- The paper introduces the LINK framework using symbolic rules and beam search to systematically generate long-tail inferential knowledge.
- It demonstrates a 5% higher factual correctness rate compared to zero-shot GPT4 and produces the substantial LINT dataset with 108K knowledge statements.
- The study offers actionable insights for enhancing model robustness, improving data augmentation strategies, and mitigating evaluation bias in LLM performance.
Systematic Generation of Long-Tail Inferential Knowledge
Introduction
The paper "In Search of the Long-Tail: Systematic Generation of Long-Tail Inferential Knowledge via Logical Rule Guided Search" (2311.07237) introduces a structured approach for creating inferential knowledge in areas that elude conventional LLMs. By focusing on long-tail distributions, it addresses the observed degradation in LLM performance when dealing with low-probability data inputs, which are less likely to be encountered with traditional data generation methods.
LINK Framework
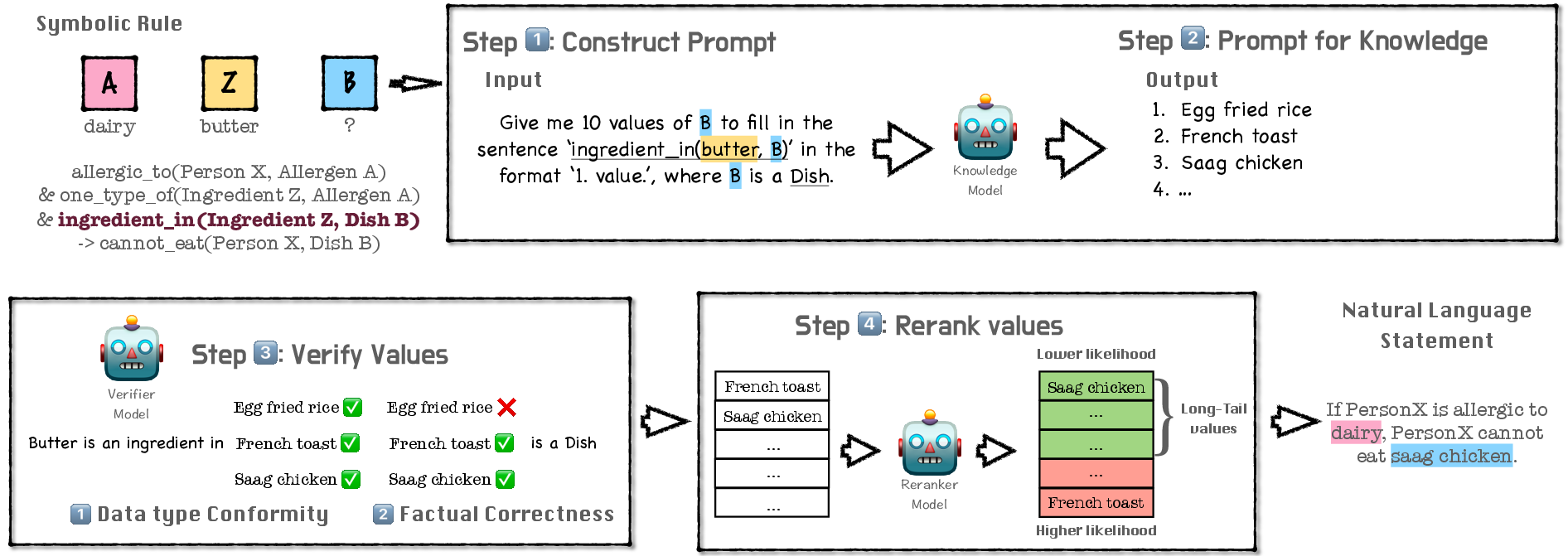
The Logic-Induced-Knowledge-Search (LINK) framework is central to the proposed methodology. It operates by using symbolic rule templates to guide the generation of inferential knowledge statements that reside within the long-tail of natural language distributions. This is achieved through a composition of symbolic rule grounding, value search, and knowledge beam search.
