SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors
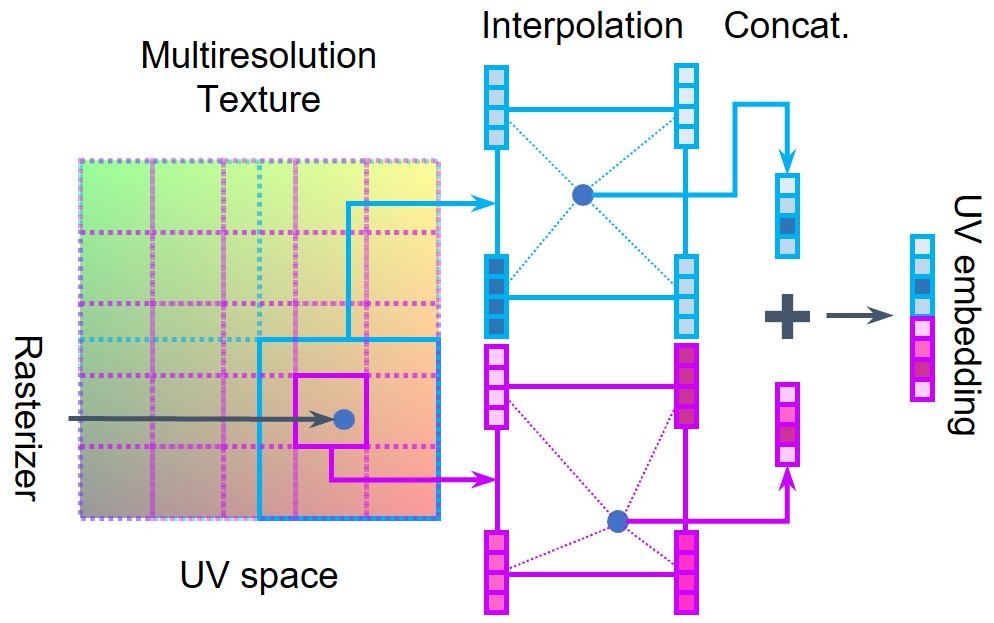
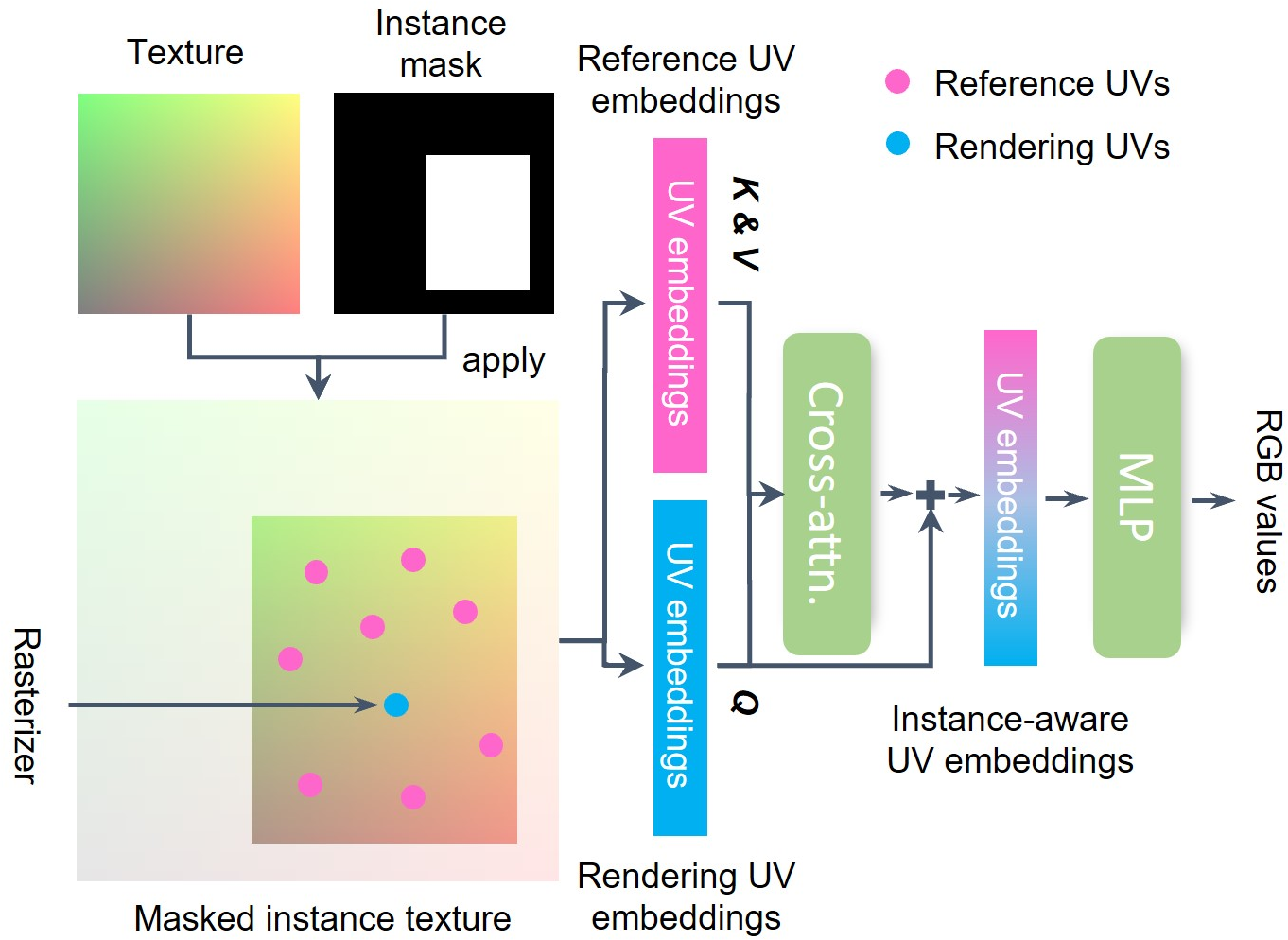
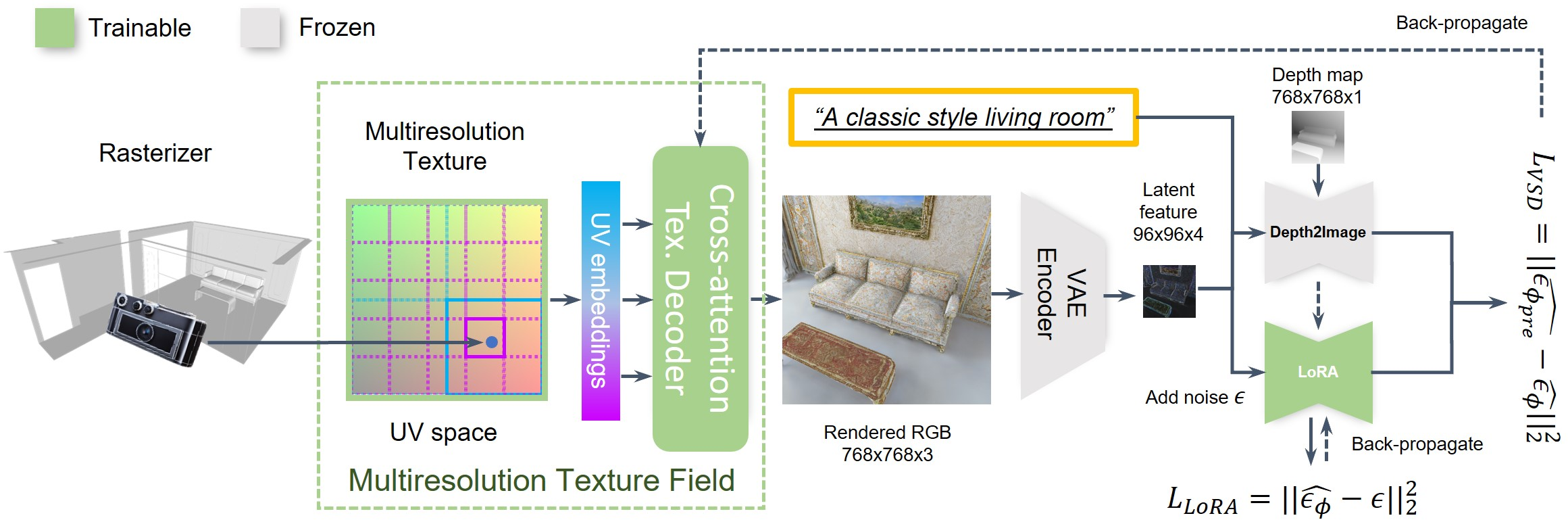
Abstract: We propose SceneTex, a novel method for effectively generating high-quality and style-consistent textures for indoor scenes using depth-to-image diffusion priors. Unlike previous methods that either iteratively warp 2D views onto a mesh surface or distillate diffusion latent features without accurate geometric and style cues, SceneTex formulates the texture synthesis task as an optimization problem in the RGB space where style and geometry consistency are properly reflected. At its core, SceneTex proposes a multiresolution texture field to implicitly encode the mesh appearance. We optimize the target texture via a score-distillation-based objective function in respective RGB renderings. To further secure the style consistency across views, we introduce a cross-attention decoder to predict the RGB values by cross-attending to the pre-sampled reference locations in each instance. SceneTex enables various and accurate texture synthesis for 3D-FRONT scenes, demonstrating significant improvements in visual quality and prompt fidelity over the prior texture generation methods.
