- The paper introduces a modular fusion approach that employs lightweight, scene-specific CBAM modules to integrate pretrained RGB and thermal detectors.
- It uses an EfficientDet architecture with EfficientNet backbones and BiFPNs, updating only CBAM parameters to reduce extensive retraining on large datasets.
- Experimental results on FLIR Aligned, M³FD, and STF datasets show improved mAP, demonstrating enhanced detection performance in challenging scenarios.
Scene-Specific Fusion for RGB-X Object Detection
This paper introduces a modular deep sensor fusion (DSF) approach for RGB-X object detection, leveraging scene-specific fusion modules to adapt to varying environmental conditions. The core idea is to utilize lightweight attention blocks to fuse pretrained single-modal networks, enabling the creation of joint input-adaptive architectures using small, coregistered multimodal datasets. This approach aims to address the limitations of existing DSF methods that often require extensive end-to-end training on large datasets and struggle to effectively utilize pretrained single-modal models.
Methodology
The proposed method employs a modular RGB-X fusion network built upon pretrained single-modal detection architectures, with multi-stage convolutional block attention modules (CBAM) for cross-modal feature fusion. The overall architecture, exemplified by RGB-T fusion, consists of individual EfficientDet detectors for each modality, each containing an EfficientNet backbone, a bidirectional feature pyramid network (BiFPN), and a detection head (Figure 1). CBAMs are used to fuse the RGB and thermal features output from the respective BiFPNs at various stages, resulting in five CBAM fusion modules. During training, only the CBAM parameters are updated, while the pretrained object detector weights are frozen. This modularity significantly reduces the need for large-scale multimodal training data. The authors train different CBAM fusion modules for various scenes by considering scene-specific dataset splits. During inference, an auxiliary scene classifier selects the most suitable set of fusion modules for the current setting.
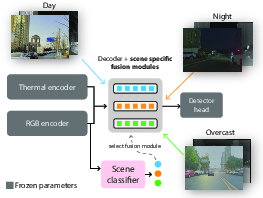
Figure 2: Our multimodal object detection approach combines RGB and thermal pretrained networks using lightweight, scene-specific fusion modules. Fusion modules are trained using categorized scene images and are used adaptively during inference with an auxiliary scene classifier.
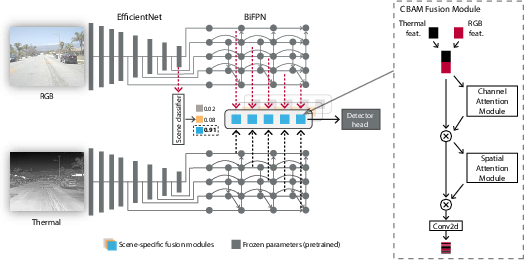
Figure 1: Overall framework of our scene-adaptive CBAM model for RGB-X fusion illustrated by RGB-T fusion. RGB and thermal images are processed by separate EfficientNet backbones, followed by BiFPNs. The features from BiFPNs are used for cross-modal feature fusion using modules selected by the scene classifier. The detector head utilizes these fused features to obtain the final detection results. The right side of the figure illustrates the CBAM fusion module, consisting of channel and spatial attention blocks, for feature fusion.
The CBAM fusion process involves concatenating RGB and thermal CNN feature maps, Frgb and Fx, respectively, to create an input feature map F for CBAM:
$\mathbf{F} = [\mathbf{F_{rgb}; \mathbf{F_{x}] \in \mathbf{R}^{B \times C \times H \times W}}$,
where B denotes the batch size, and C,H,W denote the channel and spatial dimensions of the feature, respectively. The CBAM module then masks the feature map F using channel and spatial attention operators, Mc and Ms, such that
F′=Mc(F)⊗F,
F′′=Ms(F′)⊗F′,
where ⊗ denotes element-wise multiplication. The channel attention operator Mc and the spatial attention Ms are computed using global average/max pooled features and convolution operations, respectively.
The auxiliary scene classifier consists of a 2D adaptive average pooling operator followed by a fully connected layer, taking in the features from the RGB object detector encoder and outputting probabilities of possible scene categories. During inference, the CBAM fusion modules trained on the scene with the highest probability are used.
Experimental Results
The authors validated the proposed method on three datasets: FLIR Aligned, M3FD, and Seeing Through Fog (STF). The results demonstrate the superiority of the scene-adaptive CBAM model compared to existing methods. For instance, on the M3FD dataset, the scene-adaptive CBAM model outperformed existing methods, achieving a 81.46% [email protected] on the full test set, a 1.4% improvement over EAEFNet and a 1% improvement over the scene-agnostic CBAM model. Qualitative results on the M3FD dataset show that the scene-adaptive model detects some occluded, blurred objects that the scene-agnostic model fails to detect. On the FLIR Aligned dataset, the scene-adaptive fusion model also outperformed the baselines by a large margin, achieving a 86.16% [email protected]. Similar trends were observed on the STF dataset, where the scene-adaptive model achieved comparable or better performance than existing methods. Ablation studies were conducted to explore the effects of different fusion modules and architectures. The authors found similar performance between DSF-NAS and CBAM-based fusion networks, but CBAM fusion models exhibited better performance on scene-specific data.



