OpenVoice: Versatile Instant Voice Cloning
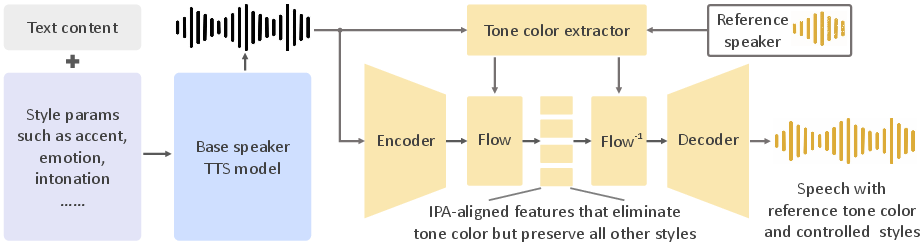
Abstract: We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. OpenVoice has been used by more than 2M users worldwide as the voice engine of MyShell.ai
- I. P. Association. Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet. Cambridge University Press, 1999.
- Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In International Conference on Machine Learning, pages 2709–2720. PMLR, 2022.
- CoquiAI. Xtts taking text-to-speech to the next level. Technical Blog, 2023.
- Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021.
- Glow-tts: A generative flow for text-to-speech via monotonic alignment search. Advances in Neural Information Processing Systems, 33:8067–8077, 2020.
- Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In International Conference on Machine Learning, pages 5530–5540. PMLR, 2021.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:17022–17033, 2020.
- Voicebox: Text-guided multilingual universal speech generation at scale. arXiv preprint arXiv:2306.15687, 2023.
- Freevc: Towards high-quality text-free one-shot voice conversion. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023.
- M. Müller. Dynamic time warping. Information retrieval for music and motion, pages 69–84, 2007.
- Speech resynthesis from discrete disentangled self-supervised representations. arXiv preprint arXiv:2104.00355, 2021.
- D. Rezende and S. Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530–1538. PMLR, 2015.
- P. Senin. Dynamic time warping algorithm review. Information and Computer Science Department University of Hawaii at Manoa Honolulu, USA, 855(1-23):40, 2008.
- A comparison of discrete and soft speech units for improved voice conversion. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6562–6566. IEEE, 2022.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023.
- Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt. arXiv preprint arXiv:2301.13662, 2023.
- Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv preprint arXiv:2303.03926, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.