- 3davatargan: Bridging domains for personalized editable avatars. In CVPR, 2023.
- Learning representations and generative models for 3d point clouds. In ICML, 2018.
- pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In CVPR, 2021.
- Efficient geometry-aware 3D generative adversarial networks. In CVPR, 2022.
- ScanRefer: 3D object localization in RGB-D scans using natural language. In European Conference on Computer Vision, pages 202–221. Springer, 2020.
- Unit3d: A unified transformer for 3d dense captioning and visual grounding. arXiv preprint arXiv:2212.00836, 2022a.
- D 3 net: A unified speaker-listener architecture for 3d dense captioning and visual grounding. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXII, pages 487–505. Springer, 2022b.
- Text2tex: Text-driven texture synthesis via diffusion models. In ICCV, 2023a.
- Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In ICCV, pages 22246–22256, 2023b.
- Learning to predict 3d objects with an interpolation-based differentiable renderer. 2019.
- Upst-nerf: Universal photorealistic style transfer of neural radiance fields for 3d scene. arXiv preprint arXiv:2208.07059, 2022c.
- Learning implicit fields for generative shape modeling. In CVPR, 2019.
- Scan2cap: Context-aware dense captioning in rgb-d scans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3193–3203, 2021.
- Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. In CVPR, 2023.
- Cross-modal 3d shape generation and manipulation. In ECCV, 2022.
- Stylizing 3d scene via implicit representation and hypernetwork. 2022.
- Spsg: Self-supervised photometric scene generation from rgb-d scans. In CVPR, 2021.
- Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- Diffusion models beat gans on image synthesis. 2021.
- 3d-front: 3d furnished rooms with layouts and semantics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10933–10942, 2021.
- Get3d: A generative model of high quality 3d textured shapes learned from images. In Advances In Neural Information Processing Systems, 2022.
- Image style transfer using convolutional neural networks. In CVPR, 2016.
- Controlling perceptual factors in neural style transfer. In CVPR, 2017.
- Generative adversarial nets. NeurIPS, 2014.
