveals that runtime-based attack success offers a more practical metric than fixed iterations across diverse threat models.
- Findings challenge existing state-of-the-art claims and guide improvements in realistic assessments of adversarial robustness.
Systematization of Knowledge: Evaluating Black-Box Attacks
The paper "SoK: Pitfalls in Evaluating Black-Box Attacks" presents an organized approach to understand the evaluation techniques associated with black-box attacks on image classifiers. The primary focus is to identify gaps and inconsistencies in the current research by proposing a new taxonomy based on threat models. This systematization aims to enhance the evaluation of these attacks with respect to adversarial knowledge assumptions. Below is a detailed essay on the paper's contributions and its implications.
Introduction
Black-box attacks are a crucial area of study, particularly because they pose realistic threats to deployed systems where the model's internal workings are inaccessible. In these settings, adversaries rely on interacting with the model via API queries without direct access to model parameters. This paper addresses the lack of comprehensive taxonomies in literature that consider the various assumptions about adversarial knowledge and the settings in which attacks are performed.
The paper proposes a taxonomy based on four dimensions:
- Feedback Granularity: Information provided by the model's API.
- Interactive Queries: Ability to query the target model interactively.
- Quality of Auxiliary Data: Relevance of data available to the adversary.
- Quantity of Auxiliary Data: Amount of data accessible for preparing the attack.
This multi-dimensional taxonomy aims to better understand attacks and allow for fair and insightful evaluations.
Taxonomy and Findings
Dimensions and Underexplored Areas
The paper differentiates threat models based on the interaction level and the quality of information returned by the model API. This reveals various under-explored areas, such as settings with top-k prediction scores, which reflect real-world applications where API usage is optimized for fewer data transmission overheads. The taxonomy identifies a substantial knowledge gap in attacking models that return top-k confidence scores, motivating further research and proposing preliminary experiments.
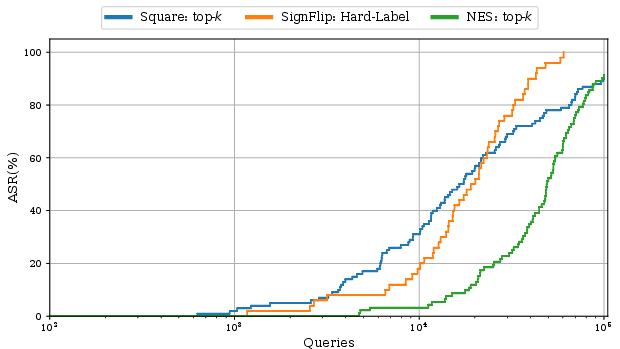
Figure 1: Comparison of top-k attacks with other attack settings.
Technical Challenges
By dissecting the assumed adversarial knowledge for each attack, stronger baselines emerged when comparing those under the same threat model. The paper demonstrates how even established claims of superiority can fall short when stronger baselines are considered, motivating future researchers to adapt existing strategies rather than developing new attacks. Such straightforward adaptations establish stronger baselines, challenging prior state-of-the-art claims.
Evaluation Pitfalls
Re-Evaluating Attack Costs
The metric of attack success has traditionally revolved around fixed iterations. However, the paper argues for runtime-based evaluation as certain attacks show greatly improved success rates beyond arbitrary iteration limits. By comparing attacks based on local computation costs, such insights reveal the practicality and efficiency of an attack from an adversary's perspective.
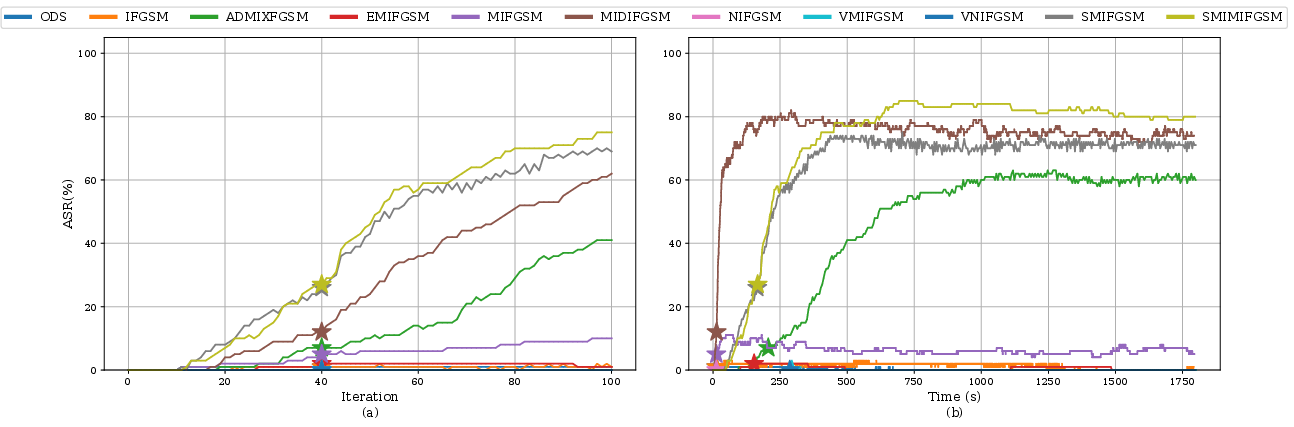
Figure 2: ASR comparison across local computation durations.
