- The paper introduces InstructCoder, a dataset with over 114,000 instruction triplets curated from GitHub commits to boost LLM code editing.
- It employs a multi-stage data generation method leveraging ChatGPT and manual refinement to create diverse, real-world code edit scenarios.
- The study shows that instruction-tuned models like Code LLaMA achieve 57.22% accuracy on the EditEval benchmark, rivaling advanced proprietary models.
InstructCoder: Instruction Tuning LLMs for Code Editing
Introduction
The paper "InstructCoder: Instruction Tuning LLMs for Code Editing" (2310.20329) introduces a novel approach to enhancing the code editing capabilities of LLMs. The focus of the research is on instruction-tuning LLMs using InstructCoder, a newly developed dataset designed to improve code editing tasks such as comment insertion, code optimization, and refactoring. This work addresses the under-explored area of automatic code editing, primarily due to the scarcity of relevant data.
Code editing involves modifying existing code in accordance with specified instructions, differing from code completion tasks where models generate code to complete given snippets. This paper proposes InstructCoder to bridge the gap by providing a dataset consisting of over 114,000 instruction-input-output triplets based on GitHub commit data strategically expanded through iterative generation using ChatGPT.
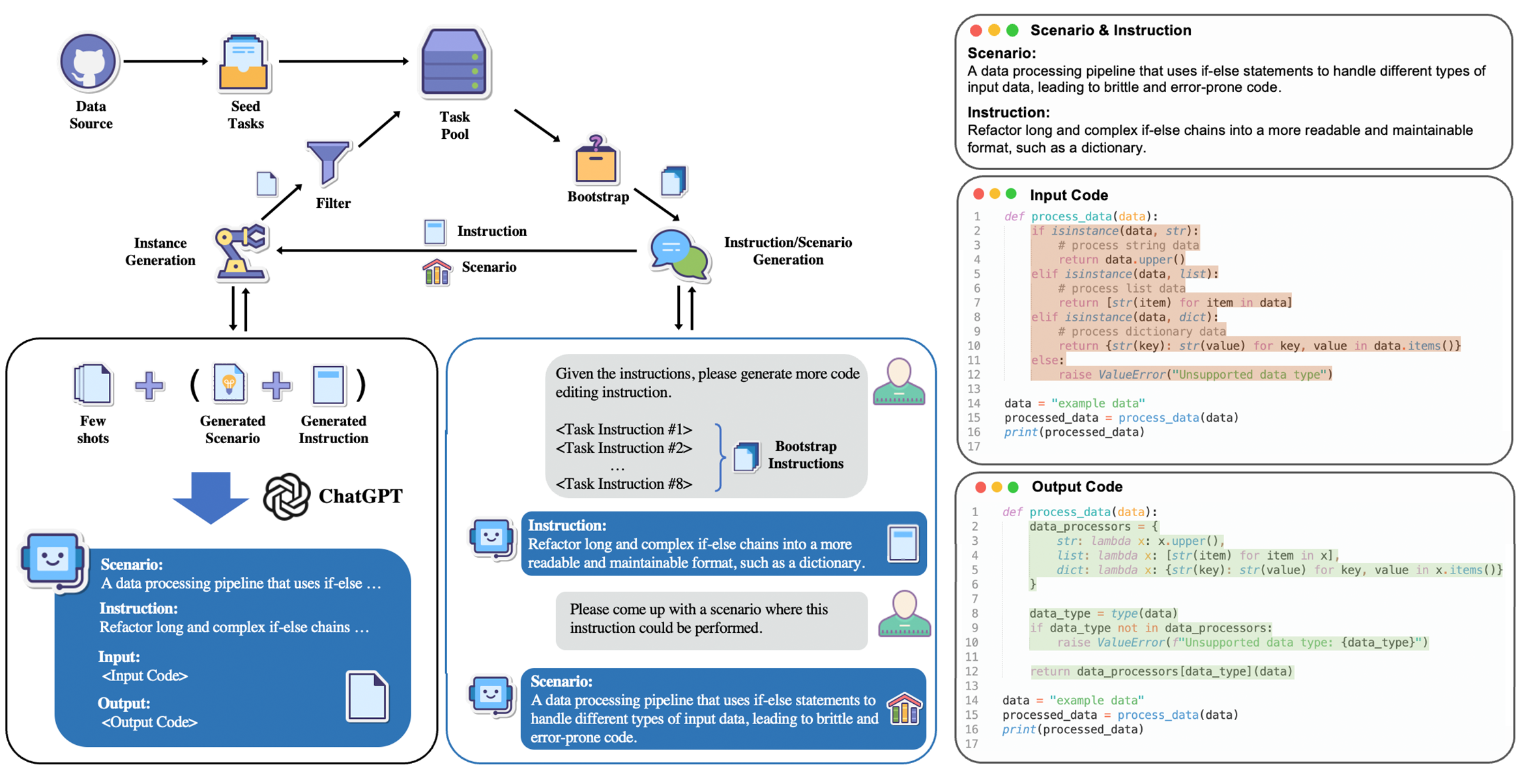
Figure 1: Data collection pipeline of InstructCoder and a qualitative example from the dataset.
