- The paper surveys how different transformer architectures express formal languages, mapping their capabilities to established computational complexity classes.
- It details the contrast between encoder-only, decoder-only, and encoder-decoder models, highlighting how each is tailored for tasks from basic counting to Turing-completeness.
- The study identifies that specific attention mechanisms constrain expressivity, with hard attention limiting transformers to AC^0 and softmax mechanisms broadening this to TC^0.
Transformers have revolutionized the field of NLP by providing versatile architectures capable of handling various tasks such as machine translation and language modeling with pretrained models like BERT and GPT. Researchers have turned to the theoretical underpinnings of transformers to discern their formal capabilities, particularly focusing on expressivity—how transformers can be treated as recognizers or generators of formal languages, and what their innate computational power may be.
Transformers comprise several components: the input layer, layers for hidden processing, and the output layer. These elements are meticulously defined with the help of positional and word embeddings, which map sequences into vectors, and various forms of attention mechanisms that dictate how these sequences interact internally. The paper places significant emphasis on defining different transformer variants, distinguishing between encoder-only, decoder-only, and encoder-decoder architectures. Importantly, the use of position embeddings and the attention mechanism—whether standard, argmax, or average-argmax—specifies the extent of computational prowess achieved by a transformer.
Theoretical Characterization of Expressivity
Numerous formal LLMs serve as benchmarks against which the expressivity of transformers is measured. Transformers have been intricately linked with models such as automata, Turing machines, and various classes like . Roughly, these model complexities span from merely recognizing finite languages to addressing more intricate languages within the Chomsky hierarchy.
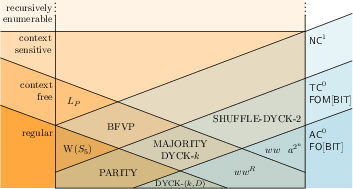
Figure 1: Relationship of some languages and language classes discussed in this paper (right) to the Chomsky hierarchy (left), assuming that TC0⊊NC1 and ⊊NL.
Lower Bounds and Capabilities
Transformers exhibit varied expressivity, contingent on the architectural choice and configuration:
- Simple Languages in Majority and Dyck: Basic configurations of transformers, even without extensive intermediate steps or particular precision constraints, can handle simple counting problems and balanced language constructs like Dyck sequences.
- Recursively Enumerable Languages: With theoretical augmentations such as specific position embeddings and unbounded computation steps, transformers have been symbolically proven to recognize recursively enumerable languages—akin to the general expressivity of Turing machines.
Upper Bounds and Limitations
Despite these capabilities, certain attention mechanisms like hard attention inherently restrict transformers' capabilities:
- AC0 Limitations: Hard attention transformers can only process languages within low circuit complexity classes such as AC0.
- TC0 Bounds: Softmax and average-hard attention widen this scope upwards to TC0, including counting operations but still fail to breach the computational barriers posed by problems such as arbitrary Boolean formula evaluation or permutation group word problems.
Conclusions and Future Directions
The research delineates a succinct framework defining the polarized expressive capabilities of transformers, with emerging observations signifying that encoder-decoder variants with unbounded steps approach universal Turing computability. Ongoing work aims to further scrutinize configurational subtleties that influence expressivity, including the role of embeddings and numeric precision. In isolating additional constraints, the theoretical foundation presented invites new inquiries into efficiently leveraging transformers for tasks historically deemed computationally intensive.
In closing, future exploration is warranted into embedding configurational intricacies and their practical implications for real-time learning applications, further bridging the gap between theoretical models and practical deployment scenarios in intelligent NLP systems.