Attack Evaluation in Hard Settings
The paper underscores the importance of evaluating attacks in difficult settings, such as targeting adversarially robust models or using reduced perturbation budgets. These scenarios revealed different relative performances among attacks, offering insights unavailable in easier settings where differences between attacks are minimal.
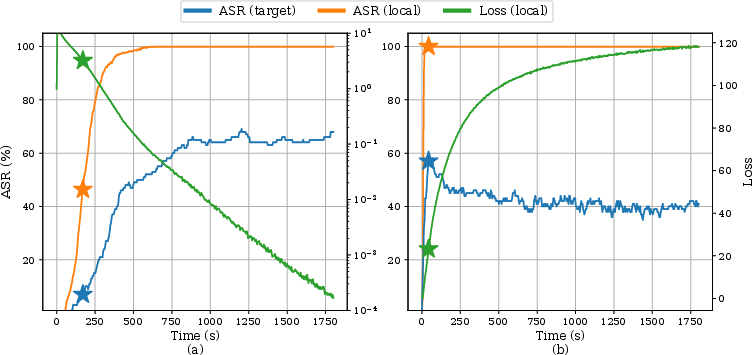
Figure 3: Attack success rates under reduced budgets and robust models.
Implications and Future Directions
Enhancing Evaluation Frameworks
Evaluations should account for the adversary's likely goals, focusing on time-constrained efficiency over iteration counts. Furthermore, systematic evaluations need to encompass diverse threat models and challenging settings to capture variances in attack performance.
Future work should consider leveraging techniques from model inversion and extraction to bolster black-box attacks. The paper suggests using these techniques in conjunction with black-box attacks to provide attackers with enhanced models and data representations.
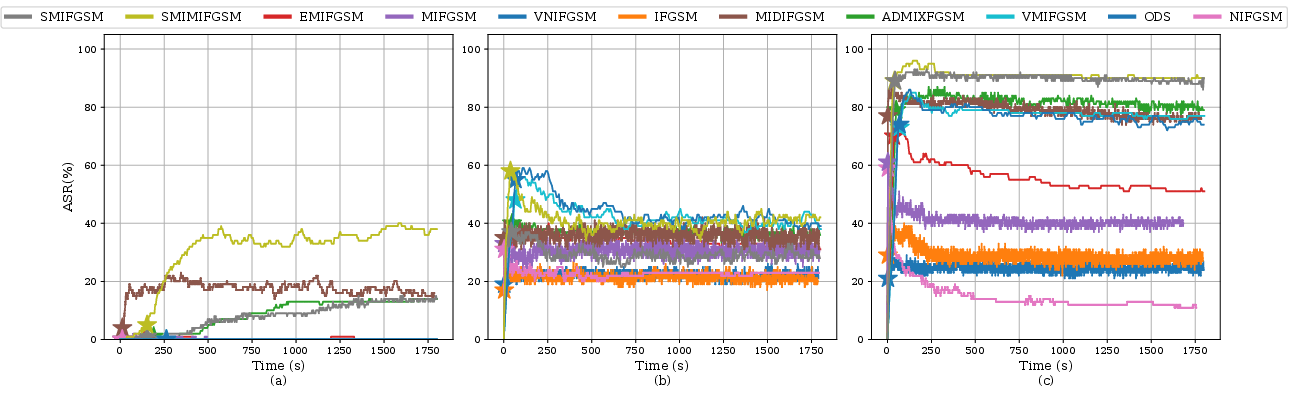
Figure 4: Potential interactions between black-box attacks and model inversion techniques.
Conclusion
The paper provides an essential framework for reshaping how black-box attacks are perceived and assessed within the research community. By identifying pitfalls and proposing structured evaluations grounded in threat models, the paper aims to guide future research toward more realistic and comprehensive evaluations. This approach can ultimately contribute to more robust defenses and improved understanding of potential adversaries' capabilities.