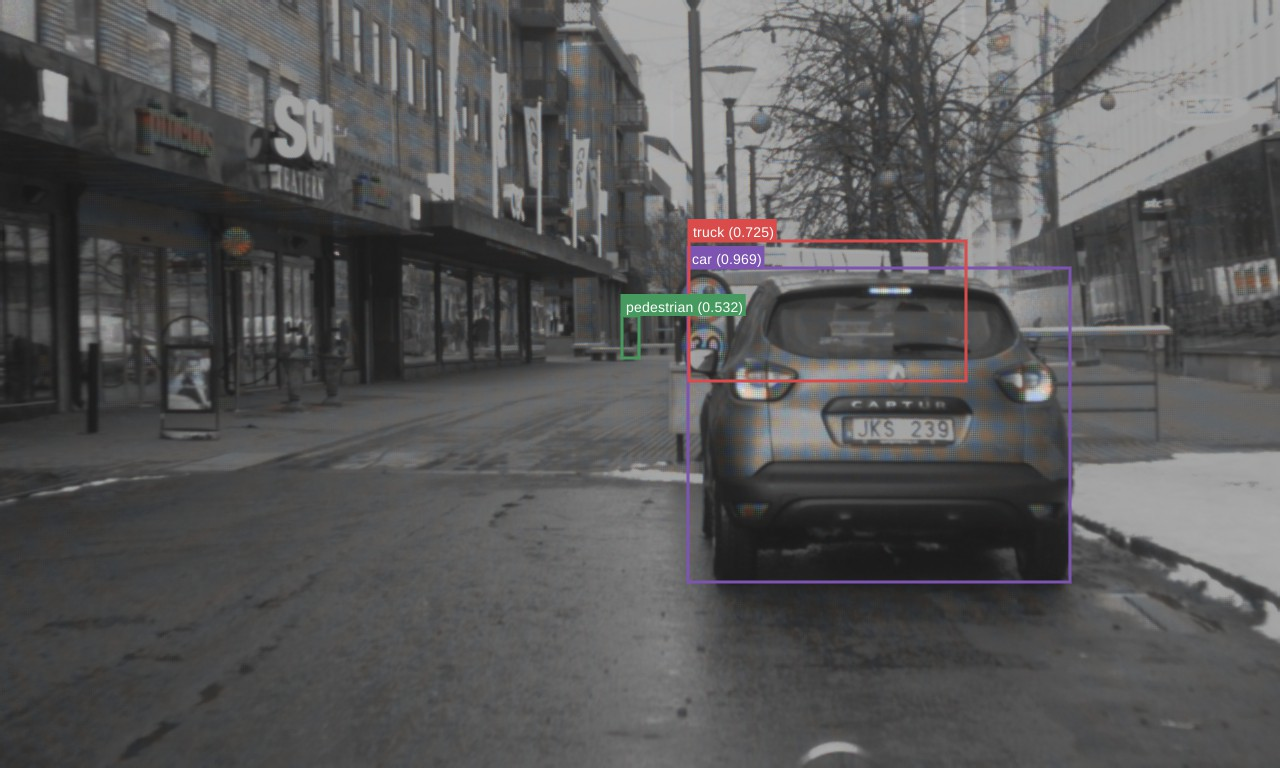
