- The paper introduces S-LoRA, a system that efficiently serves thousands of LoRA adapters by separating base and adapter computations using batched GEMM and custom CUDA kernels.
- The approach employs a unified memory pool to manage KV caches and dynamic adapter weights, significantly reducing memory fragmentation.
- S-LoRA achieves up to 30× improvement in throughput over existing methods, demonstrating effective scalability for fine-tuned large language models.
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Introduction
The recent advancements in LLMs have necessitated new methodologies for efficiently fine-tuning and serving these models across multiple tasks. Using the "pretrain-then-finetune" paradigm, Low-Rank Adaptation (LoRA) has emerged as a prominent method for parameter-efficient fine-tuning. LoRA allows adaptation to a multitude of tasks by creating various adapters from a base model. The study presented in the paper "S-LoRA: Serving Thousands of Concurrent LoRA Adapters" proposes a system named S-LoRA, designed for scalable serving of LoRA adapters, addressing the challenges associated with memory management and computational overhead.
System Architecture
S-LoRA aims to efficiently serve thousands of LoRA adapters with minimal overhead. A central concept in S-LoRA is separating the computation of the base model and LoRA adapters, allowing for batched inference.
Batched Computation
S-LoRA implements the base model computation using General Matrix Multiply (GEMM), while LoRA adapter computations are handled by custom CUDA kernels (Figure 1).
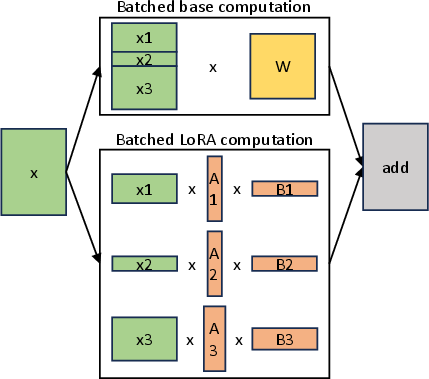
Figure 1: Separated batched computation for the base model and LoRA computation. The batched computation of the base model is implemented by GEMM. For LoRA adapters, it is handled by custom CUDA kernels supporting batching of various sequence lengths and adapter ranks.
By decomposing the computation, S-LoRA avoids the inefficiencies of merging adapter weights into the base model and enhances batching possibilities.
Memory Management
Efficient memory utilization is a critical aspect of serving multiple LoRA adapters. S-LoRA addresses this through a novel memory management system.
Unified Memory Pool
The system employs a unified memory pool to manage both KV caches and dynamic adapter weights, storing them in a non-contiguous manner (Figure 2).
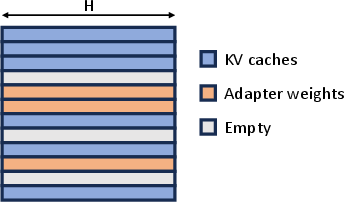
Figure 2: Unified memory pool storing KV caches and adapter weights to minimize memory fragmentation. The memory pool uses pages of size H.
This unified approach reduces memory fragmentation and alleviates the challenges faced with dynamically loading and offloading adapters of varying sizes.
Computational Optimization
The integration of tensor parallelism is another key feature that enhances S-LoRA's capability to serve multiple GPUs efficiently.
Tensor Parallelism Strategy
S-LoRA introduces a novel tensor parallelism strategy that minimizes communication costs by aligning the partition strategies of LoRA and base model computations (Figure 3).
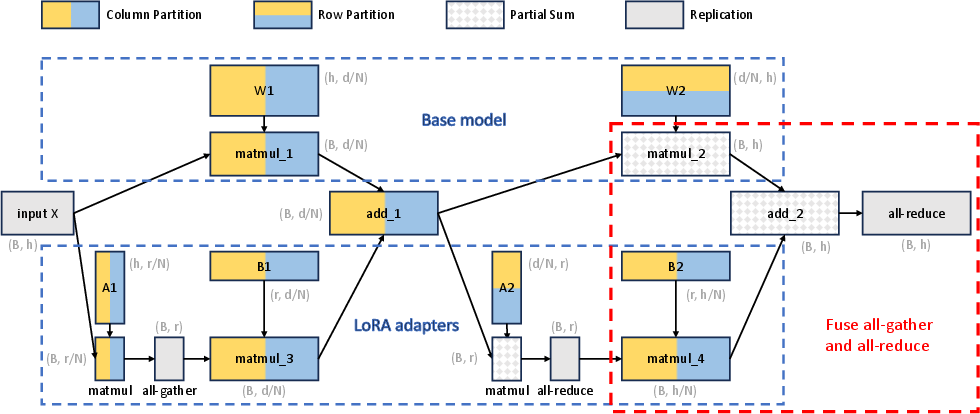
Figure 3: Tensor parallelism partition strategy for batched LoRA computation. Nodes represent tensors/operators, edges show dependencies, and different colors denote partition strategies.
The strategy partitions both inputs and outputs of LoRA computations in a way that reduces the additional overhead typically associated with such parallel processes.
Comparisons indicate that S-LoRA significantly increases throughput and can support a much larger number of adapters compared to existing libraries such as HuggingFace PEFT and vLLM. These improvements are largely due to the efficient memory management and computational optimizations that allow S-LoRA to serve thousands of adapters with minimal overhead, demonstrating up to 30× improvement in throughput over HuggingFace PEFT and better scalability.
Conclusion
S-LoRA represents a significant step in the scalable serving of parameter-efficient fine-tuned models, facilitating the deployment of extensive, task-specific customized services. The innovations in memory management and computation pave the way for further research in scalable AI systems, potentially incorporating other adapter methods and fine-tuning strategies to meet diverse application requirements.