Methodology
Data Collection and Generation
The InstructCoder dataset is meticulously curated through a multi-stage process beginning with filtering commit data from GitHub Python repositories as seed tasks. Subsequent expansion involves leveraging ChatGPT to generate new instructions and input-output pairs, drawing inspiration from frameworks like Self-Instruct and Alpaca. This iterative bootstrapping ensures the dataset encompasses diverse and practical code-editing scenarios relevant to real-world programming.
GitHub repositories serve as an initial source due to their naturally recorded code edits via commits. However, to ensure high quality and relevance, additional data undergoes manual scrutiny and clarification using Codex, improving instruction precision. The finalized dataset embodies a wide spectrum of code-editing tasks, and its iterative expansion showcases integration with both existing and newly generated tasks.
Evaluation Benchmark
To evaluate the proficiency of LLMs in code editing, the paper introduces EditEval, a human-written execution-based benchmark uniquely designed for assessing general-purpose code editing. EditEval provides a robust platform for evaluating model performance on real-world-inspired code-editing tasks, highlighting the challenges models face in following instructions and understanding code context.
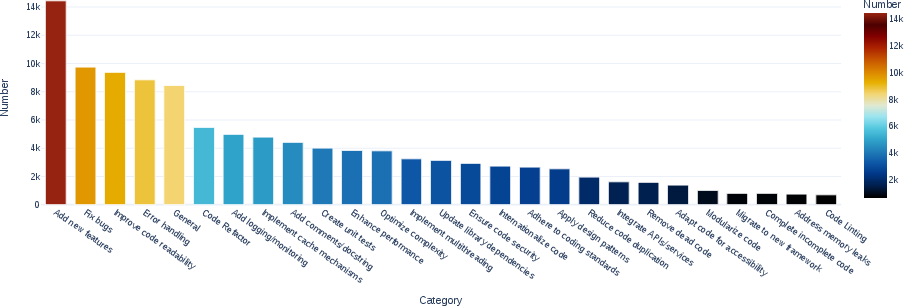
Figure 2: Distribution of code edit intent categories.
Results
The study reveals substantial improvements in code editing performance for open-source LLMs fine-tuned on InstructCoder, equating to levels seen in advanced proprietary models. Code LLaMA models exhibit particularly high accuracy rates, achieving 57.22% closely matching ChatGPT's performance. Theoretical insights into pre-training reaffirm that foundational model attributes such as pre-training on code data and instruction-tuning significantly influence model efficacy.
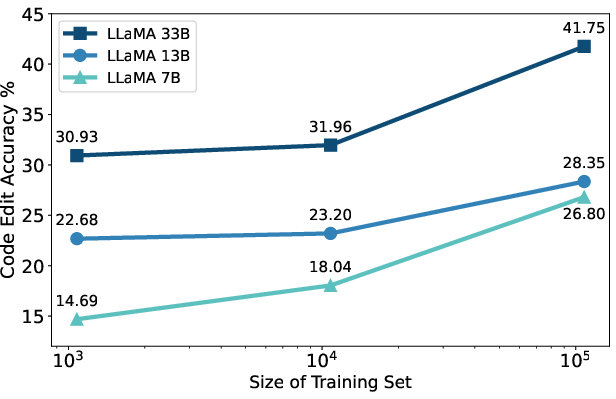
Figure 3: Data scaling performance of InstructCoder on LLaMA evaluated on EditEval.
Dataset Analysis
InstructCoder stands out with its structure and diversity. Analyzing instruction diversity, the dataset encompasses various editing intents and verbs, demonstrated through figures showing the distribution and prevalence of different editing actions. Furthermore, introducing scenario-conditional generation ensures variability in the generated samples, facilitating diverse codebases and variable naming conventions.