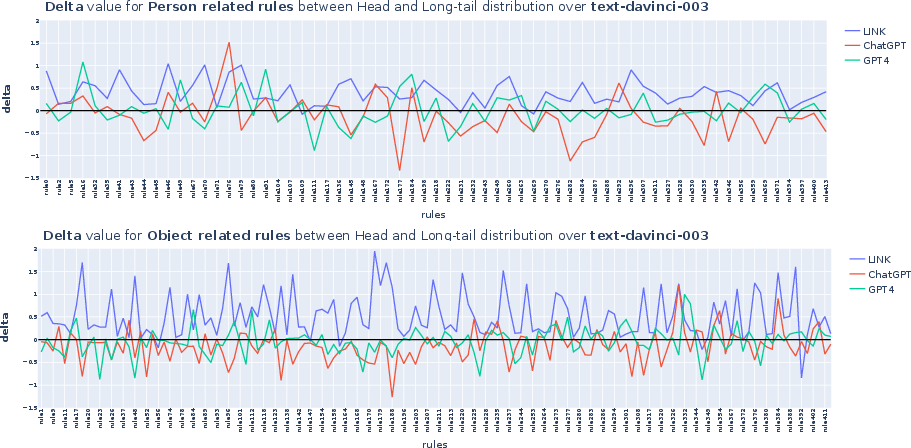
The LINK framework was compared against zero-shot LLMs like ChatGPT and GPT4. It demonstrated superior capabilities in generating long-tail knowledge with a 5% higher factual correctness rate compared to zero-shot GPT4. The data curated through LINK was deployed in creating a substantial dataset called Logic-Induced-Long-Tail (LINT), intended to rigorously evaluate LLM reasoning capabilities in areas dominated by long-tail distributions.
Dataset Construction and Evaluation
LINT, the resultant dataset, comprises 108K knowledge statements across different domains (temporal, locational, natural properties, and capability & advice). This dataset not only serves as a challenging evaluation suite for LLMs but also highlights the performance disparity between humans and models, especially in reasoning tasks formulated with long-tail data.
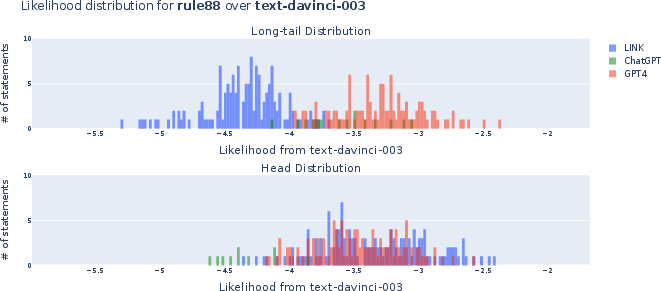
Figure 3: Distribution of LINK-generated statements on the log-likelihood scale of InstructGPT, contrasting post-hoc reranking and naturally generated long-tail statements.
Implications and Future Directions
The exploration into long-tail knowledge through the LINK framework opens several avenues for further research and practical applications:
- Enhancing Model Robustness: By focusing on less-probable data distributions, the research calls for model training approaches that prioritize these distributions to enhance LLM resilience and performance consistency across varied contexts.
- Informing Data Augmentation Strategies: LINK provides a systematic method for generating challenging data scenarios, instrumental in data augmentation strategies aimed at improving model generalization across rare events or conditions.
- Mitigation of Evaluation Bias: The LINT dataset exemplifies the importance of diversifying the model evaluation process to include scenarios that better approximate the complexities of real-world language use.
Conclusion
"In Search of the Long-Tail" presents a compelling case for the systemic generation of long-tail inferential knowledge. By harnessing logical rules and structured search strategies, it offers a transformative perspective on data generation and model evaluation, pushing the boundary of how LLMs are assessed and improved upon in tackling low-probability scenarios effectively.