- Stylenerf: A style-based 3d aware generator for high-resolution image synthesis. In ICLR, 2022.
- Instruct-nerf2nerf: Editing 3d scenes with instructions. arXiv preprint arXiv:2303.12789, 2023.
- Denoising diffusion probabilistic models. 2020.
- Cascaded diffusion models for high fidelity image generation. arXiv preprint arXiv:2106.15282, 2021.
- Stylemesh: Style transfer for indoor 3d scene reconstructions. In CVPR, 2022.
- Text2room: Extracting textured 3d meshes from 2d text-to-image models. In ICCV, 2023.
- Unit: Multimodal multitask learning with a unified transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1439–1449, 2021.
- Stylizednerf: consistent 3d scene stylization as stylized nerf via 2d-3d mutual learning. In CVPR, 2022.
- Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.
- Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Magic3d: High-resolution text-to-3d content creation. arXiv preprint arXiv:2211.10440, 2022.
- Infinicity: Infinite-scale city synthesis. In ICCV, 2023.
- Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7708–7717, 2019.
- Diffusion probabilistic models for 3d point cloud generation. In CVPR, 2021.
- Latent-nerf for shape-guided generation of 3d shapes and textures. In CVPR, 2023.
- AutoSDF: Shape priors for 3d completion, reconstruction and generation. In CVPR, 2022.
- Diffrf: Rendering-guided 3d radiance field diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4328–4338, 2023.
- Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG), 41(4):1–15, 2022.
- Improved denoising diffusion probabilistic models. 2021.
- Giraffe: Representing scenes as compositional generative neural feature fields. In CVPR, 2021.
- Automatic differentiation in pytorch. 2017.
- Convolutional generation of textured 3d meshes. 2020.
- Dreamfusion: Text-to-3d using 2d diffusion. In ICLR, 2023.
- Learning transferable visual models from natural language supervision. In ICLR, 2021.
- Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020.
- Texture: Text-guided texturing of 3d shapes. arXiv preprint arXiv:2302.01721, 2023.
- High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Image super-resolution via iterative refinement. IEEE TPAMI, 2022.
- Graf: Generative radiance fields for 3d-aware image synthesis. 2020.
- Unsupervised volumetric animation. In CVPR, 2023a.
- Unsupervised volumetric animation. In CVPR, 2023b.
- Texturify: Generating textures on 3d shape surfaces. In ECCV, 2022.
- Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638–15650, 2022.
- Implicit neural representations with periodic activation functions. Advances in neural information processing systems, 33:7462–7473, 2020.
- 3d generation on imagenet. In ICLR, 2023.
- Improved adversarial systems for 3d object generation and reconstruction. In Conference on Robot Learning, pages 87–96. PMLR, 2017.
- Ldm3d: Latent diffusion model for 3d. arXiv preprint arXiv:2305.10853, 2023.
- Fourier features let networks learn high frequency functions in low dimensional domains. Advances in Neural Information Processing Systems, 33:7537–7547, 2020.
- Mvdiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion. arXiv preprint arXiv:2307.01097, 2023.
- Attention is all you need. 2017.
- Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In CVPR, 2023a.
- OFA: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International Conference on Machine Learning, pages 23318–23340. PMLR, 2022.
- Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. arXiv preprint arXiv:2305.16213, 2023b.
- Learning descriptor networks for 3d shape synthesis and analysis. In CVPR, 2018.
- Discoscene: Spatially disentangled generative radiance fields for controllable 3d-aware scene synthesis. In CVPR, 2023.
- Learning texture generators for 3d shape collections from internet photo sets. In BMVC, 2021.
- Arf: Artistic radiance fields. In ECCV, 2022.
- Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543, 2023.
- Sketch2model: View-aware 3d modeling from single free-hand sketches. In CVPR, 2021.
- 3d shape generation and completion through point-voxel diffusion. In ICCV, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.