- The paper demonstrates that users systematically refine prompts based on image feedback, converging towards language patterns favored by the model.
- Methodologically, the study leverages a large-scale dataset of over 169K prompts segmented into 107K threads, using features like prompt length, magic word ratio, and perplexity.
- Findings reveal that iterative prompt evolution occurs through adding omitted details and adopting model-like language, raising important implications for RLHF and model alignment.
Human Learning by Model Feedback: Iterative Prompting Dynamics with Midjourney
Introduction and Motivation
This work presents a comprehensive quantitative analysis of human iterative prompt adaptation with the Midjourney text-to-image model. The authors construct a large-scale dataset from the Midjourney Discord server, comprising 107,051 interaction threads composed of user-generated prompts and corresponding images. The central question is whether and how users systematically refine prompts based on image feedback, what linguistic features are affected throughout the iterative process, and whether observable convergence results from users learning missing details or adaptation to the model’s inherent preferences.
The thread-level perspective differentiates this work from prior prompt engineering and session-based studies, focusing on prompt dynamics for generating a single scene rather than general conversational shifts. This design enables precise measurement of linguistic adaptation specific to task completion in generative modeling contexts.
Dataset Acquisition and Thread Segmentation
Midjourney was selected due to its advanced text-to-image capabilities and granular prompt/image metadata. Scraping was performed from a public Discord channel, collecting 693,528 prompts and corresponding images, subsequently filtered for English language and cleaned for irrelevant parameter inputs and missing images, yielding 169,620 prompts from 30,394 users.
Prompts were segmented into threads representing coherent attempts to generate a particular image concept. Segmentation employed both Intersection-over-Union and BERTScore-based approaches, with high inter-annotator agreement (Fleiss’ κ = 0.815). The final dataset includes 107,051 threads, with an average thread length of 1.58 prompts. Upscaling requests are interpreted as markers of user satisfaction.
Feature Analysis and Classification
To characterize prompt evolution, the study defines a suite of linguistic features:
- Prompt length (word count)
- Magic word ratio: prevalence of commonly used but semantically weak prompt modifiers (e.g., "8K", "cute", "highly detailed")
- Perplexity: estimated via GPT-2, capturing syntactic and lexical predictability
- Concreteness score
- Repeated word ratio
- Sentence rate: words per sentence
- Syntactic tree depth
Prompt and image features were statistically compared for upscaled versus non-upscaled samples, revealing significant distinctions except for concreteness. Mann–Whitney U tests yield extremely low p-values for all significant features, providing strong evidence of systematic feature divergence (e.g., upscaled prompts are longer on average: 16.67 vs. 14.78 words, p<10−231).
Text (GPT-2) and image (ResNet-18) classifiers predict upscaling from prompts and images at 58% and 56% accuracy (vs. 50% random), supporting the existence of linguistic and visual cues for user satisfaction.
Prompt Dynamics in Interaction Threads
A core contribution is the temporal analysis of feature adaptation across prompt sequence index within a thread. The study focuses on threads with ≥10 prompts, plotting feature trends as a function of iteration.

Figure 1: Threads examples illustrating the evolution and adaptation of prompt wording and specificity across interactions.
Numerical analysis demonstrates monotonic increases in prompt length, magic word ratio, repeated words ratio, sentence rate, and syntactic tree depth. Conversely, perplexity exhibits a clear declining trend, indicating increased alignment with distributional expectations.
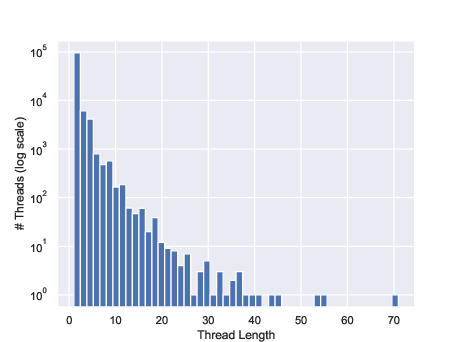
Figure 2: Histogram highlighting the skewed distribution of thread lengths; only 0.6% of threads contain 10 or more prompts.