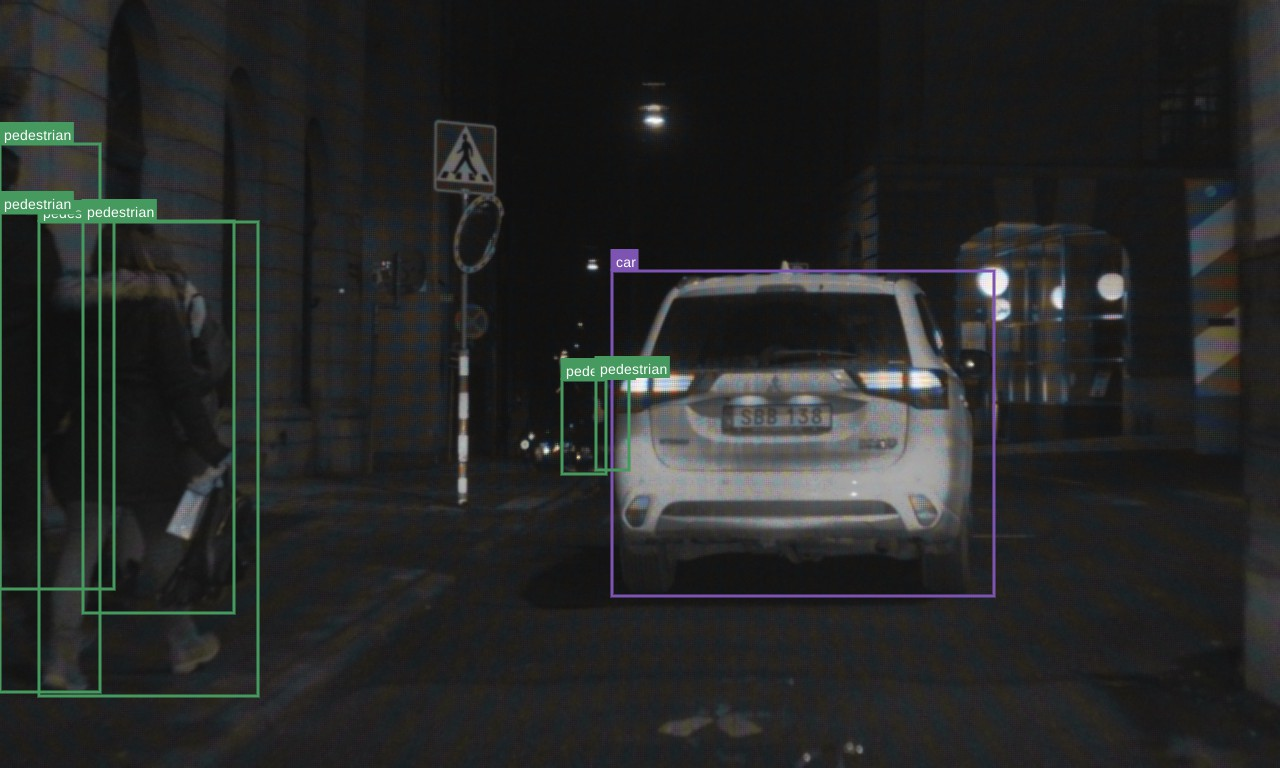