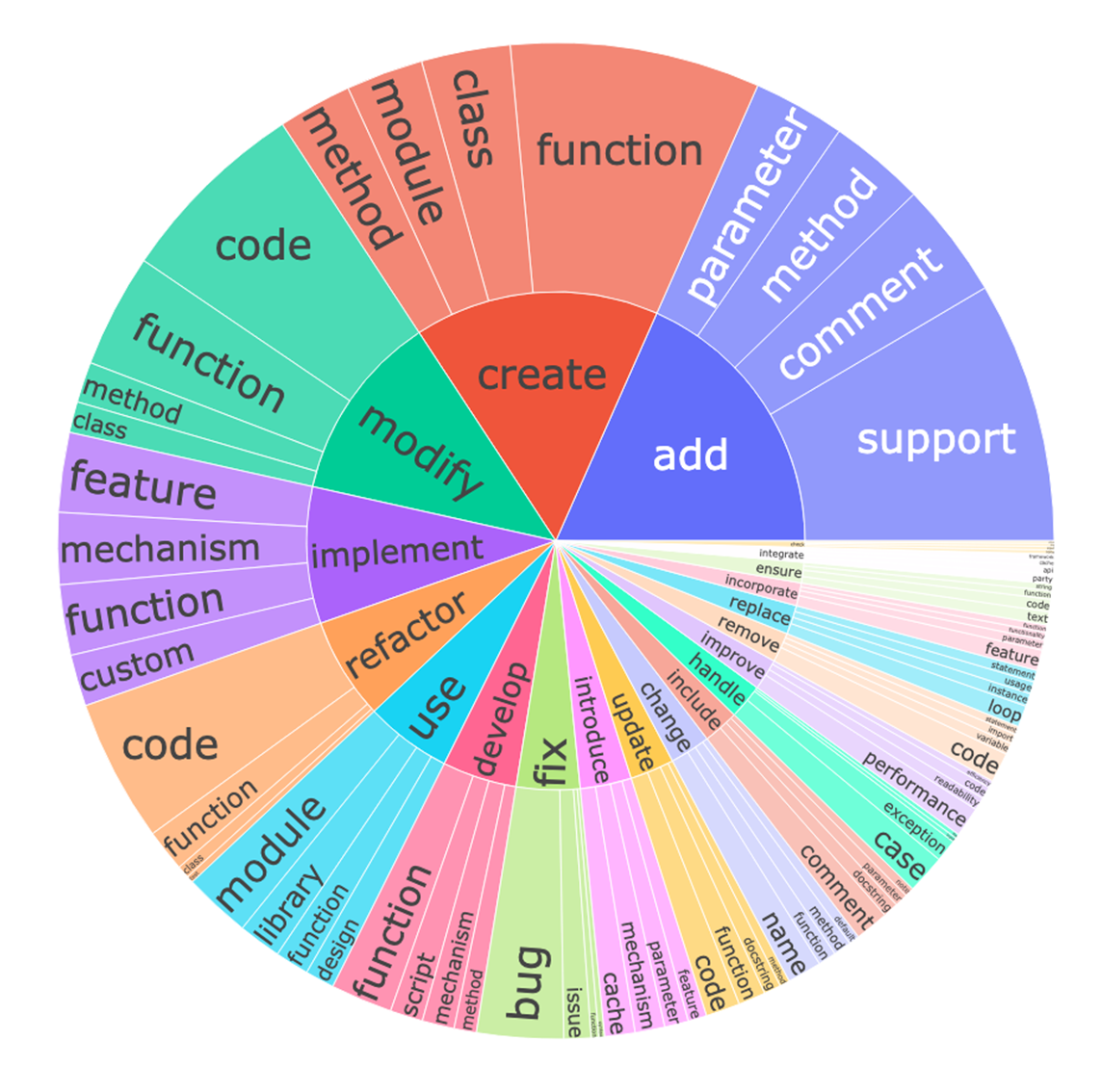

Figure 4: The top 20 most common root verbs with each top 4 noun objects in the instructions.
Implications and Future Work
This paper paves the way for future research into automatic code editing by establishing a robust dataset and benchmark. With LLMs being instruction-tuned for practical code editing, the implications posit potential enhancements in developer productivity by automating monotonous tasks. Theoretical implications suggest a pressing need for continued exploration into dataset scalability, foundational model alignment, and refining instruction accuracy.
Further developments could focus on expanding the dataset's linguistic and contextual reach, possibly incorporating additional programming languages and exploring code edits within multi-file contexts or large-scale systems.
Conclusion
InstructCoder represents a significant step forward in instruction-tuning datasets for LLMs, specifically targeting code editing capabilities. The comprehensive evaluation methods and empirical evidence from the EditEval benchmark illustrate the transformative potential of instruction-tuning. This work highlights key areas where LLMs excel and provides foundational insights into advancing automated programming tools, fostering a nuanced understanding of model training dynamics related to code-focused tasks. Future research will undoubtedly delve deeper, building upon these findings to refine LLM capabilities further.