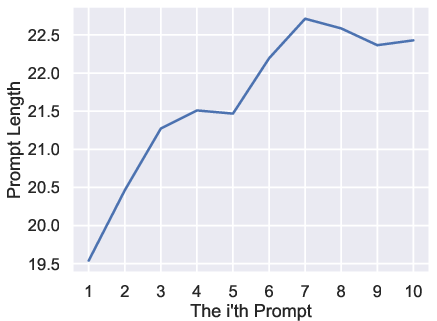
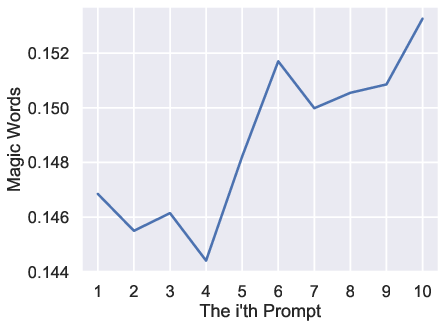
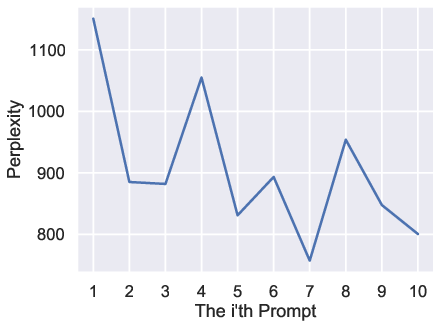
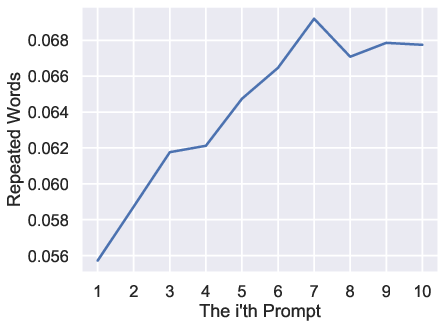
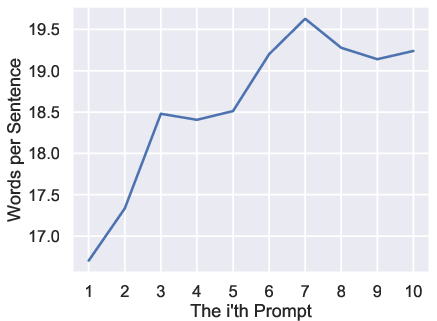
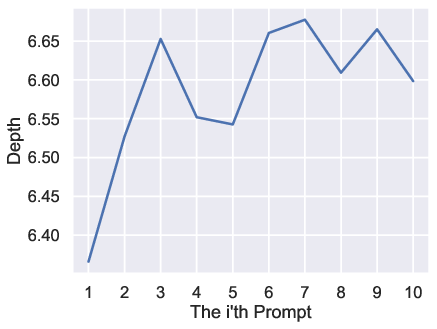
Figure 3: Average prompt length as a function of prompt index, confirming monotonic increase over iterative interactions.
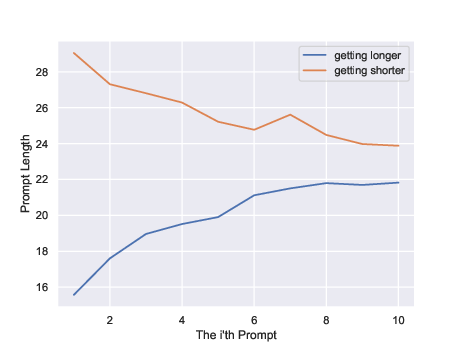
Figure 4: Threads with increasing prompt length start shorter, those decreasing begin longer; both converge to a similar final range.
These results indicate that users do not merely sample random prompt variants but engage in a systematic convergence process steered by feedback.
Driving Forces and Interpretative Hypotheses
Two primary mechanisms are posited:
- Adding Omitted Details: Users realize missing information in initial prompts and incrementally enhance specificity, reflected by increases in prompt length, complexity, and sentence structure.
- Adopting Model-Like Language: Users align their prompting style with model preferences, indicated by increased magic word usage, lower perplexity, and higher repeated word ratios. These adaptations do not necessarily correspond to natural human expression but rather optimize for better model output.
Both mechanisms are substantiated by feature trajectories; their interplay is further evidenced by thread convergence analyses. Independent of starting prompt feature values, threads converge towards an empirically optimal range.
Implications for RLHF and Model Alignment
Findings regarding user adaptation have direct implications for data curation in RLHF pipelines. Prompts favored by the model (via feedback) risk being over-represented in future training, amplifying non-human-like linguistic priors and potentially distorting further model evolution away from true human intent. Thus, prudent selection and control of interactive human-model data are required to maintain alignment robustness.
Comparative Analysis and Generalizability
Experiments replicated with the Stable Diffusion-based DiffusionDB dataset affirm that feature-based thread dynamics generalize beyond Midjourney, albeit with minor variation in magic word ratio monotonicity. Consequently, the convergence phenomenon and adaptation strategies are likely inherent in user-model feedback loops in text-to-image systems.
Limitations
Variance explained by analyzed features is limited, given heterogeneity in user expertise and intent, and the short length of most threads. High sample variance, especially in longer iterations, can affect the robustness of numerical characterizations. Future work targeting more controlled prompt content and broader user cohorts may clarify these effects.
Conclusion
This study establishes that humans systematically modify text-to-image model prompts in iterative interactions, converging across multiple linguistic dimensions towards distributions favored both by descriptive specificity and model linguistic preferences. These dynamics, inherent in the prompt feedback loop, raise critical questions about RLHF data usage, model alignment fidelity, and the evolution of prompt engineering practices. Prospective work should examine how to disentangle model-optimized prompting from natural human language and refine data curation strategies to mitigate emergent bias and misalignment in future generative modeling systems.