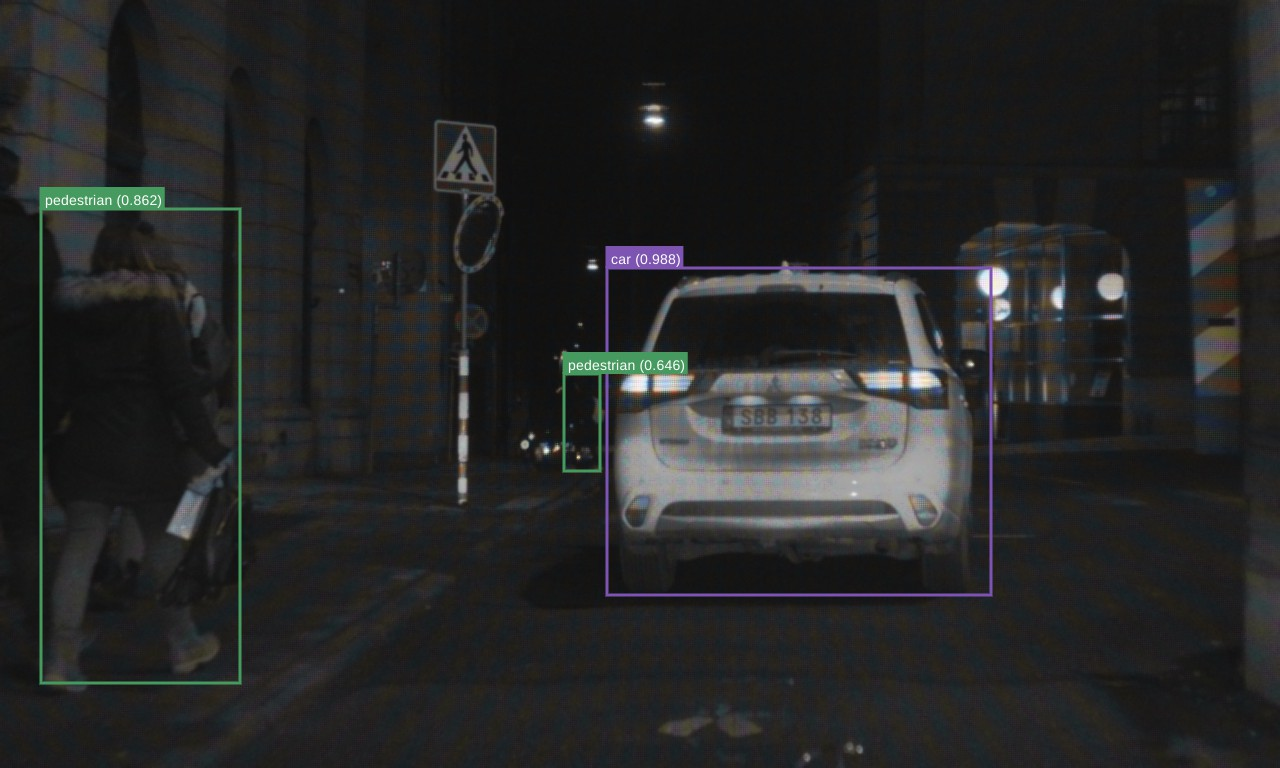

















Figure 3: Clear-Day









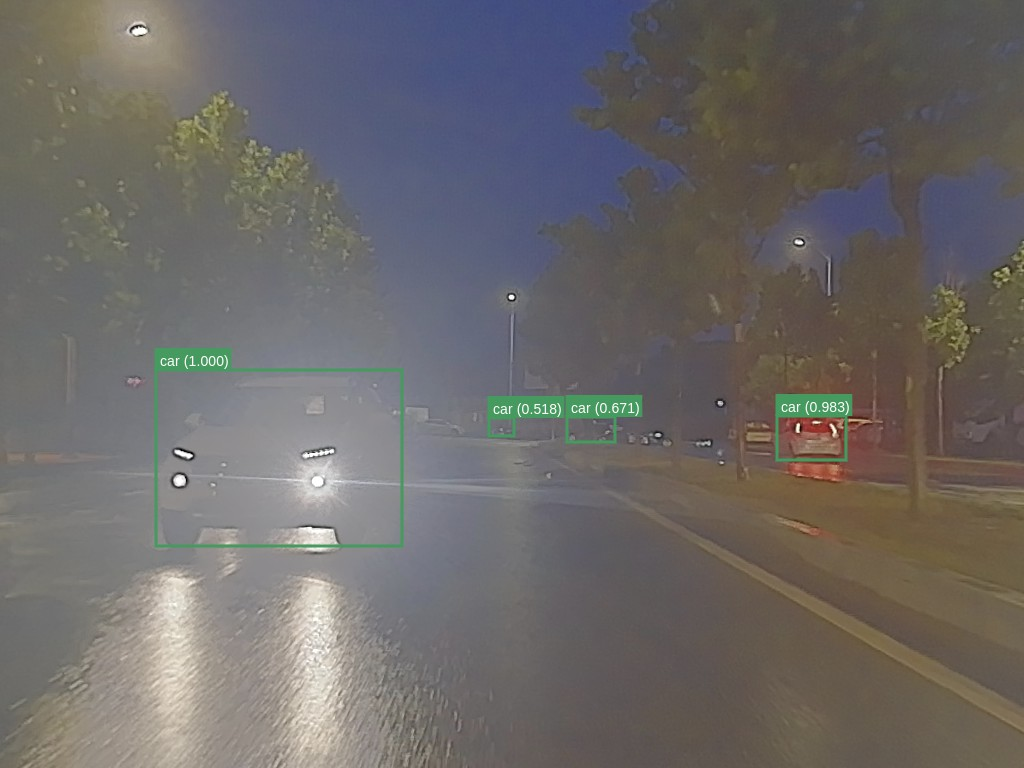


Figure 4: \scriptsize RGB-GT
Figure 5: \scriptsize M3FD-Day


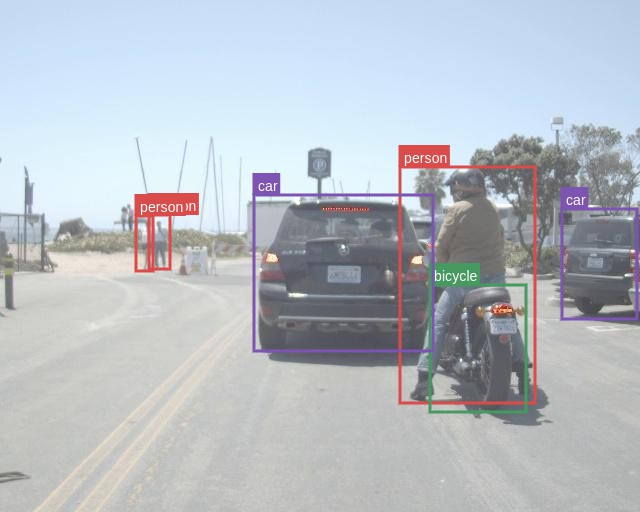




















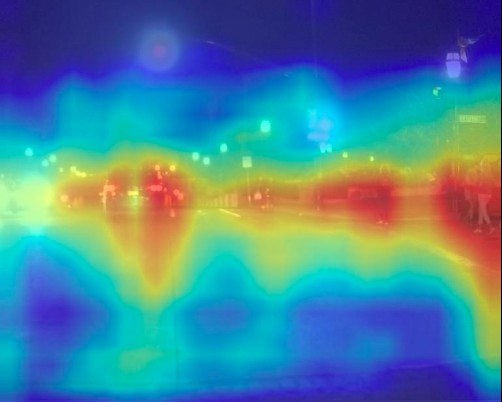

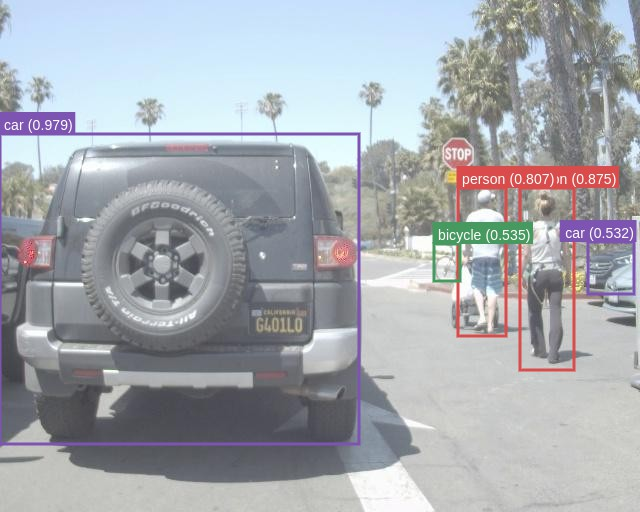
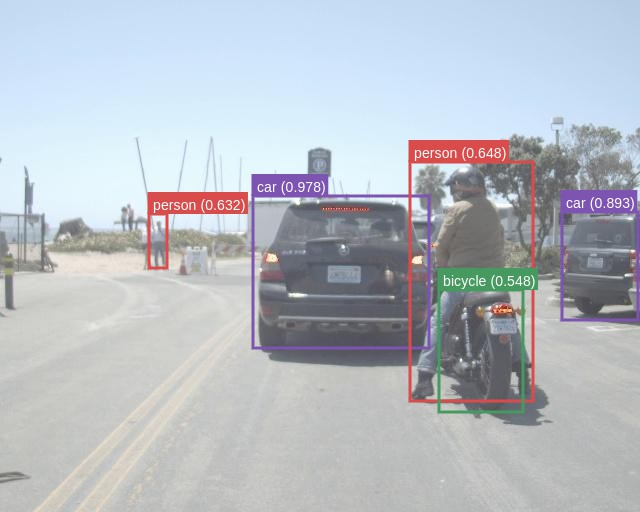









Figure 6: \footnotesize RGB with GT
Implications and Future Directions
The proposed RGB-X object detection model demonstrates a practical and efficient approach to improve autonomous vehicle perception in different weather and lighting conditions. The use of lightweight, scene-specific fusion modules facilitates a more modular design for deep sensor fusion, reducing the need for extensive retraining and enabling the effective utilization of pretrained single-modal models. The results suggest that adapting fusion strategies to specific environmental conditions can significantly improve object detection performance.
Future work could focus on incorporating unsupervised and online learning techniques to adapt to unexpected conditions and improve robustness in real-world scenarios. Training and leveraging larger pretrained models for both RGB and thermal modalities via multitask learning could also be explored. Addressing the limitations of requiring aligned RGB-X data and known scenes during training represents further avenues for research.
Conclusion
This paper presents a compelling approach to RGB-X object detection by leveraging scene-specific fusion modules. The results demonstrate the effectiveness and efficiency of the proposed method, offering a promising direction for advancing deep sensor fusion in autonomous driving and other applications.